Изменить тип данных столбцов в Pandas
Я хочу преобразовать таблицу, представленную в виде списка списков, в DataFrame Pandas. В качестве чрезвычайно упрощенного примера:
a = [['a', '1.2', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a)
Каков наилучший способ преобразования столбцов в соответствующие типы, в данном случае столбцы 2 и 3 в числа с плавающей точкой? Есть ли способ указать типы при конвертации в DataFrame? Или лучше сначала создать DataFrame, а затем перебрать столбцы, чтобы изменить тип каждого столбца? В идеале я хотел бы сделать это динамически, потому что может быть сотни столбцов, и я не хочу точно указывать, какие столбцы какого типа. Все, что я могу гарантировать, это то, что каждый столбец содержит значения одного типа.
17 ответов
У вас есть три основных варианта для преобразования типов в пандах.
1. to_numeric()
Лучший способ преобразовать один или несколько столбцов DataFrame в числовые значения - это использовать pandas.to_numeric(),
Эта функция попытается изменить нечисловые объекты (например, строки) на целые числа или числа с плавающей запятой, в зависимости от ситуации.
Основное использование
Вход в to_numeric() является Серией или одним столбцом DataFrame.
>>> s = pd.Series(["8", 6, "7.5", 3, "0.9"]) # mixed string and numeric values
>>> s
0 8
1 6
2 7.5
3 3
4 0.9
dtype: object
>>> pd.to_numeric(s) # convert everything to float values
0 8.0
1 6.0
2 7.5
3 3.0
4 0.9
dtype: float64
Как видите, новая серия возвращается. Не забудьте назначить этот вывод переменной или столбцу, чтобы продолжить его использовать:
# convert Series
my_series = pd.to_numeric(my_series)
# convert column "a" of a DataFrame
df["a"] = pd.to_numeric(df["a"])
Вы также можете использовать его для преобразования нескольких столбцов DataFrame через apply() метод:
# convert all columns of DataFrame
df = df.apply(pd.to_numeric) # convert all columns of DataFrame
# convert just columns "a" and "b"
df[["a", "b"]] = df[["a", "b"]].apply(pd.to_numeric)
Пока ваши значения могут быть преобразованы, это, вероятно, все, что вам нужно.
Обработка ошибок
Но что, если некоторые значения не могут быть преобразованы в числовой тип?
to_numeric() также занимает errors Ключевой аргумент, который позволяет принудительно указывать нечисловые значения NaN или просто игнорируйте столбцы, содержащие эти значения.
Вот пример использования серии строк s который имеет объект dtype:
>>> s = pd.Series(['1', '2', '4.7', 'pandas', '10'])
>>> s
0 1
1 2
2 4.7
3 pandas
4 10
dtype: object
Поведение по умолчанию - повышение, если оно не может преобразовать значение. В этом случае он не может справиться со строкой 'pandas':
>>> pd.to_numeric(s) # or pd.to_numeric(s, errors='raise')
ValueError: Unable to parse string
Вместо того, чтобы терпеть неудачу, мы могли бы хотеть, чтобы 'панды' считались отсутствующим / плохим числовым значением. Мы можем привести неверные значения к NaN следующим образом, используя errors Ключевой аргумент:
>>> pd.to_numeric(s, errors='coerce')
0 1.0
1 2.0
2 4.7
3 NaN
4 10.0
dtype: float64
Третий вариант для errors просто игнорировать операцию, если встречается недопустимое значение:
>>> pd.to_numeric(s, errors='ignore')
# the original Series is returned untouched
Этот последний вариант особенно полезен, когда вы хотите преобразовать весь свой DataFrame, но не знаете, какие из наших столбцов можно надежно преобразовать в числовой тип. В этом случае просто напишите:
df.apply(pd.to_numeric, errors='ignore')
Функция будет применена к каждому столбцу DataFrame. Столбцы, которые можно преобразовать в числовой тип, будут преобразованы, тогда как столбцы, которые не могут (например, содержат нецифровые строки или даты), будут оставлены в покое.
понижающее приведение
По умолчанию конвертация с to_numeric() даст вам либо int64 или же float64 dtype (или любая другая целочисленная ширина, присущая вашей платформе).
Обычно это то, что вы хотите, но что, если вы хотите сэкономить память и использовать более компактный dtype, например float32, или же int8?
to_numeric() дает вам возможность понижать до "целое число", "подписано", "без знака", "с плавающей точкой". Вот пример для простой серии s целочисленного типа:
>>> s = pd.Series([1, 2, -7])
>>> s
0 1
1 2
2 -7
dtype: int64
При понижении до целочисленного значения используется наименьшее возможное целое число, которое может содержать значения:
>>> pd.to_numeric(s, downcast='integer')
0 1
1 2
2 -7
dtype: int8
Даункастинг до 'float' аналогично выбирает плавающий тип меньше обычного:
>>> pd.to_numeric(s, downcast='float')
0 1.0
1 2.0
2 -7.0
dtype: float32
2. astype()
astype() Метод позволяет вам четко указать тип d, который вы хотите иметь в своем DataFrame или Series. Он очень универсален в том, что вы можете попробовать перейти от одного типа к другому.
Основное использование
Просто выберите тип: вы можете использовать dum типа NumPy (например, np.int16), некоторые типы Python (например, bool) или типы, специфичные для панд (например, категориальный dtype).
Вызовите метод для объекта, который вы хотите преобразовать, и astype() постараюсь преобразовать его для вас:
# convert all DataFrame columns to the int64 dtype
df = df.astype(int)
# convert column "a" to int64 dtype and "b" to complex type
df = df.astype({"a": int, "b": complex})
# convert Series to float16 type
s = s.astype(np.float16)
# convert Series to Python strings
s = s.astype(str)
# convert Series to categorical type - see docs for more details
s = s.astype('category')
Заметьте, я сказал "попробуй" - если astype() не знает, как преобразовать значение в Series или DataFrame, это вызовет ошибку. Например, если у вас есть NaN или же inf Значение вы получите ошибку, пытаясь преобразовать его в целое число.
Начиная с панд 0.20.0, эту ошибку можно устранить, передав errors='ignore', Ваш оригинальный объект будет возвращен нетронутым.
Быть осторожен
astype() является мощным, но иногда он будет преобразовывать значения "неправильно". Например:
>>> s = pd.Series([1, 2, -7])
>>> s
0 1
1 2
2 -7
dtype: int64
Это маленькие целые числа, так как насчет преобразования в 8-битный тип без знака для экономии памяти?
>>> s.astype(np.uint8)
0 1
1 2
2 249
dtype: uint8
Преобразование работало, но -7 был обернут, чтобы стать 249 (то есть 2 8 - 7)!
Пытаясь удручить, используя pd.to_numeric(s, downcast='unsigned') вместо этого может помочь предотвратить эту ошибку.
3. infer_objects()
В версии 0.21.0 панды представили метод infer_objects() для преобразования столбцов объекта DataFrame, имеющих тип данных объекта, в более конкретный тип (мягкие преобразования).
Например, вот DataFrame с двумя столбцами типа объекта. Один содержит действительные целые числа, а другой содержит строки, представляющие целые числа:
>>> df = pd.DataFrame({'a': [7, 1, 5], 'b': ['3','2','1']}, dtype='object')
>>> df.dtypes
a object
b object
dtype: object
С помощью infer_objects() Вы можете изменить тип столбца 'a' на int64:
>>> df = df.infer_objects()
>>> df.dtypes
a int64
b object
dtype: object
Столбец 'b' был оставлен в покое, поскольку его значения были строками, а не целыми числами. Если вы хотите попробовать принудительно преобразовать оба столбца в целочисленный тип, вы можете использовать df.astype(int) вместо.
Как насчет этого?
a = [['a', '1.2', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a, columns=['one', 'two', 'three'])
df
Out[16]:
one two three
0 a 1.2 4.2
1 b 70 0.03
2 x 5 0
df.dtypes
Out[17]:
one object
two object
three object
df[['two', 'three']] = df[['two', 'three']].astype(float)
df.dtypes
Out[19]:
one object
two float64
three float64
Этот код ниже изменит тип данных столбца.
df[['col.name1', 'col.name2'...]] = df[['col.name1', 'col.name2'..]].astype('data_type')
Вместо типа данных вы можете указать свой тип данных. Что вы хотите, например, str,float,int и т. д.
Когда мне нужно было указать только определенные столбцы, и я хочу быть явным, я использовал (для DOCS LOCATION):
dataframe = dataframe.astype({'col_name_1':'int','col_name_2':'float64', etc. ...})
Итак, используя оригинальный вопрос, но предоставив ему имена столбцов...
a = [['a', '1.2', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a, columns=['col_name_1', 'col_name_2', 'col_name_3'])
df = df.astype({'col_name_2':'float64', 'col_name_3':'float64'})
панды>= 1.0
Вот диаграмма, которая обобщает некоторые из наиболее важных преобразований в пандах.
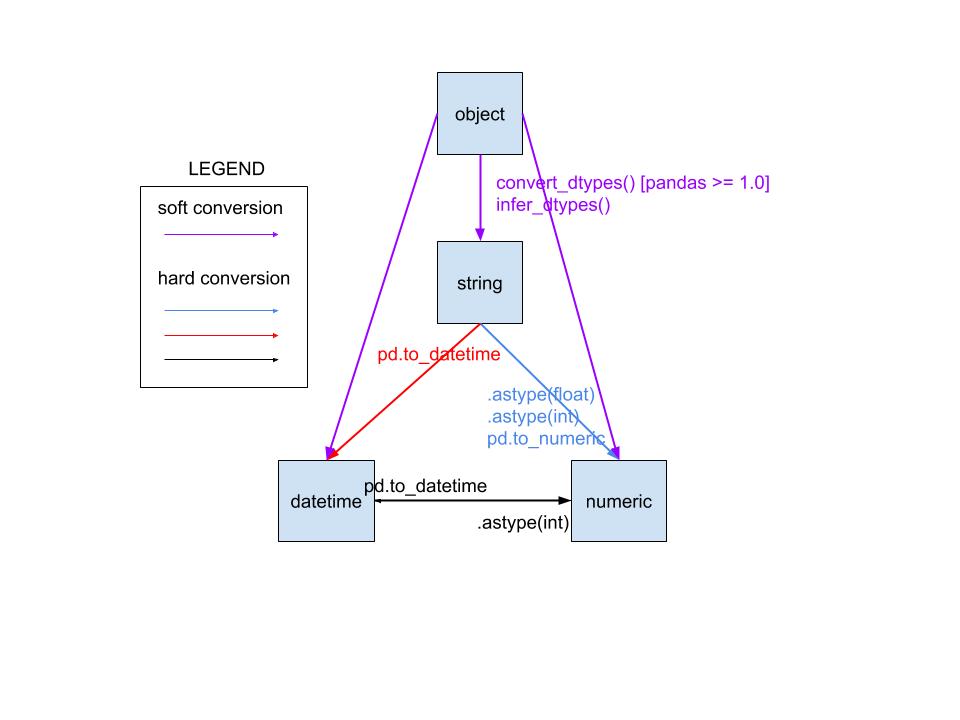
Преобразование в строку тривиально .astype(str) и не показаны на рисунке.
Преобразования "жесткие" и "мягкие"
Обратите внимание, что "преобразования" в этом контексте могут относиться либо к преобразованию текстовых данных в их фактический тип данных (жесткое преобразование), либо к выводу более подходящих типов данных для данных в столбцах объектов (мягкое преобразование). Чтобы проиллюстрировать разницу, взгляните на
df = pd.DataFrame({'a': ['1', '2', '3'], 'b': [4, 5, 6]}, dtype=object)
df.dtypes
a object
b object
dtype: object
# Actually converts string to numeric - hard conversion
df.apply(pd.to_numeric).dtypes
a int64
b int64
dtype: object
# Infers better data types for object data - soft conversion
df.infer_objects().dtypes
a object # no change
b int64
dtype: object
# Same as infer_objects, but converts to equivalent ExtensionType
df.convert_dtypes().dtypes
df = df.astype({"имя столбца": str})
#eg - для изменения типа столбца на строку
Вот функция, которая принимает в качестве аргументов объект DataFrame и список столбцов и приводит все данные в столбцах к числам.
# df is the DataFrame, and column_list is a list of columns as strings (e.g ["col1","col2","col3"])
# dependencies: pandas
def coerce_df_columns_to_numeric(df, column_list):
df[column_list] = df[column_list].apply(pd.to_numeric, errors='coerce')
Итак, для вашего примера:
import pandas as pd
def coerce_df_columns_to_numeric(df, column_list):
df[column_list] = df[column_list].apply(pd.to_numeric, errors='coerce')
a = [['a', '1.2', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a, columns=['col1','col2','col3'])
coerce_df_columns_to_numeric(df, ['col2','col3'])
Как насчет создания двух фреймов данных, каждый с разными типами данных для своих столбцов, а затем их объединения?
d1 = pd.DataFrame(columns=[ 'float_column' ], dtype=float)
d1 = d1.append(pd.DataFrame(columns=[ 'string_column' ], dtype=str))
Результаты
In[8}: d1.dtypes
Out[8]:
float_column float64
string_column object
dtype: object
После создания информационного кадра вы можете заполнить его переменными с плавающей запятой в 1-м столбце и строками (или любым другим типом данных) во 2-м столбце.
Преобразование строкового представления длинных чисел с плавающей запятой в числовые значения
Если столбец содержит строковое представление действительно длинных чисел с плавающей запятой, которые должны быть оценены с точностью (будет округлять их после 15 цифр иpd.to_numericеще более неточным), то используйте из стандартногоdecimalбиблиотека. Тип столбца будетobjectноdecimal.Decimalподдерживает все арифметические операции, поэтому вы по-прежнему можете выполнять векторизованные операции, такие как арифметические операции, операторы сравнения и т. д.
from decimal import Decimal
df = pd.DataFrame({'long_float': ["0.1234567890123456789", "0.123456789012345678", "0.1234567890123456781"]})
df['w_float'] = df['long_float'].astype(float) # imprecise
df['w_Decimal'] = df['long_float'].map(Decimal) # precise

В приведенном выше примере преобразует их все в одно и то же число, тогда какDecimalсохраняет их различие:
df['w_Decimal'] == Decimal(df.loc[1, 'long_float']) # False, True, False
df['w_float'] == float(df.loc[1, 'long_float']) # True, True, True
Преобразование строкового представления длинных целых чисел в целые числа
По умолчанию,astype(int)превращается вint32, что бы не сработало(OverflowError) если номер слишком длинный (например, номер телефона); попробуй (или дажеfloat) вместо:
df['long_num'] = df['long_num'].astype('int64')
Кстати, если вы получитеSettingWithCopyWarning, затем сделайте копию своего кадра и повторите все, что вы делали. Например, если вы конвертировалиcol1иcol2чтобы плавать dtype, затем выполните:
df = df.copy()
df[['col1', 'col2']] = df[['col1', 'col2']].astype(float)
# or use assign
df = df.assign(**{k: df[k].astype(float) for k in ['col1', 'col2']})
Преобразовать целые числа в timedelta
Кроме того, длинная строка/целое число может быть datetime или timedelta, и в этом случае используйтеto_datetimeилиto_timedeltaдля преобразования в datetime/timedelta dtype:
df = pd.DataFrame({'long_int': ['1018880886000000000', '1590305014000000000', '1101470895000000000', '1586646272000000000', '1460958607000000000']})
df['datetime'] = pd.to_datetime(df['long_int'].astype('int64'))
# or
df['datetime'] = pd.to_datetime(df['long_int'].astype(float))
df['timedelta'] = pd.to_timedelta(df['long_int'].astype('int64'))
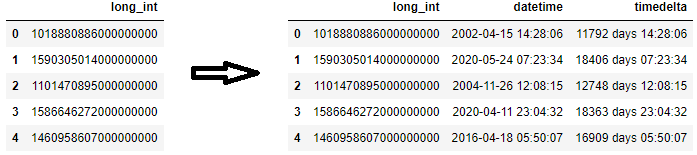
Преобразование timedelta в числа
Чтобы выполнить обратную операцию (преобразовать datetime/timedelta в числа), просмотрите ее как'int64'. Это может быть полезно, если вы создаете модель машинного обучения, которая каким-то образом должна включать время (или дату и время) в качестве числового значения. Просто убедитесь, что если исходные данные являются строками, то они должны быть преобразованы в timedelta или datetime перед любым преобразованием в числа.
df = pd.DataFrame({'Time diff': ['2 days 4:00:00', '3 days', '4 days', '5 days', '6 days']})
df['Time diff in nanoseconds'] = pd.to_timedelta(df['Time diff']).view('int64')
df['Time diff in seconds'] = pd.to_timedelta(df['Time diff']).view('int64') // 10**9
df['Time diff in hours'] = pd.to_timedelta(df['Time diff']).view('int64') // (3600*10**9)
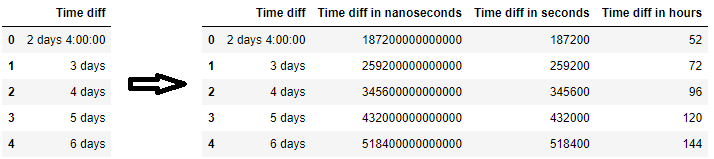
Преобразование даты и времени в числа
Для даты и времени числовое представление даты и времени — это разница во времени между этой датой и эпохой UNIX (1970-01-01).
df = pd.DataFrame({'Date': ['2002-04-15', '2020-05-24', '2004-11-26', '2020-04-11', '2016-04-18']})
df['Time_since_unix_epoch'] = pd.to_datetime(df['Date'], format='%Y-%m-%d').view('int64')

astypeбыстрее, чемto_numeric
df = pd.DataFrame(np.random.default_rng().choice(1000, size=(10000, 50)).astype(str))
df = pd.concat([df, pd.DataFrame(np.random.rand(10000, 50).astype(str), columns=range(50, 100))], axis=1)
%timeit df.astype(dict.fromkeys(df.columns[:50], int) | dict.fromkeys(df.columns[50:], float))
# 488 ms ± 28 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit df.apply(pd.to_numeric)
# 686 ms ± 45.8 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
df.info() gives us initial datatype of temp which is float64
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 132 non-null object
1 temp 132 non-null float64
Now, use this code to change the datatype to int64: df['temp'] = df['temp'].astype('int64')
if you do df.info() again, you will see:
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 132 non-null object
1 temp 132 non-null int64
this shows you have successfully changed the datatype of column temp. Happy coding!
Начиная с pandas 1.0.0, у нас есть pandas.DataFrame.convert_dtypes. Вы даже можете контролировать, какие типы преобразовывать!
In [40]: df = pd.DataFrame(
...: {
...: "a": pd.Series([1, 2, 3], dtype=np.dtype("int32")),
...: "b": pd.Series(["x", "y", "z"], dtype=np.dtype("O")),
...: "c": pd.Series([True, False, np.nan], dtype=np.dtype("O")),
...: "d": pd.Series(["h", "i", np.nan], dtype=np.dtype("O")),
...: "e": pd.Series([10, np.nan, 20], dtype=np.dtype("float")),
...: "f": pd.Series([np.nan, 100.5, 200], dtype=np.dtype("float")),
...: }
...: )
In [41]: dff = df.copy()
In [42]: df
Out[42]:
a b c d e f
0 1 x True h 10.0 NaN
1 2 y False i NaN 100.5
2 3 z NaN NaN 20.0 200.0
In [43]: df.dtypes
Out[43]:
a int32
b object
c object
d object
e float64
f float64
dtype: object
In [44]: df = df.convert_dtypes()
In [45]: df.dtypes
Out[45]:
a Int32
b string
c boolean
d string
e Int64
f float64
dtype: object
In [46]: dff = dff.convert_dtypes(convert_boolean = False)
In [47]: dff.dtypes
Out[47]:
a Int32
b string
c object
d string
e Int64
f float64
dtype: object
У меня была такая же проблема.
Я не мог найти ни одного решения, которое удовлетворяло бы меня. Мое решение состояло в том, чтобы просто преобразовать эти числа с плавающей запятой в строку и таким образом удалить «.0».
В моем случае я просто применяю его к первому столбцу:
firstCol = list(df.columns)[0]
df[firstCol] = df[firstCol].fillna('').astype(str).apply(lambda x: x.replace('.0', ''))
Если у вас есть различные столбцы объектов, такие как этот Dataframe из 74 столбцов объектов и 2 столбца Int, где каждое значение имеет буквы, представляющие единицы:
import pandas as pd
import numpy as np
dataurl = 'https://raw.githubusercontent.com/RubenGavidia/Pandas_Portfolio.py/main/Wes_Mckinney.py/nutrition.csv'
nutrition = pd.read_csv(dataurl,index_col=[0])
nutrition.head(3)
name serving_size calories total_fat saturated_fat cholesterol sodium choline folate folic_acid ... fat saturated_fatty_acids monounsaturated_fatty_acids polyunsaturated_fatty_acids fatty_acids_total_trans alcohol ash caffeine theobromine water
0 Cornstarch 100 g 381 0.1g NaN 0 9.00 mg 0.4 mg 0.00 mcg 0.00 mcg ... 0.05 g 0.009 g 0.016 g 0.025 g 0.00 mg 0.0 g 0.09 g 0.00 mg 0.00 mg 8.32 g
1 Nuts, pecans 100 g 691 72g 6.2g 0 0.00 mg 40.5 mg 22.00 mcg 0.00 mcg ... 71.97 g 6.180 g 40.801 g 21.614 g 0.00 mg 0.0 g 1.49 g 0.00 mg 0.00 mg 3.52 g
2 Eggplant, raw 100 g 25 0.2g NaN 0 2.00 mg 6.9 mg 22.00 mcg 0.00 mcg ... 0.18 g 0.034 g 0.016 g 0.076 g 0.00 mg 0.0 g 0.66 g 0.00 mg 0.00 mg 92.30 g
3 rows × 76 columns
nutrition.dtypes
name object
serving_size object
calories int64
total_fat object
saturated_fat object
...
alcohol object
ash object
caffeine object
theobromine object
water object
Length: 76, dtype: object
nutrition.dtypes.value_counts()
object 74
int64 2
dtype: int64
Хороший способ преобразовать все столбцы в числовые — использовать регулярные выражения для замены единиц измерения и astype(float) для изменения типа данных столбцов на float:
nutrition.index = pd.RangeIndex(start = 0, stop = 8789, step= 1)
nutrition.set_index('name',inplace = True)
nutrition.replace('[a-zA-Z]','', regex= True, inplace=True)
nutrition=nutrition.astype(float)
nutrition.head(3)
serving_size calories total_fat saturated_fat cholesterol sodium choline folate folic_acid niacin ... fat saturated_fatty_acids monounsaturated_fatty_acids polyunsaturated_fatty_acids fatty_acids_total_trans alcohol ash caffeine theobromine water
name
Cornstarch 100.0 381.0 0.1 NaN 0.0 9.0 0.4 0.0 0.0 0.000 ... 0.05 0.009 0.016 0.025 0.0 0.0 0.09 0.0 0.0 8.32
Nuts, pecans 100.0 691.0 72.0 6.2 0.0 0.0 40.5 22.0 0.0 1.167 ... 71.97 6.180 40.801 21.614 0.0 0.0 1.49 0.0 0.0 3.52
Eggplant, raw 100.0 25.0 0.2 NaN 0.0 2.0 6.9 22.0 0.0 0.649 ... 0.18 0.034 0.016 0.076 0.0 0.0 0.66 0.0 0.0 92.30
3 rows × 75 columns
nutrition.dtypes
serving_size float64
calories float64
total_fat float64
saturated_fat float64
cholesterol float64
...
alcohol float64
ash float64
caffeine float64
theobromine float64
water float64
Length: 75, dtype: object
nutrition.dtypes.value_counts()
float64 75
dtype: int64
Теперь набор данных чист, и вы можете выполнять числовые операции с этим Dataframe только с помощью regex и astype().
Если вы хотите собрать единицы и вставить в заголовки, как
cholesterol_mgвы можете использовать этот код:
nutrition.index = pd.RangeIndex(start = 0, stop = 8789, step= 1)
nutrition.set_index('name',inplace = True)
nutrition.astype(str).replace('[^a-zA-Z]','', regex= True)
units = nutrition.astype(str).replace('[^a-zA-Z]','', regex= True)
units = units.mode()
units = units.replace('', np.nan).dropna(axis=1)
mapper = { k: k + "_" + units[k].at[0] for k in units}
nutrition.rename(columns=mapper, inplace=True)
nutrition.replace('[a-zA-Z]','', regex= True, inplace=True)
nutrition=nutrition.astype(float)
Есть ли способ указать типы при преобразовании в DataFrame?
Да. Другие ответы преобразуют dtypes после создания DataFrame, но мы можем указать типы при создании. Используйте либо или в зависимости от формата ввода.
Последнее иногда необходимо, чтобы .
1. DataFrame.from_records
Создайте DataFrame из структурированного массива желаемых типов столбцов:
x = [['foo', '1.2', '70'], ['bar', '4.2', '5']]
df = pd.DataFrame.from_records(np.array(
[tuple(row) for row in x], # pass a list-of-tuples (x can be a list-of-lists or 2D array)
'object, float, int' # define the column types
))
Выход:
>>> df.dtypes
# f0 object
# f1 float64
# f2 int64
# dtype: object
2. read_csv(dtype=...)
Если вы читаете данные из файла, используйте
dtypeпараметр
read_csvдля установки типов столбцов во время загрузки.
Например, здесь мы читаем 30 миллионов строк с помощью
ratingкак 8-битные целые числа и
genreкак категоричное:
lines = '''
foo,biography,5
bar,crime,4
baz,fantasy,3
qux,history,2
quux,horror,1
'''
columns = ['name', 'genre', 'rating']
csv = io.StringIO(lines * 6_000_000) # 30M lines
df = pd.read_csv(csv, names=columns, dtype={'rating': 'int8', 'genre': 'category'})
В этом случае мы вдвое уменьшаем использование памяти при загрузке:
>>> df.info(memory_usage='deep')
# memory usage: 1.8 GB
>>> pd.read_csv(io.StringIO(lines * 6_000_000)).info(memory_usage='deep')
# memory usage: 3.7 GB
Это один из способов избежать ошибок памяти при работе с большими даннымиизбежать ошибок памяти при работе с большими данными . Не всегда возможно изменить dtypes после загрузки, так как у нас может не хватить памяти для загрузки данных с типом по умолчанию.
Я думал, что у меня та же проблема, но на самом деле у меня есть небольшая разница, которая облегчает решение проблемы. Для других, смотрящих на этот вопрос, стоит проверить формат вашего списка ввода. В моем случае числа изначально плавающие, а не строки, как в вопросе:
a = [['a', 1.2, 4.2], ['b', 70, 0.03], ['x', 5, 0]]
но слишком много обрабатывая список перед созданием информационного кадра, я теряю типы, и все становится строкой.
Создание фрейма данных через массив NumPy
df = pd.DataFrame(np.array(a))
df
Out[5]:
0 1 2
0 a 1.2 4.2
1 b 70 0.03
2 x 5 0
df[1].dtype
Out[7]: dtype('O')
дает тот же кадр данных, что и в вопросе, где записи в столбцах 1 и 2 рассматриваются как строки. Однако делать
df = pd.DataFrame(a)
df
Out[10]:
0 1 2
0 a 1.2 4.20
1 b 70.0 0.03
2 x 5.0 0.00
df[1].dtype
Out[11]: dtype('float64')
на самом деле дает фрейм данных со столбцами в правильном формате
Если вы хотите преобразовать один столбец из строкового формата, я предлагаю использовать этот код"
import pandas as pd
#My Test Data
data = {'Product': ['A','B', 'C','D'],
'Price': ['210','250', '320','280']}
data
#Create Data Frame from My data df = pd.DataFrame(data)
#Convert to number
df['Price'] = pd.to_numeric(df['Price'])
df
Total = sum(df['Price'])
Total
иначе, если вы собираетесь преобразовать несколько значений столбца в число, я предлагаю вам сначала отфильтровать ваши значения и сохранить их в пустом массиве, а затем преобразовать в число. Я надеюсь, что этот код решит вашу проблему.
import numpy as np
import pandas as pd
a = np.array([["M", 86],
["M", 76],
["M", 56],
["M", 66],
["B", 16],
["B", 13],
["B", 16],
["B", 18],
["B", 14], ])
df = pd.DataFrame(data=a, columns=["Case", "radius"])
print(df)
print(df.columns)
a = df[(df["radius"] >= "57") & (df["Case"] == "M")]["radius"].tolist()