Python: невозможно загрузить с селеном на веб-странице
Моя цель - загрузить zip-файл с https://www.shareinvestor.com/prices/price_download_zip_file.zip?type=history_all&market=bursa Это ссылка на этой веб-странице https://www.shareinvestor.com/prices/price_download.html. Затем сохраните его в этом каталоге "/home/vinvin/shKLSE/ (Я использую pythonaywhere). Затем распакуйте его и извлеките файл csv в каталог.
Код выполняется до конца без ошибок, но он не загружается. ZIP-файл автоматически загружается, если вручную нажать https://www.shareinvestor.com/prices/price_download_zip_file.zip?type=history_all&market=bursa.
Мой код с рабочим именем пользователя и паролем используется. Настоящее имя пользователя и пароль используются для облегчения понимания проблемы.
#!/usr/bin/python
print "hello from python 2"
import urllib2
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from pyvirtualdisplay import Display
import requests, zipfile, os
display = Display(visible=0, size=(800, 600))
display.start()
profile = webdriver.FirefoxProfile()
profile.set_preference('browser.download.folderList', 2)
profile.set_preference('browser.download.manager.showWhenStarting', False)
profile.set_preference('browser.download.dir', "/home/vinvin/shKLSE/")
profile.set_preference('browser.helperApps.neverAsk.saveToDisk', '/zip')
for retry in range(5):
try:
browser = webdriver.Firefox(profile)
print "firefox"
break
except:
time.sleep(3)
time.sleep(1)
browser.get("https://www.shareinvestor.com/my")
time.sleep(10)
login_main = browser.find_element_by_xpath("//*[@href='/user/login.html']").click()
print browser.current_url
username = browser.find_element_by_id("sic_login_header_username")
password = browser.find_element_by_id("sic_login_header_password")
print "find id done"
username.send_keys("bkcollection")
password.send_keys("123456")
print "log in done"
login_attempt = browser.find_element_by_xpath("//*[@type='submit']")
login_attempt.submit()
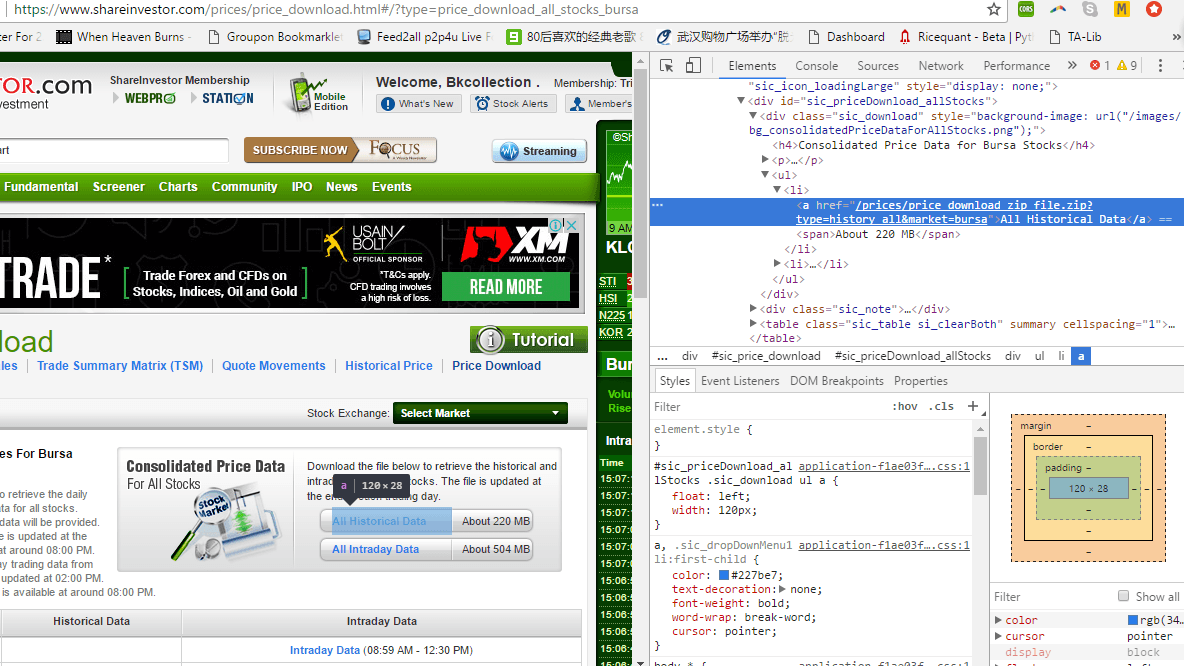
browser.get("https://www.shareinvestor.com/prices/price_download.html#/?type=price_download_all_stocks_bursa")
print browser.current_url
time.sleep(20)
dl = browser.find_element_by_xpath("//*[@href='/prices/price_download_zip_file.zip?type=history_all&market=bursa']").click()
time.sleep(30)
browser.close()
browser.quit()
display.stop()
zip_ref = zipfile.ZipFile(/home/vinvin/sh/KLSE, 'r')
zip_ref.extractall(/home/vinvin/sh/KLSE)
zip_ref.close()
os.remove(zip_ref)
HTML-фрагмент:
<li><a href="/prices/price_download_zip_file.zip?type=history_all&market=bursa">All Historical Data</a> <span>About 220 MB</span></li>
Обратите внимание, что & amp; отображается, когда я копирую фрагмент. Он был скрыт от источника просмотра, поэтому я думаю, что он написан на JavaScript.
Наблюдение я нашел
Каталог
home/vinvin/shKLSEне создал даже запускаю код без ошибокЯ пытаюсь загрузить гораздо меньший zip-файл, который может быть завершен за секунду, но все равно не загружается после ожидания 30 с.
dl = browser.find_element_by_xpath("//*[@href='/prices/price_download_zip_file.zip?type=history_daily&date=20170519&market=bursa']").click()
5 ответов
Я переписал ваш сценарий с комментариями, объясняющими, почему я внес изменения, которые я сделал. Я думаю, что вашей основной проблемой мог быть плохой mimetype, однако в вашем скрипте был журнал системных проблем, которые в лучшем случае делали бы его ненадежным. Эта перезапись использует явные ожидания, что полностью устраняет необходимость использования time.sleep()Это позволяет ему работать максимально быстро, а также устраняет ошибки, возникающие из-за перегрузки сети.
Вам нужно будет сделать следующее, чтобы убедиться, что все модули установлены:
pip install requests explicit selenium retry pyvirtualdisplay
Сценарий:
#!/usr/bin/python
from __future__ import print_function # Makes your code portable
import os
import glob
import zipfile
from contextlib import contextmanager
import requests
from retry import retry
from explicit import waiter, XPATH, ID
from selenium import webdriver
from pyvirtualdisplay import Display
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
DOWNLOAD_DIR = "/tmp/shKLSE/"
def build_profile():
profile = webdriver.FirefoxProfile()
profile.set_preference('browser.download.folderList', 2)
profile.set_preference('browser.download.manager.showWhenStarting', False)
profile.set_preference('browser.download.dir', DOWNLOAD_DIR)
# I think your `/zip` mime type was incorrect. This works for me
profile.set_preference('browser.helperApps.neverAsk.saveToDisk',
'application/vnd.ms-excel,application/zip')
return profile
# Retry is an elegant way to retry the browser creation
# Though you should narrow the scope to whatever the actual exception is you are
# retrying on
@retry(Exception, tries=5, delay=3)
@contextmanager # This turns get_browser into a context manager
def get_browser():
# Use a context manager with Display, so it will be closed even if an
# exception is thrown
profile = build_profile()
with Display(visible=0, size=(800, 600)):
browser = webdriver.Firefox(profile)
print("firefox")
try:
yield browser
finally:
# Let a try/finally block manage closing the browser, even if an
# exception is called
browser.quit()
def main():
print("hello from python 2")
with get_browser() as browser:
browser.get("https://www.shareinvestor.com/my")
# Click the login button
# waiter is a helper function that makes it easy to use explicit waits
# with it you dont need to use time.sleep() calls at all
login_xpath = '//*/div[@class="sic_logIn-bg"]/a'
waiter.find_element(browser, login_xpath, XPATH).click()
print(browser.current_url)
# Log in
username = "bkcollection"
username_id = "sic_login_header_username"
password = "123456"
password_id = "sic_login_header_password"
waiter.find_write(browser, username_id, username, by=ID)
waiter.find_write(browser, password_id, password, by=ID, send_enter=True)
# Wait for login process to finish by locating an element only found
# after logging in, like the Logged In Nav
nav_id = 'sic_loggedInNav'
waiter.find_element(browser, nav_id, ID)
print("log in done")
# Load the target page
target_url = ("https://www.shareinvestor.com/prices/price_download.html#/?"
"type=price_download_all_stocks_bursa")
browser.get(target_url)
print(browser.current_url)
# CLick download button
all_data_xpath = ("//*[@href='/prices/price_download_zip_file.zip?"
"type=history_all&market=bursa']")
waiter.find_element(browser, all_data_xpath, XPATH).click()
# This is a bit challenging: You need to wait until the download is complete
# This file is 220 MB, it takes a while to complete. This method waits until
# there is at least one file in the dir, then waits until there are no
# filenames that end in `.part`
# Note that is is problematic if there is already a file in the target dir. I
# suggest looking into using the tempdir module to create a unique, temporary
# directory for downloading every time you run your script
print("Waiting for download to complete")
at_least_1 = lambda x: len(x("{0}/*.zip*".format(DOWNLOAD_DIR))) > 0
WebDriverWait(glob.glob, 300).until(at_least_1)
no_parts = lambda x: len(x("{0}/*.part".format(DOWNLOAD_DIR))) == 0
WebDriverWait(glob.glob, 300).until(no_parts)
print("Download Done")
# Now do whatever it is you need to do with the zip file
# zip_ref = zipfile.ZipFile(DOWNLOAD_DIR, 'r')
# zip_ref.extractall(DOWNLOAD_DIR)
# zip_ref.close()
# os.remove(zip_ref)
print("Done!")
if __name__ == "__main__":
main()
Полное раскрытие: я поддерживаю явный модуль. Он разработан для того, чтобы сделать использование явных ожиданий намного проще, именно в таких ситуациях, когда веб-сайты медленно загружаются в динамическом контенте, основанном на взаимодействиях пользователей. Вы можете заменить все waiter.XXX звонки выше с прямым явным ожиданием.
Я не вижу каких-либо серьезных недостатков в вашем блоке кода как таковом. Но вот несколько рекомендаций по этому решению и выполнению этого сценария автоматического тестирования:
- Этот код прекрасно работает в нерабочее время. В часы работы рынка много
JavaScript&Ajax Callsнаходятся в игре и решают те вопросы, которые выходят за рамки этого Вопроса. - Вы можете сначала проверить наличие каталога для загрузки и, если он недоступен, создать новый. Этот блок кода для этой функциональности выполнен в стиле Windows и отлично работает на платформе Windows.
- После того, как вы нажмете "Войти", вызовите некоторые
waitдля HTML DOM для правильного рендеринга. - Если вы хотите проводить процесс загрузки, вам нужно установить некоторые дополнительные настройки в
FirefoxProfileкак упомянуто в моем коде ниже. - Всегда рассматривайте возможность увеличения окна браузера через
browser.maximize_window() - Когда вы начинаете загрузку, вам нужно подождать достаточно времени, чтобы полностью загрузить файл.
- Если вы используете
browser.quit()в конце вам не нужно использоватьbrowser.close() - Вы можете рассмотреть возможность замены всех
time.sleep()с любым изImplicitlyWaitили жеExplicitWaitили жеFluentWait, Вот ваш собственный блок кода с некоторыми простыми настройками:
#!/usr/bin/python print "hello from python 2" import urllib2 from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from pyvirtualdisplay import Display import requests, zipfile, os display = Display(visible=0, size=(800, 600)) display.start() newpath = 'C:\\home\\vivvin\\shKLSE' if not os.path.exists(newpath): os.makedirs(newpath) profile = webdriver.FirefoxProfile() profile.set_preference("browser.download.dir",newpath); profile.set_preference("browser.download.folderList",2); profile.set_preference("browser.helperApps.neverAsk.saveToDisk", "application/zip"); profile.set_preference("browser.download.manager.showWhenStarting",False); profile.set_preference("browser.helperApps.neverAsk.openFile","application/zip"); profile.set_preference("browser.helperApps.alwaysAsk.force", False); profile.set_preference("browser.download.manager.useWindow", False); profile.set_preference("browser.download.manager.focusWhenStarting", False); profile.set_preference("browser.helperApps.neverAsk.openFile", ""); profile.set_preference("browser.download.manager.alertOnEXEOpen", False); profile.set_preference("browser.download.manager.showAlertOnComplete", False); profile.set_preference("browser.download.manager.closeWhenDone", True); profile.set_preference("pdfjs.disabled", True); for retry in range(5): try: browser = webdriver.Firefox(profile) print "firefox" break except: time.sleep(3) time.sleep(1) browser.maximize_window() browser.get("https://www.shareinvestor.com/my") time.sleep(10) login_main = browser.find_element_by_xpath("//*[@href='/user/login.html']").click() time.sleep(10) print browser.current_url username = browser.find_element_by_id("sic_login_header_username") password = browser.find_element_by_id("sic_login_header_password") print "find id done" username.send_keys("bkcollection") password.send_keys("123456") print "log in done" login_attempt = browser.find_element_by_xpath("//*[@type='submit']") login_attempt.submit() browser.get("https://www.shareinvestor.com/prices/price_download.html#/?type=price_download_all_stocks_bursa") print browser.current_url time.sleep(20) dl = browser.find_element_by_xpath("//*[@href='/prices/price_download_zip_file.zip?type=history_all&market=bursa']").click() time.sleep(900) browser.close() browser.quit() display.stop() zip_ref = zipfile.ZipFile(/home/vinvin/sh/KLSE, 'r') zip_ref.extractall(/home/vinvin/sh/KLSE) zip_ref.close() os.remove(zip_ref)
Дайте мне знать, если это отвечает на ваш вопрос.
Причина в том, что веб-страница загружается медленно. Я добавил ожидание 20 секунд после открытия ссылки на веб-страницу
login_attempt.submit()
browser.get("https://www.shareinvestor.com/prices/price_download.html#/?type=price_download_all_stocks_bursa")
print browser.current_url
time.sleep(20)
dl = browser.find_element_by_xpath("//*[@href='/prices/price_download_zip_file.zip?type=history_all&market=bursa']").click()
Это не возвращает ошибку.
Дополнительно,/zip неверный тип MIME. Изменить на profile.set_preference('browser.helperApps.neverAsk.saveToDisk', 'application/zip')
Окончательная коррекция:
#!/usr/bin/python
print "hello from python 2"
import urllib2
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from pyvirtualdisplay import Display
import requests, zipfile, os
display = Display(visible=0, size=(800, 600))
display.start()
profile = webdriver.FirefoxProfile()
profile.set_preference('browser.download.folderList', 2)
profile.set_preference('browser.download.manager.showWhenStarting', False)
profile.set_preference('browser.download.dir', "/home/vinvin/shKLSE/")
# application/zip not /zip
profile.set_preference('browser.helperApps.neverAsk.saveToDisk', 'application/zip')
for retry in range(5):
try:
browser = webdriver.Firefox(profile)
print "firefox"
break
except:
time.sleep(3)
time.sleep(1)
browser.get("https://www.shareinvestor.com/my")
time.sleep(10)
login_main = browser.find_element_by_xpath("//*[@href='/user/login.html']").click()
print browser.current_url
username = browser.find_element_by_id("sic_login_header_username")
password = browser.find_element_by_id("sic_login_header_password")
print "find id done"
username.send_keys("bkcollection")
password.send_keys("123456")
print "log in done"
login_attempt = browser.find_element_by_xpath("//*[@type='submit']")
login_attempt.submit()
browser.get("https://www.shareinvestor.com/prices/price_download.html#/?type=price_download_all_stocks_bursa")
print browser.current_url
time.sleep(20)
dl = browser.find_element_by_xpath("//*[@href='/prices/price_download_zip_file.zip?type=history_all&market=bursa']").click()
time.sleep(30)
browser.close()
browser.quit()
display.stop()
zip_ref = zipfile.ZipFile('/home/vinvin/shKLSE/file.zip', 'r')
zip_ref.extractall('/home/vinvin/shKLSE')
zip_ref.close()
# remove with correct path
os.remove('/home/vinvin/shKLSE/file.zip')
Извлеките его из сферы действия селена. Измените настройки предпочтений, чтобы при щелчке по ссылке (сначала проверьте, является ли ссылка действительной) появилось всплывающее окно с запросом на сохранение, теперь используйте sikuli http://www.sikuli.org/ чтобы нажать на всплывающее окно. Типы пантомимы не всегда работают, и нет черно-белого ответа, почему он не работает.
Я не пробовал на сайте, который вы упомянули, однако следующий код отлично работает и загружает ZIP. если вы не можете скачать zip, тип Mime может быть другим. Вы можете использовать браузер Chrome и проверку сети, чтобы проверить тип mime файла, который вы пытаетесь загрузить.
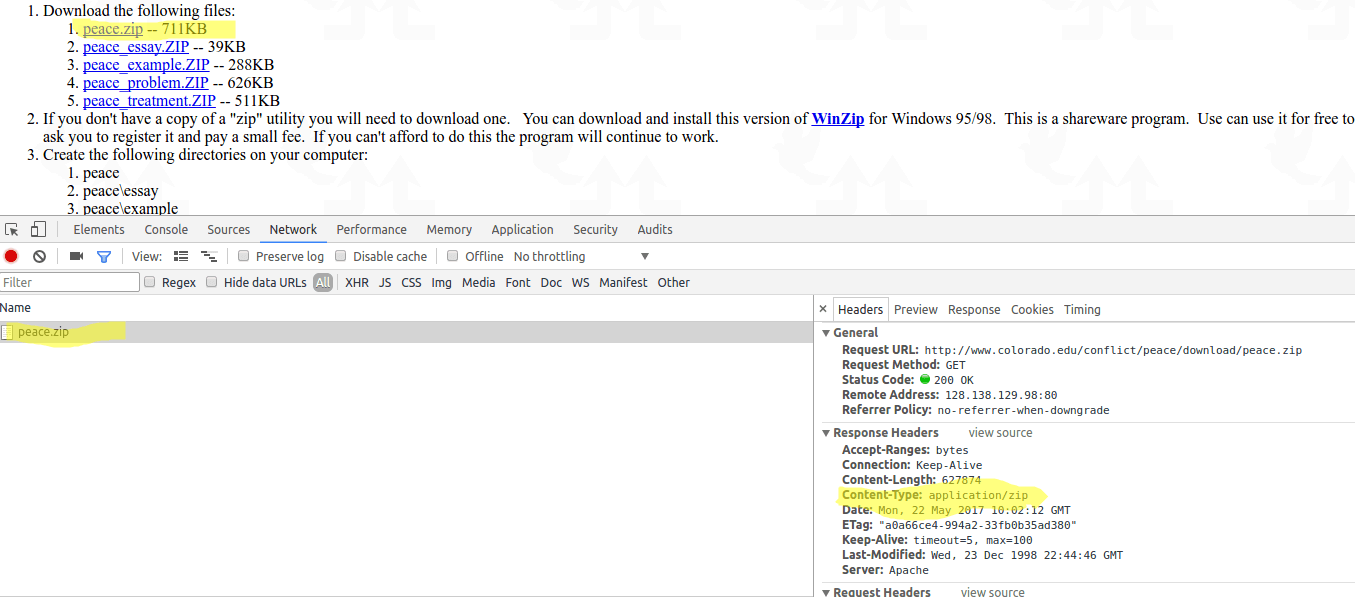
profile = webdriver.FirefoxProfile()
profile.set_preference('browser.download.folderList', 2)
profile.set_preference('browser.download.manager.showWhenStarting', False)
profile.set_preference('browser.download.dir', "/home/vinvin/shKLSE/")
profile.set_preference('browser.helperApps.neverAsk.saveToDisk', 'application/zip')
browser = webdriver.Firefox(profile)
browser.get("http://www.colorado.edu/conflict/peace/download/peace.zip")