Что такое кросс-энтропия?
Я знаю, что есть много объяснений того, что cross-entropy есть, но я все еще в замешательстве.
Это только метод для описания функции потерь? Затем мы можем использовать, например, алгоритм градиентного спуска, чтобы найти минимум. Или весь процесс включает в себя также поиск минимального алгоритма?
1 ответ
Кросс-энтропия обычно используется для количественной оценки разницы между двумя распределениями вероятностей. Обычно "истинное" распределение (которое пытается сопоставить алгоритм вашего машинного обучения) выражается в терминах одноразового распределения.
Например, предположим, что для конкретного обучающего экземпляра метка является B (из возможных меток A, B и C). Поэтому горячая раздача для этого учебного экземпляра:
Pr(Class A) Pr(Class B) Pr(Class C)
0.0 1.0 0.0
Вы можете интерпретировать вышеупомянутое "истинное" распределение как означающее, что у обучающего экземпляра вероятность 0% быть классом A, 100% вероятность быть классом B и 0% вероятность быть классом C.
Теперь предположим, что ваш алгоритм машинного обучения предсказывает следующее распределение вероятностей:
Pr(Class A) Pr(Class B) Pr(Class C)
0.228 0.619 0.153
Насколько близко прогнозируемое распределение к истинному распределению? Это то, что определяет потеря перекрестной энтропии. Используйте эту формулу:

куда p(x) желаемая вероятность, и q(x) фактическая вероятность. Сумма по трем классам A, B и C. В этом случае потеря составляет 0,479:
H = - (0.0*ln(0.228) + 1.0*ln(0.619) + 0.0*ln(0.153)) = 0.479
Так вот, насколько "неправильным" или "далеким" является ваше предсказание от истинного распределения.
Кросс-энтропия - одна из многих возможных функций потерь (другая популярная функция - потеря шарниров SVM). Эти функции потерь обычно записываются как J(тета) и могут использоваться в градиентном спуске, который представляет собой итеративную структуру перемещения параметров (или коэффициентов) к оптимальным значениям. В приведенном ниже уравнении вы должны заменить J(theta) с H(p, q), Но учтите, что вам нужно вычислить производную H(p, q) относительно параметров в первую очередь.

Итак, чтобы ответить на ваши оригинальные вопросы напрямую:
Это только метод для описания функции потерь?
Правильная перекрестная энтропия описывает потерю между двумя вероятностными распределениями. Это одна из многих возможных функций потерь.
Тогда мы можем использовать, например, алгоритм градиентного спуска, чтобы найти минимум.
Да, функция кросс-энтропийной потери может использоваться как часть градиентного спуска.
Дальнейшее чтение: один из моих других ответов, связанных с TensorFlow.
Короче говоря, кросс-энтропия (CE) - это мера того, насколько далеко ваше предсказанное значение от истинной метки.
Крест здесь относится к вычислению энтропии между двумя или более функциями / истинными метками (например, 0, 1).
И сам термин энтропия относится к случайности, поэтому его большое значение означает, что ваш прогноз далек от реальных ярлыков.
Таким образом, веса изменяются для уменьшения CE и, таким образом, в конечном итоге приводит к уменьшению разницы между прогнозируемыми и истинными метками и, следовательно, к большей точности.
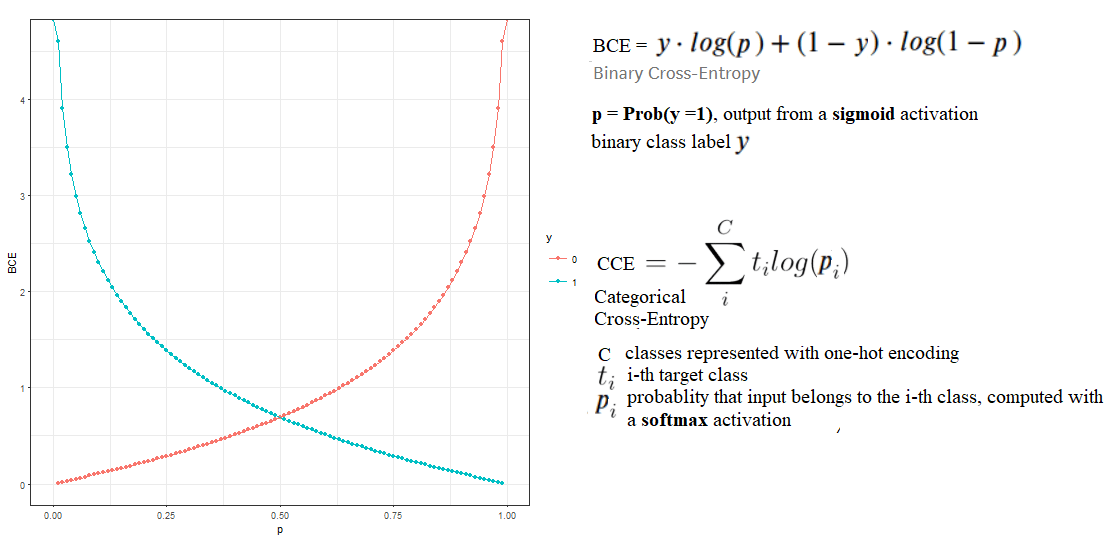
В дополнение к вышеупомянутым сообщениям, простейшая форма кросс-энтропийной потери известна как двоичная кросс-энтропия (используется как функция потерь для двоичной классификации, например, с логистической регрессией), тогда как обобщенная версия является категориальной кросс-энтропией (используется как функция потерь для задач мультиклассовой классификации, например, с нейронными сетями).
Идея осталась прежней:
когда рассчитанная моделью (softmax) вероятность класса становится близкой к 1 для целевой метки для обучающего экземпляра (представленного с одним горячим кодированием, например), соответствующие потери CCE уменьшаются до нуля
в противном случае он увеличивается по мере того, как прогнозируемая вероятность, соответствующая целевому классу, становится меньше.
Следующий рисунок демонстрирует концепцию (обратите внимание на рисунок, что BCE становится низким, когда оба y и p являются высокими или оба они одновременно низкие, т. Е. Есть согласие):
Кросс-энтропия тесно связана с относительной энтропией или KL-дивергенцией, которая вычисляет расстояние между двумя распределениями вероятностей. Например, между двумя дискретными PMFS соотношение между ними показано на следующем рисунке: