Построение гистограммы с использованием python и quickdraw
Мне нужна помощь в написании программы, которая читает около 300 строк из текстового файла и берет оценки из определенного задания (столбец A1), а затем использует оценки из этого задания для построения гистограммы в режиме быстрого рисования.
ID , Last, First, Lecture, Tutorial, A1, A2, A3, A4, A5
8959079, Moore, Maria, L01, T03, 9.0, 8.5, 8.5, 10.0, 8.5
4295498, Taylor, John, L00, T04, 10.0, 6.5, 8.5, 9.5, 7.0
9326386, Taylor, David, L00, T00, 9.5, 8.0, 8.0, 9.0, 10.0
7223234, Taylor, James, L01, T03, 8.5, 5.5, 10.0, 0.0, 0.5
7547838, Miller, Robert, L01, T09, 7.0, 8.0, 8.5, 10.0, 0.5
0313453, Lee, James, L01, T01, 10.0, 0.5, 8.0, 7.0, 5.0
3544072, Lee, Helen, L00, T03, 10.0, 9.0, 7.0, 9.0, 8.5
Пока у меня есть код, который извлекает оценки из файла (А1) и помещает его в список, а затем создает другой, который подсчитывает, сколько случаев происходит с определенной оценкой. У меня возникли проблемы с использованием этого списка и вводом его в quickdraw для построения гистограммы?
def file():
file = open('sample_input_1.txt', 'r')
col = [] data = file.readlines()
for i in range(1,len(data)-1):
col.append(int(float(data[i].split(',')[5])))
return col
def hist(col):
grades = []
for i in range(11):
grades.append(0)
for i in (col):
grades[i] += 1
return grades
col = file()
grades = hist(col)
print(col)
print(grades)
2 ответа
Quickdraw не поддерживает рисование графиков из коробки, все прямоугольники, сетка, текст должен отображаться самостоятельно. Гораздо лучший способ - использовать уже существующую библиотеку Python. Не пытайтесь изобретать велосипед.
Пример 1 Решение Quickdraw
#!/bin/python
# Quickdraw histogram:
# Assume max grade is 10
A1 = [9.0,10.0,9.5,8.5,7.0,10.0,10.0]
histogram = []
for i in sorted(set(A1)): histogram.append([int(i*50),A1.count(i)])
gridsize = 500
griddiv = 20
topleft = 50
#graph title
print 'text', '"','Histogram of Grades','"', 220, 25
#x axis title
for i in range(1,21):
print 'text', '"',float(i)/2,'"', (i+1)*25, 570
#y axix title
for i in range(0,11):
print 'text', '"',i,'"', 25, 600-(i+1)*50
#grid
print 'grid', topleft, topleft, gridsize, gridsize, griddiv, griddiv
#chart rectangles
print 'color 140 0 0'
for i in histogram:
print 'fillrect',i[0]-25+topleft, gridsize-(50*i[1])+topleft,gridsize/griddiv,50*i[1],'b'+str(i[0])
print 'fillrect', 'color','b'+str(i[0])
Вот как выглядит график после запуска histogram.py | java -jar quickdraw.jar это не красиво!

Это решение действительно ужасно. Код по своей сути неаккуратен (я, безусловно, многое мог бы сделать, чтобы улучшить как удобочитаемость, так и гибкость, но в любом случае это подтверждает концепцию). Масштабирование не является ручкой, что вам понадобится, так как при 300 записях учеников количество в классе будет больше 10. Не говоря уже о том, что это выглядит ужасно. Это можно улучшить, например, нарисовав белые линии вокруг каждого прямоугольника, это будет небольшим улучшением, но вам нужно будет выполнить все вычисления.
Пример 2. Раствор MATPLOTLIB.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
# You already have A1 from the file in a list like this:
A1 = [9.0,10.0,9.5,8.5,7.0,10.0,10.0]
#Set up infomation about histogram and plot using A1
fig = plt.figure()
ax = fig.add_subplot(111)
ax.hist(A1, 12,facecolor='red')
ax.set_title('Grade Histogram')
ax.set_xlabel('Grade')
ax.set_ylabel('Count')
ax.set_xlim(min(A1)-0.5, max(A1)+0.5)
ax.set_ylim(0, max([A1.count(i) for i in sorted(set(A1))])+0.5)
ax.grid(True)
plt.show()
Выход:
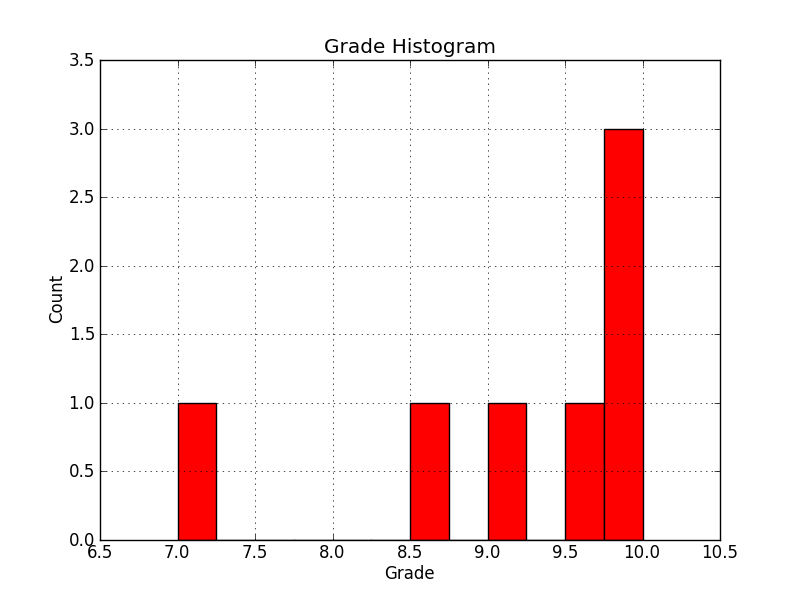
Это лучшее решение, масштабирование обрабатывается и график выглядит превосходно.
Пример 3 Простой CLI
Я бы даже сделал шаг назад и сделал бы простую версию CLI, не пытайтесь запустить до того, как вы не сможете ходить.
A1 = [9.0,10.0,9.5,8.5,7.0,10.0,10.0]
upper =2*int(max(A1))+1
lower =2*int(min(A1))-1
for i in [x * 0.5 for x in range(lower,upper)]:
print i,'\t|' ,'*'*A1.count(i)
Выход:
Grade Histogram
6.5 |
7.0 | *
7.5 |
8.0 |
8.5 | *
9.0 | *
9.5 | *
10.0 | ***
Это решение - отличное начало для начинающих программистов! Это просто, чисто и даже масштабирование не должно быть проблемой (просто увеличьте ширину окна терминала, если столбцы становятся длинными).
Как насчет этого, чтобы вы пошли?
s = """ID , Last, First, Lecture, Tutorial, A1, A2, A3, A4, A5
8959079, Moore, Maria, L01, T03, 9.0, 8.5, 8.5, 10.0, 8.5
4295498, Taylor, John, L00, T04, 10.0, 6.5, 8.5, 9.5, 7.0
9326386, Taylor, David, L00, T00, 9.5, 8.0, 8.0, 9.0, 10.0
7223234, Taylor, James, L01, T03, 8.5, 5.5, 10.0, 0.0, 0.5
7547838, Miller, Robert, L01, T09, 7.0, 8.0, 8.5, 10.0, 0.5
0313453, Lee, James, L01, T01, 10.0, 0.5, 8.0, 7.0, 5.0
3544072, Lee, Helen, L00, T03, 10.0, 9.0, 7.0, 9.0, 8.5"""
from StringIO import StringIO
c = StringIO(s)
a = loadtxt(c, delimiter=',', dtype='S8')
A1 = a[1:, 5].astype('float32')
print A1
hist(A1, bins=10)
Выход:
[ 9. 10. 9.5 8.5 7. 10. 10. ]
Out[81]:
(array([1, 0, 0, 0, 0, 1, 1, 0, 1, 3]),
array([ 7. , 7.3, 7.6, 7.9, 8.2, 8.5, 8.8, 9.1, 9.4,
9.7, 10. ]),

Первый список - это вывод A1, в котором я немного обработал передачу поплавков в hist, hist является функцией matplotlib, которая печатает значения гистограммы и ребра соответственно.