Построение распределения Zipf с помощью matplotlib, FITTED-LINE
У меня есть список абзацев, где я хочу запустить распределение zipf по их комбинации.
Мой код ниже:
from itertools import *
from pylab import *
from collections import Counter
import matplotlib.pyplot as plt
paragraphs = " ".join(targeted_paragraphs)
for paragraph in paragraphs:
frequency = Counter(paragraph.split())
counts = array(frequency.values())
tokens = frequency.keys()
ranks = arange(1, len(counts)+1)
indices = argsort(-counts)
frequencies = counts[indices]
loglog(ranks, frequencies, marker=".")
title("Zipf plot for Combined Article Paragraphs")
xlabel("Frequency Rank of Token")
ylabel("Absolute Frequency of Token")
grid(True)
for n in list(logspace(-0.5, log10(len(counts)-1), 20).astype(int)):
dummy = text(ranks[n], frequencies[n], " " + tokens[indices[n]],
verticalalignment="bottom",
horizontalalignment="left")
ЦЕЛЬ Я пытаюсь нарисовать "подобранную линию" на этом графике и присвоить ее значение переменной. Однако я не знаю, как добавить это. Любая помощь будет высоко ценится по обоим этим вопросам.
1 ответ
Я знаю, что прошло много времени с тех пор, как был задан этот вопрос. Тем не менее, я нашел возможное решение этой проблемы на сайте scipy.
Я думал, что я отправлю здесь, если кто-то еще требуется.
У меня не было информации о параграфе, так что вот взбил dict называется frequency это имеет вхождение в качестве своих значений.
Затем мы получаем его значения и конвертируем в массив numy. определять zipf distribution parameter который должен быть>1.
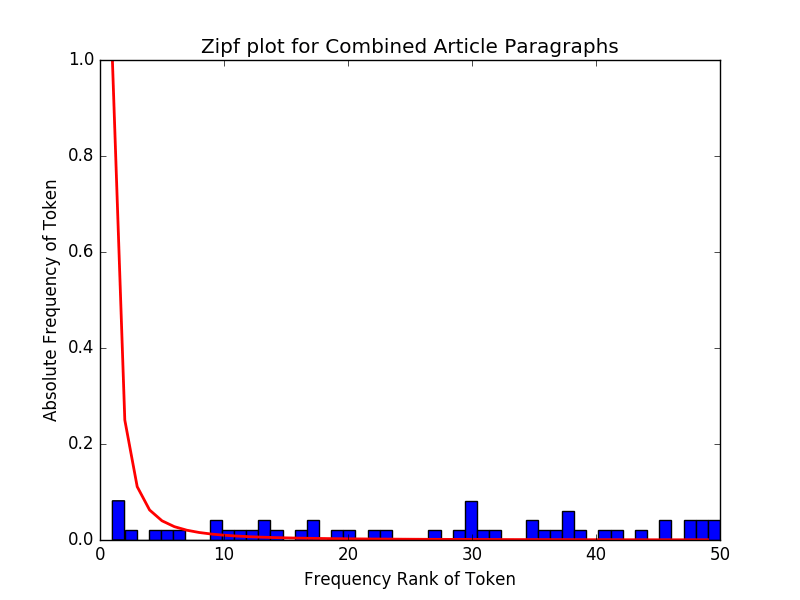
Наконец, отобразите гистограмму выборок вместе с функцией плотности вероятности.
Рабочий код:
import random
import matplotlib.pyplot as plt
from scipy import special
import numpy as np
#Generate sample dict with random value to simulate paragraph data
frequency = {}
for i,j in enumerate(range(50)):
frequency[i]=random.randint(1,50)
counts = frequency.values()
tokens = frequency.keys()
#Convert counts of values to numpy array
s = np.array(counts)
#define zipf distribution parameter. Has to be >1
a = 2.
# Display the histogram of the samples,
#along with the probability density function
count, bins, ignored = plt.hist(s, 50, normed=True)
plt.title("Zipf plot for Combined Article Paragraphs")
x = np.arange(1., 50.)
plt.xlabel("Frequency Rank of Token")
y = x**(-a) / special.zetac(a)
plt.ylabel("Absolute Frequency of Token")
plt.plot(x, y/max(y), linewidth=2, color='r')
plt.show()
участок