Почему GRO более эффективен?
Generic Receive Offload (GRO) - это программный метод в Linux, объединяющий несколько входящих пакетов, принадлежащих одному потоку. В связанной статье утверждается, что загрузка ЦП снижается, поскольку вместо каждого пакета, проходящего через сетевой стек индивидуально, один агрегированный пакет проходит через сетевой стек.
Однако, если взглянуть на исходный код GRO, это выглядит как сетевой стек сам по себе. Например, входящий пакет TCP/IPv4 должен пройти:
eth_gro_receiveinet_gro_receivetcp_gro_receive
Каждая функция выполняет декапсуляцию и просматривает соответствующие заголовки кадра / сети / транспорта, как и следовало ожидать от "обычного" сетевого стека.
Предполагая, что машина не выполняет брандмауэр /NAT или другую явно дорогостоящую обработку для каждого пакета, что такого медленного в "обычном" сетевом стеке, что "сетевой стек GRO" может ускориться?
1 ответ
Краткий ответ: GRO выполняется очень рано в потоке приема, поэтому он в основном сокращает количество операций на ~(размер сеанса GRO / MTU).
Более подробно: наиболее распространенная функция GRO - это napi_gro_receive (). Он используется 93 раза (в ядре 4.14) почти всеми сетевыми драйверами. Используя GRO на уровне NAPI, драйвер выполняет агрегацию для большого SKB очень рано, прямо в обработчике завершения приема. Это означает, что все последующие функции в стеке приема выполняют намного меньше обработки.
Вот хорошее визуальное представление потока RX для сетевой карты Mellanox ConnectX-4Lx (извините, к этому у меня есть доступ): 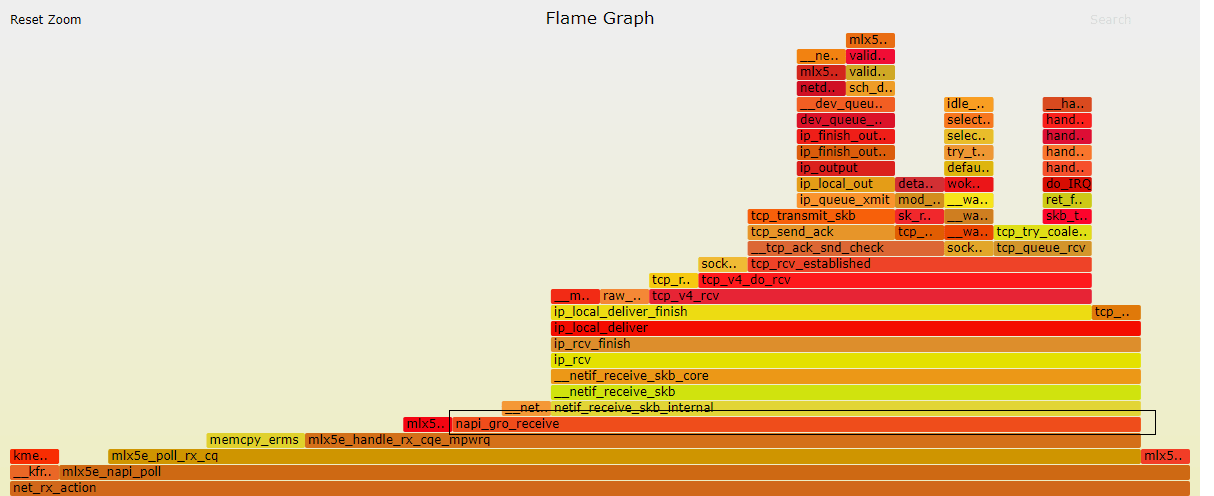
Как видите, агрегация GRO находится в самом низу стека вызовов. Вы также можете увидеть, сколько работы сделано после. Представьте, сколько будет накладных расходов, если каждая из этих функций будет работать на одном MTU.
Надеюсь это поможет.