Пример сквозного концерна
Что является хорошим примером cross-cutting concern? Пример медицинской карты на странице википедии мне кажется неполным.
В частности, из этого примера, почему ведение журнала ведет к дублированию кода (рассеянию)? (Помимо простых звонков, таких как log("....") везде, что не кажется большим делом).
В чем разница между core concern и cross-cutting concern?
Моя конечная цель - лучше понять АОП.
5 ответов
Прежде чем понять сквозную проблему, мы должны понять эту проблему.
Концерн - это термин, который относится к части системы, разделенной по функциональности.
Опасения бывают двух типов:
- Проблемы, представляющие единственную и специфическую функциональность для основных требований, известны как основные проблемы.
ИЛИ ЖЕ
Основная функциональность системы известна как основные проблемы.
Например: бизнес логика - Проблемы, представляющие функциональные возможности для вторичных потребностей, называются сквозными проблемами или проблемами всей системы.
ИЛИ ЖЕ
Перекрестная проблема - это проблема, которая применима ко всему приложению и затрагивает все приложение.
Например: ведение журнала, безопасность и передача данных - это проблемы, которые необходимы почти в каждом модуле приложения, и, следовательно, они являются сквозными проблемами.
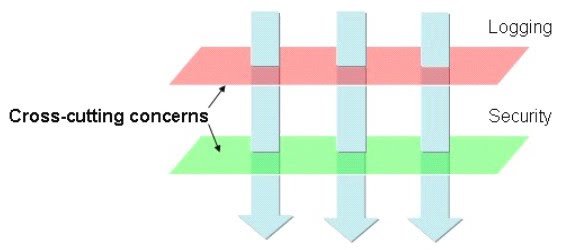
Этот рисунок представляет типичное приложение, которое разбито на модули. Основной задачей каждого модуля является предоставление услуг для его конкретного домена. Однако каждый из этих модулей также требует аналогичных вспомогательных функций, таких как ведение журнала безопасности и управление транзакциями. Примером сквозных проблем является "регистрация", которая часто используется в распределенных приложениях для облегчения отладки путем отслеживания вызовов методов. Предположим, мы ведем логирование как в начале, так и в конце каждого тела функции. Это приведет к пересечению всех классов, которые имеют хотя бы одну функцию.
Я думаю, что единственный лучший пример сквозной проблемы - это транзакционное поведение. Например, необходимость помещать блоки try-catch с вызовами commit и rollback во все ваши сервисные методы будет отталкивающей. Аннотирование методов маркером, который AOP может использовать для инкапсуляции их с желаемым поведением транзакций, является большой победой.
Другим хорошим кандидатом в качестве примера сквозной проблемы является авторизация. Аннотирование сервисного метода маркером, который сообщает, кто может его вызвать, и предоставление некоторой рекомендации AOP решения о том, разрешить или нет вызов метода, может быть предпочтительнее обработки этого в коде метода сервиса.
Внедрение ведения журнала с рекомендациями AOP может стать способом обеспечения большей гибкости, так что вы можете изменить то, что регистрируется, изменив точку соединения. На практике я не вижу, чтобы проекты делали это очень часто. Обычно использование библиотеки, такой как log4j, которая позволяет вам фильтровать по уровню ведения журнала и категории, во время выполнения, если вам нужно, работает достаточно хорошо.
Основная проблема - причина существования приложения, бизнес-логика, которую приложение автоматизирует. Если у вас есть приложение для логистики, которое обрабатывает грузовые перевозки, выяснение того, сколько грузов вы можете упаковать в грузовик, или какой маршрут для грузовика лучше всего выбрать, чтобы отбросить свои поставки, может стать основной проблемой. Сквозные проблемы обычно представляют собой детали реализации, которые необходимо хранить отдельно от бизнес-логики.
В дополнение к принятому ответу я хочу привести еще один пример сквозной проблемы: удаленное взаимодействие. Скажем, я просто хочу вызывать другие компоненты в моей экосистеме локально, как если бы они работали в процессе. Может быть, в некоторых случаях они даже делают. Но теперь я хочу запустить свои сервисы, распределенные в облаке или кластере. Почему я должен заботиться об этом аспекте как разработчик приложения? Аспект может позаботиться о том, чтобы узнать, кому и как звонить, при необходимости сериализовать передаваемые данные и сделать удаленный вызов. Если бы все работало в процессе, аспект просто переадресовал бы локальный вызов. Со стороны вызываемого абонента аспект десериализует данные, выполняет локальный вызов и возвращает результат.
Теперь позвольте мне рассказать вам небольшую историю о "тривиальных" вещах, таких как вывод журнала: всего несколько недель назад я провел рефакторинг сложной, но не слишком большой базы кода (около 250 тыс. Строк кода) для клиента. В нескольких сотнях классов использовался один тип каркасов, в других - несколько сотен. Тогда было несколько тысяч строк System.out.println(*) где действительно должен был быть вывод журнала. В итоге я исправил тысячи строк кода, разбросанных по всей базе кода. К счастью, я мог использовать некоторые хитрые трюки в IntelliJ IDEA (структурный поиск и замена), чтобы ускорить весь процесс, но вы не думаете, что это было тривиально! Конечно, строго зависящее от контекста ведение журнала отладки всегда будет происходить в теле метода, но многие важные типы ведения журнала, такие как отслеживание вызовов метода (даже иерархически с хорошо выделенным выводом), запись как обработанных, так и необработанных исключений, аудит пользователей (запись вызовов в ограниченные методы, основанные на пользовательских ролях) и т. д. могут быть легко реализованы в аспектах без их загрязнения исходного кода. Разработчику повседневных приложений не нужно думать об этом или даже видеть вызовы логгера, разбросанные по базе кода. Кто-то отвечает за поддержание аспекта в актуальном состоянии и может даже централизованно переключать стратегию ведения журнала или всю структуру ведения журнала в одном месте.
Я могу придумать аналогичные объяснения для других сквозных вопросов. Сохранение кода чистым и свободным от рассеяния и запутывания IMO - это вопрос профессионализма, а не ничего дополнительного. И последнее, но не менее важное: он делает код читаемым, поддерживаемым, рефакторируемым Аминь.
Я нашел это очень ясным из Википедии:
при написании приложения для обработки медицинских записей индексация таких записей является основной задачей, в то время как регистрация истории изменений в базе данных записей, базе данных пользователей или системе аутентификации будет сквозной проблемой, поскольку они взаимодействуют с большим количеством частей программы.
Примеры сквозных проблем:
Бизнес правила
Кеширование
Мобильность кода
Проверка достоверности данных
Оптимизация для домена
Обнаружение и исправление ошибок
Интернационализация и локализация, включая языковую локализацию
Информационная безопасность
логирование
Управление памятью
Мониторинг
Упорство
Особенности продукта
Ограничения в реальном времени
Синхронизация
Обработка транзакции
Контекстно-зависимая помощь
Перекрестные опасения - это сценарии, которые должны всегда присутствовать независимо от типа приложения.
Например, ведение журнала, безопасность, профилирование производительности, локализация, доступность, транзакция и т. Д. Независимо от программного обеспечения, которое мы создаем, ведение журнала необходимо (иначе как кто-то будет отлаживать или получать некоторую соответствующую информацию из данных продукта). Безопасность (аутентификация / авторизация и т. Д.) Необходима там, где только аутентичный пользователь может войти в приложение с правильным набором привилегий. Нам нужно знать, как работает ваше приложение, затем нам нужно выполнить профилирование. В случае, если приложение используется международными пользователями (с их собственным локализованным языком), нам необходимо поддерживать то же самое в приложении. Доступность - это случаи, когда люди с ограниченными возможностями могут использовать наше приложение.
Теперь, независимо от того, является ли наше приложение настольным, веб-приложением и т. Д., Если оно должно использоваться конечными пользователями из разных регионов в производственной среде, тогда необходимы перекрестные разрезы. До сих пор я ничего не сказал о том, что такое приложение, и т.д., но дал список проблем, которые следует решить, прежде чем выпускать его для конечных пользователей в производственной среде. и это все о перекрестных проблемах (которые должны обрабатываться всеми приложениями / методами / классами, т.е. на разных уровнях).