Использование PyTesser, чтобы сломать легкую капчу
Я использую PyTesser сломать captcha, PyTesser использует tesseract библиотека python ocr. Прежде чем поместить изображение в PyTesser, я использую некоторую фильтрацию. Шаг за шагом мой код: входное изображение: 
from PIL import Image
img = Image.open('1.gif')
img = img.convert("RGBA")
pixdata = img.load()
# Clean the background noise, if color != black, then set to white.
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][0] < 90:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][2] < 136:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][3] > 0:
pixdata[x, y] = (255, 255, 255, 255)
img.save("input-black.gif", "GIF")
После применения этого кода вывод будет:
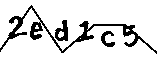
Сейчас,
im_orig = Image.open('input-black.gif')
big = im_orig.resize((116, 56), Image.NEAREST)
ext = ".tif"
big.save("input-NEAREST" + ext)
После этого фрагмента кода выходное изображение выглядит так:
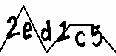
И наконец, когда я применяю это
from pytesser import *
image = Image.open('input-NEAREST.tif')
print image_to_string(image)
Я получаю вывод %/ww
Пожалуйста, помогите мне найти правильный результат.
Если я попытаюсь с этими изображениями, этот код может успешно распознавать буквы.

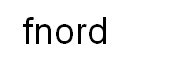
1 ответ
Вам необходимо выполнить некоторые основные морфологические операции с изображениями, чтобы удалить строку перед выполнением распознавателя капчи. Попробуйте объединить ndimage.binary_erosion и ndimage.binary_dilation .