Время между запуском ядра и выполнением ядра
Я пытаюсь оптимизировать свою программу CUDA, используя версию Parallel Nsight 2.1 для VS 2010.
Моя программа работает на Windows 7 (32-битной) машине с платой GTX 480. Я установил 32-битный инструментарий CUDA 4.1 и драйвер 301.32.
Один цикл в программе состоит из копирования данных хоста на устройство, выполнения ядер и копирования результатов с устройства на хост.
Как вы можете видеть на картинке результатов профилировщика ниже, ядра работают в четырех разных потоках. Ядро в каждом потоке полагается на данные, скопированные на устройство в "потоке 2". Вот почему asyncMemcpy синхронизируется с процессором перед запуском ядер в разных потоках.
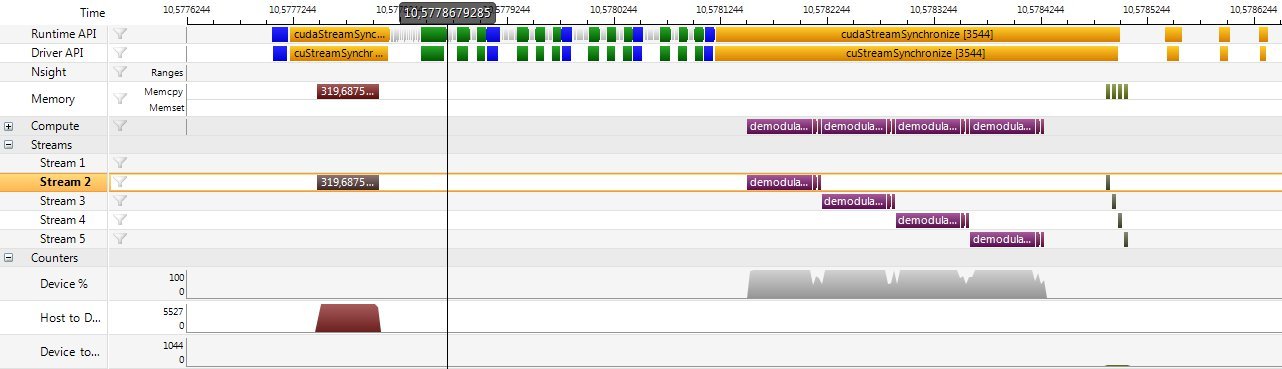
Что меня раздражает на картинке, так это большой разрыв между окончанием первого запуска ядра (в 10.5778679285) и началом выполнения ядра (в 10.5781500). На запуск ядра уходит около 300 долларов, что приводит к огромным накладным расходам в цикле обработки менее 1 мс.
Более того, нет никакого дублирования выполнения ядра и копирования данных результатов обратно на хост, что еще больше увеличивает издержки.
Есть ли очевидные причины для такого поведения?
1 ответ
Есть три проблемы, которые я могу сказать по следу.
Nsight CUDA Analysis добавляет около 1 мкс на вызов API. У вас включены как среда выполнения CUDA, так и трассировка API драйвера CUDA. Если бы вы отключили трассировку CUDA, я бы предположил, что вы бы сократили ширину на 50 мкс.
Поскольку вы работаете на GTX 480 в Windows 7, вы выполняете модель драйвера WDDM. В WDDM драйвер должен выполнить вызов ядра, чтобы передать работу, которая вносит много накладных расходов. Чтобы избежать этих издержек, драйвер CUDA буферизует запросы во внутренней очереди программного обеспечения и отправляет запросы драйверу, когда очередь заполнена, и он сбрасывается вызовом синхронизации. Можно использовать cudaEventQuery, чтобы драйвер сбрасывал работу, но это может иметь и другие последствия для производительности.
Похоже, что вы в первый раз отправляете свою работу в потоки. На устройствах с возможностями вычислений 2.x и 3.0 вы получите лучшие результаты, если сначала отправлять потоки. В вашем случае вы можете увидеть пересечение между вашими ядрами.
Скриншот временной шкалы не дает мне достаточной информации, чтобы определить, почему копии памяти запускаются после завершения всех ядер. Учитывая шаблон вызовов API I, вы сможете увидеть передачу, начинающуюся после завершения каждого потока.
Если вы ожидаете завершения всех потоков, вероятно, быстрее выполнить cudaDeviceSynchronize, чем 4 вызова cudaStreamSynchronize.
Следующая версия Nsight будет иметь дополнительные функции, помогающие понять работу очереди программного обеспечения и передачу работы в вычислительный механизм и механизм копирования памяти.