Лучше иметь одну большую паркетную пилку или много меньших паркетных пилок?
Я понимаю, что hdfs будет разбивать файлы на что-то вроде кусков по 64 Мб. У нас есть данные, поступающие в потоковом режиме, и мы можем хранить их в больших файлах или файлах среднего размера. Каков оптимальный размер для хранения файлов по столбцам? Если я смогу хранить файлы там, где наименьший столбец составляет 64 МБ, сэкономит ли это какое-то время вычислений по сравнению, например, с файлами 1 ГБ?
1 ответ
Цель около 1 ГБ на файл (спарк раздел) (1).
В идеале вы должны использовать сжатие snappy (по умолчанию), потому что сжатые сжатые файлы паркета разделяются (2).
Использование snappy вместо gzip значительно увеличит размер файла, поэтому, если пространство для хранения является проблемой, это необходимо учитывать.
.option("compression", "gzip") это опция для переопределения сжатия snappy по умолчанию.
Если вам необходимо изменить размер / перераспределить набор данных /DataFrame/RDD, позвоните в .coalesce(<num_partitions> или худший случай .repartition(<num_partitions>) функция. Предупреждение: особенно перераспределение, а также слияние может привести к перестановке данных, поэтому используйте их с некоторой осторожностью.
Кроме того, размер файла паркета и в этом отношении все файлы, как правило, должны быть больше, чем размер блока HDFS (по умолчанию 128 МБ).
1) https://forums.databricks.com/questions/101/what-is-an-optimal-size-for-file-partitions-using.html2) http://boristyukin.com/is-snappy-compressed-parquet-file-splittable/
Обратите внимание, что файлы Parquet внутренне разделены на row groups
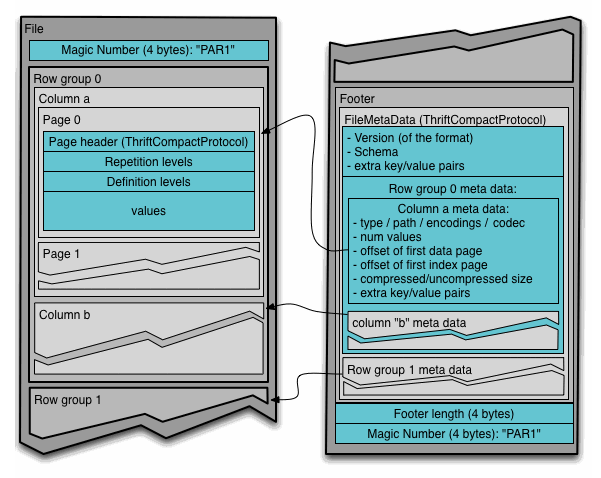
https://parquet.apache.org/documentation/latest/
Таким образом, увеличивая размер паркетных файлов, группы строк могут оставаться такими же, если ваши базовые паркетные файлы не были маленькими / крошечными. Нет огромных прямых штрафов на обработку, но напротив, у читателей больше возможностей воспользоваться преимуществами, возможно, больших / более оптимальных групп строк, если ваши паркетные файлы были меньше / крошечными, например, поскольку группы строк не могут охватывать несколько паркетных файлов.
Также паркетные файлы большего размера не ограничивают параллелизм считывателей, так как каждый паркетный файл можно логически разбить на несколько splits (состоящий из одной или нескольких групп строк).
Единственный недостаток больших паркетных пилок - для их создания требуется больше памяти. Так что вы можете быть осторожны, если вам нужно увеличить память исполнителей Spark.
row groups- это способ вертикального разбиения файлов Parquet. Каждыйrow group имеет много блоков строк (по одному на каждый столбец, что позволяет обеспечить горизонтальное разбиение наборов данных в паркете).