Как сопоставить только действительные римские цифры с регулярным выражением?
Думая о своей другой проблеме, я решил, что не могу даже создать регулярное выражение, которое будет соответствовать римским цифрам (не говоря уже о контекстно-свободной грамматике, которая будет генерировать их)
Проблема в сопоставлении только действительных римских цифр. Например, 990 это не "XM", это "CMXC"
Моя проблема в создании регулярного выражения для этого заключается в том, что для того, чтобы разрешить или запретить определенные символы, мне нужно оглянуться назад. Давайте возьмем тысячи и сотни, например.
Я могу допустить M{0,2}C?M (чтобы разрешить 900, 1000, 1900, 2000, 2900 и 3000). Однако, если совпадение на CM, я не могу позволить, чтобы следующие символы были C или D (потому что я уже на 900).
Как я могу выразить это в регулярном выражении?
Если это просто невозможно выразить в регулярном выражении, можно ли это выразить в контекстно-свободной грамматике?
18 ответов
Пытаться:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Разбивая это:
M{0,4}
Это определяет раздел тысяч и в основном ограничивает его между 0 а также 4000, Это относительно просто:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
(CM|CD|D?C{0,3})
Чуть более сложный, это для сотен раздел и охватывает все возможности:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
(XC|XL|L?X{0,3})
Те же правила, что и в предыдущем разделе, но для десятки мест:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
(IX|IV|V?I{0,3})
Это раздел единиц, обработка 0 через 9 а также аналогично двум предыдущим разделам (римские цифры, несмотря на их кажущуюся странность, следуют некоторым логическим правилам, как только вы выясните, что они из себя представляют):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
На самом деле, ваша предпосылка ошибочна. 990 IS "XM", а также "CMXC".
Римляне были гораздо меньше озабочены "правилами", чем ваш учитель в третьем классе. Пока все сложилось, все было в порядке. Следовательно, "IIII" был таким же хорошим, как "IV" для 4. И "IIM" был совершенно крут для 998.
(Если у вас есть проблемы с этим... Помните, что английское правописание не было формализовано до 1700-х годов. До тех пор, пока читатель мог понять это, это было достаточно хорошо).
Просто чтобы сохранить его здесь:
(^(?=[MDCLXVI])M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$)
Соответствует всем римским цифрам. Не заботится о пустых строках (требуется хотя бы одна буква римской цифры). Должен работать в PCRE, Perl, Python и Ruby.
Демоверсия Ruby онлайн: http://rubular.com/r/KLPR1zq3Hj
Преобразование в Интернете: http://www.onlineconversion.com/roman_numerals_advanced.htm
Чтобы избежать совпадения с пустой строкой, вам нужно будет повторить шаблон четыре раза и заменить каждый 0 с 1 в свою очередь, и приходится V, L а также D:
(M{1,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|M{0,4}(CM|C?D|D?C{1,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|M{0,4}(CM|CD|D?C{0,3})(XC|X?L|L?X{1,3})(IX|IV|V?I{0,3})|M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|I?V|V?I{1,3}))
В этом случае (потому что этот шаблон использует ^ а также $) вам лучше сначала проверить пустые строки и не сравнивать их. Если вы используете границы слов, то у вас нет проблем, потому что нет такого понятия, как пустое слово. (По крайней мере, регулярное выражение не определяет один; не начинайте философствовать, я здесь прагматичен!)
В моем конкретном (реальном мире) случае мне нужны были цифры совпадений в конце слов, и я не нашел другого пути. Мне нужно было вычеркнуть номера сносок из моего обычного текстового документа, где текст, такой как "Красное море и Большой Барьерный риф cli ", был преобразован в the Red Seacl and the Great Barrier Reefcli, Но у меня все еще были проблемы с правильными словами, такими как Tahiti а также fantastic вымыты в Tahit а также fantasti,
К счастью, диапазон номеров ограничен до 1..3999 или около того. Таким образом, вы можете создать регулярное блюдо.
<opt-thousands-part><opt-hundreds-part><opt-tens-part><opt-units-part>
Каждая из этих частей будет иметь дело с капризами римской нотации. Например, используя запись Perl:
<opt-hundreds-part> = m/(CM|DC{0,3}|CD|C{1,3})?/;
Повторите и соберите.
Добавлено: <opt-hundreds-part> можно сжать дальше:
<opt-hundreds-part> = m/(C[MD]|D?C{0,3})/;
Поскольку предложение "D?C{0,3}" не может ничего соответствовать, знак вопроса не требуется. И, скорее всего, круглые скобки должны быть не захватывающего типа - в Perl:
<opt-hundreds-part> = m/(?:C[MD]|D?C{0,3})/;
Конечно, все должно быть без учета регистра.
Вы также можете расширить это, чтобы иметь дело с опциями, упомянутыми Джеймсом Керраном (чтобы разрешить XM или IM для 990 или 999, и CCCC для 400, и т. Д.).
<opt-hundreds-part> = m/(?:[IXC][MD]|D?C{0,4})/;
import re
pattern = '^M{0,3}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$'
if re.search(pattern, 'XCCMCI'):
print 'Valid Roman'
else:
print 'Not valid Roman'
Для людей, которые действительно хотят понять логику, пожалуйста, ознакомьтесь с пошаговым объяснением на 3 страницах по diveintopython.
Единственное отличие от оригинального решения (которое было M{0,4}) потому что я обнаружил, что "ММММ" не является действительной римской цифрой (также, вероятно, старые римляне не думали об этом огромном числе и не согласятся со мной). Если вы один из неприличных старых римлян, пожалуйста, простите меня и используйте версию {0,4}.
В моем случае я пытался найти и заменить все вхождения римских чисел одним словом в тексте, поэтому я не мог использовать начало и конец строк. Таким образом, решение @paxdiablo нашло много совпадений нулевой длины. Я закончил со следующим выражением:
(?=\b[MCDXLVI]{1,6}\b)M{0,4}(?:CM|CD|D?C{0,3})(?:XC|XL|L?X{0,3})(?:IX|IV|V?I{0,3})
Мой окончательный код Python был таким:
import re
text = "RULES OF LIFE: I. STAY CURIOUS; II. NEVER STOP LEARNING"
text = re.sub(r'(?=\b[MCDXLVI]{1,6}\b)M{0,4}(?:CM|CD|D?C{0,3})(?:XC|XL|L?X{0,3})(?:IX|IV|V?I{0,3})', 'ROMAN', text)
print(text)
Выход:
RULES OF LIFE: ROMAN. STAY CURIOUS; ROMAN. NEVER STOP LEARNING
Некоторые действительно удивительные ответы здесь, но ни один из них не подходит для меня, так как мне нужно было иметь возможность сопоставлять только допустимые римские цифры в строке без сопоставления пустых строк и сопоставлять только цифры, которые сами по себе (т.е. не внутри слова).
Позвольте представить вам строгое выражение современных римских цифр Рейли :
^(?=[MDCLXVI])M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$
Из коробки это было довольно близко к тому, что мне нужно, но оно будет соответствовать только отдельным римским цифрам, а при изменении для соответствия в строке оно будет соответствовать пустым строкам в определенных точках (где слово начинается с заглавной буквы V, M и т. д.) и также даст частичное совпадение недопустимых римских цифр, таких как MMLLVVDD, XXLLVVDD, MMMMDLVX, XVXDLMM и MMMCCMLXXV.
Итак, после небольшой модификации я получил следующее:
(?<![MDCLXVI])(?=[MDCLXVI])M{0,3}(?:C[MD]|D?C{0,3})(?:X[CL]|L?X{0,3})(?:I[XV]|V?I{0,3})[^ ]\b
Добавленный отрицательный просмотр назад гарантирует, что он не выполняет частичные совпадения с недопустимыми римскими цифрами и блокирует первую M до 3, поскольку это самое высокое значение, которое она имеет в стандартной форме римских цифр .
На данный момент это единственное регулярное выражение, которое проходит мой обширный тестовый набор из более чем 4000 тестов, включая все возможные римские цифры от 1 до 3999, римские цифры в строках и недопустимые римские цифры, подобные тем, которые я упомянул выше.
Вот скриншот в действии с https://regex101.com/: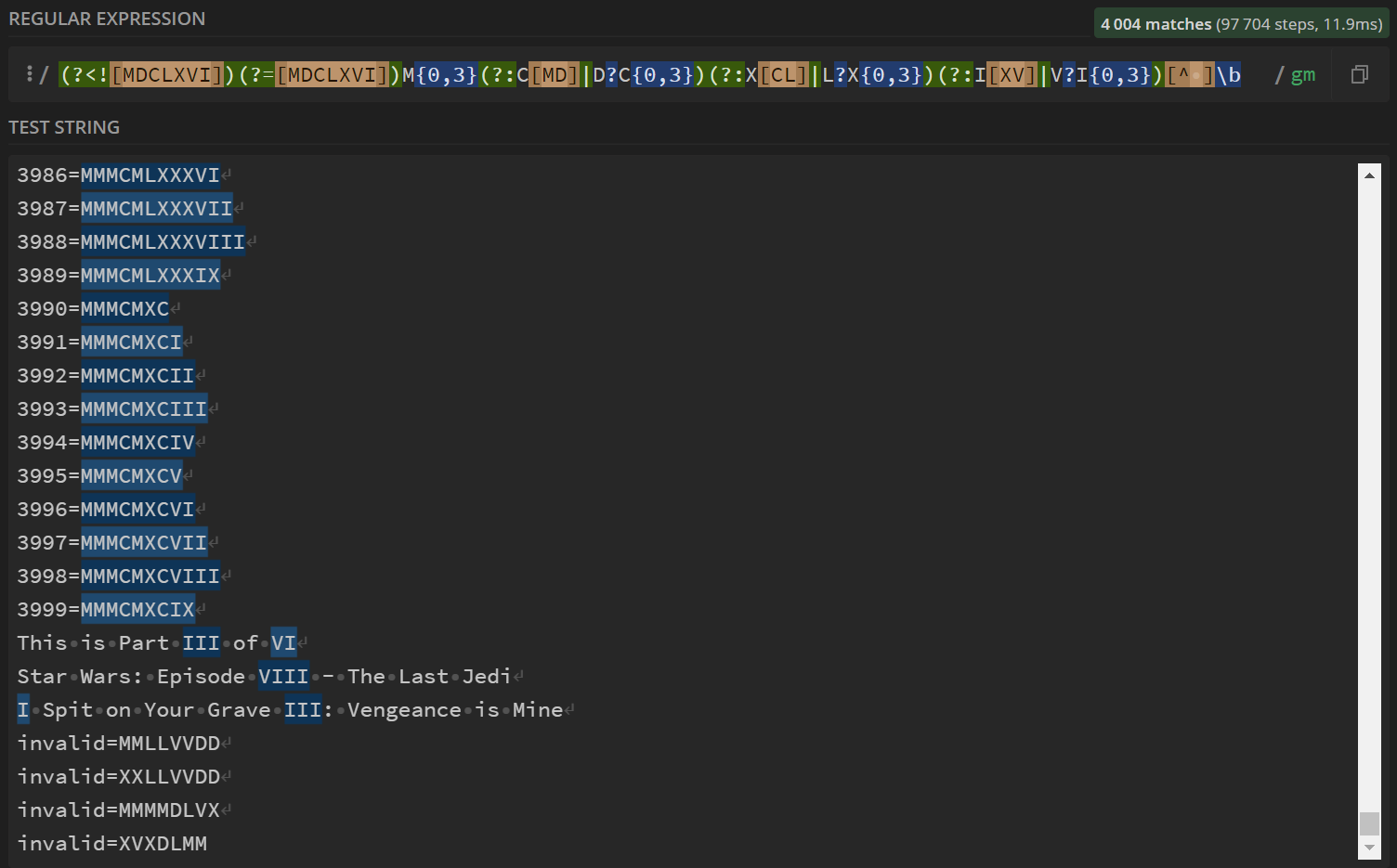
Я видел несколько ответов, которые не охватывают пустые строки и не используют опережающие поиски для решения этой проблемы. И я хочу добавить новый ответ, который охватывает пустые строки и не использует опережающий просмотр. Регулярное выражение следующее:
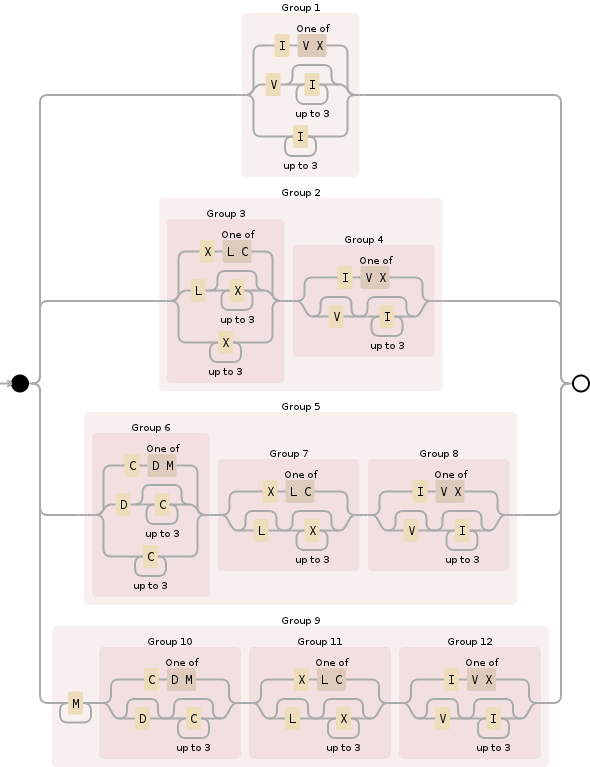
^(I[VX]|VI{0,3}|I{1,3})|((X[LC]|LX{0,3}|X{1,3})(I[VX]|V?I{0,3}))|((C[DM]|DC{0,3}|C{1,3})(X[LC]|L?X{0,3})(I[VX]|V?I{0,3}))|(M+(C[DM]|D?C{0,3})(X[LC]|L?X{0,3})(I[VX]|V?I{0,3}))$
Я позволяю бесконечное M, с M+ но, конечно, кто-то может поменять на M{1,4} разрешить только 1 или 4 при желании.
Ниже представлена визуализация, помогающая понять, что он делает, которой предшествуют две онлайн-демонстрации:
Я отвечаю на этот вопрос " Регулярное выражение в Python для римских цифр" здесь,
потому что оно было отмечено как точная копия этого вопроса.
Он может быть похожим по названию, но это конкретный вопрос / проблема с регулярным выражением,
как видно из этого ответа на этот вопрос.
Искомые элементы могут быть объединены в одно чередование, а затем
заключены в группу захвата, которая будет помещена в список с помощью функции findall()
.
Делается это так:
>>> import re
>>> target = (
... r"this should pass v" + "\n"
... r"this is a test iii" + "\n"
... )
>>>
>>> re.findall( r"(?m)\s(i{1,3}v*|v)$", target )
['v', 'iii']
Модификации регулярного выражения для факторизации и захвата только цифр заключаются в следующем:
(?m)
\s
( # (1 start)
i{1,3}
v*
| v
) # (1 end)
$
Как Джереми и Пакс указывали выше... '^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$'должно быть решением, которое вы ищете...
Конкретный URL, который должен был быть прикреплен (IMHO): http://thehazeltree.org/diveintopython/7.html
Пример 7.8 - это краткая форма с использованием {n, m}
Следующее выражение помогло мне проверить римское число.
^M{0,4}(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$
Вот,
M{0,4}будет соответствовать тысячамC[MD]|D?C{0,3}будет соответствовать сотнямX[CL]|L?X{0,3}будет соответствовать десяткамI[XV]|V?I{0,3}будет соответствовать единицам
Ниже представлена визуализация, которая помогает понять, что она делает, и ей предшествуют две онлайн-демонстрации:
Код Python:
import re
regex = re.compile("^M{0,4}(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$")
matchArray = regex.match("MMMCMXCIX")
Позитивный взгляд фоновый и упреждающий предложил @paxdiablo для того, чтобы избежать соответствующих пустых строк, кажется, не работают для меня.
Я исправил это, используя вместо этого отрицательный прогноз:
(?!$)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})
NB: если вы добавите что-то (например, "foobar" в конце регулярного выражения, то, очевидно, вам придется заменить
(?!$) по
(?!f) (где
f является первым символом "foobar").
Стивен Левитан использует это регулярное выражение в своем посте, который проверяет римские цифры перед тем, как "дероманизировать" значение:
/^M*(?:D?C{0,3}|C[MD])(?:L?X{0,3}|X[CL])(?:V?I{0,3}|I[XV])$/
надеюсь, что это правильно - для этого требуется только самая базовая версия ERE ...
... если вы не против, чтобы это также соответствовало пустой строке, т.е.str == ""
/^M*(D?C(CC?)?|C?[DM])?(L?X(XX?)?|X?[LC])?(V?I(II?)?|I?[VX])?$/
Это работает в механизмах регулярных выражений Java и PCRE и теперь должно работать в последней версии JavaScript, но может работать не во всех контекстах.
(?<![A-Z])(M*(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3}))(?![A-Z])
Первая часть - это ужасный негативный взгляд назад. Но для логических целей это легче всего понять. В основном первый(?<!) говорит, что не соответствует середине ([MATCH]) если до середины идут буквы ([MATCH]) и последнее (?!) говорит, что не соответствует середине ([MATCH]) если после него идут письма.
Середина ([MATCH])- это просто наиболее часто используемое регулярное выражение для сопоставления последовательности римских цифр. Но теперь вы не хотите, чтобы это совпадало, если вокруг него есть какие-то буквы.
Посмотреть на себя.https://regexr.com/4vce5
Я бы написал функции для моей работы для меня. Вот две функции римской цифры в PowerShell.
function ConvertFrom-RomanNumeral
{
<#
.SYNOPSIS
Converts a Roman numeral to a number.
.DESCRIPTION
Converts a Roman numeral - in the range of I..MMMCMXCIX - to a number.
.EXAMPLE
ConvertFrom-RomanNumeral -Numeral MMXIV
.EXAMPLE
"MMXIV" | ConvertFrom-RomanNumeral
#>
[CmdletBinding()]
[OutputType([int])]
Param
(
[Parameter(Mandatory=$true,
HelpMessage="Enter a roman numeral in the range I..MMMCMXCIX",
ValueFromPipeline=$true,
Position=0)]
[ValidatePattern("^M{0,3}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$")]
[string]
$Numeral
)
Begin
{
$RomanToDecimal = [ordered]@{
M = 1000
CM = 900
D = 500
CD = 400
C = 100
XC = 90
L = 50
X = 10
IX = 9
V = 5
IV = 4
I = 1
}
}
Process
{
$roman = $Numeral + " "
$value = 0
do
{
foreach ($key in $RomanToDecimal.Keys)
{
if ($key.Length -eq 1)
{
if ($key -match $roman.Substring(0,1))
{
$value += $RomanToDecimal.$key
$roman = $roman.Substring(1)
break
}
}
else
{
if ($key -match $roman.Substring(0,2))
{
$value += $RomanToDecimal.$key
$roman = $roman.Substring(2)
break
}
}
}
}
until ($roman -eq " ")
$value
}
End
{
}
}
function ConvertTo-RomanNumeral
{
<#
.SYNOPSIS
Converts a number to a Roman numeral.
.DESCRIPTION
Converts a number - in the range of 1 to 3,999 - to a Roman numeral.
.EXAMPLE
ConvertTo-RomanNumeral -Number (Get-Date).Year
.EXAMPLE
(Get-Date).Year | ConvertTo-RomanNumeral
#>
[CmdletBinding()]
[OutputType([string])]
Param
(
[Parameter(Mandatory=$true,
HelpMessage="Enter an integer in the range 1 to 3,999",
ValueFromPipeline=$true,
Position=0)]
[ValidateRange(1,3999)]
[int]
$Number
)
Begin
{
$DecimalToRoman = @{
Ones = "","I","II","III","IV","V","VI","VII","VIII","IX";
Tens = "","X","XX","XXX","XL","L","LX","LXX","LXXX","XC";
Hundreds = "","C","CC","CCC","CD","D","DC","DCC","DCCC","CM";
Thousands = "","M","MM","MMM"
}
$column = @{Thousands = 0; Hundreds = 1; Tens = 2; Ones = 3}
}
Process
{
[int[]]$digits = $Number.ToString().PadLeft(4,"0").ToCharArray() |
ForEach-Object { [Char]::GetNumericValue($_) }
$RomanNumeral = ""
$RomanNumeral += $DecimalToRoman.Thousands[$digits[$column.Thousands]]
$RomanNumeral += $DecimalToRoman.Hundreds[$digits[$column.Hundreds]]
$RomanNumeral += $DecimalToRoman.Tens[$digits[$column.Tens]]
$RomanNumeral += $DecimalToRoman.Ones[$digits[$column.Ones]]
$RomanNumeral
}
End
{
}
}
Проблема решения от Джереми и Пакса состоит в том, что оно также соответствует "ничему".
Следующее регулярное выражение ожидает по крайней мере одну римскую цифру:
^(M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|[IDCXMLV])$