Как подключиться к Has metastore программно в SparkSQL?
Я использую HiveContext с SparkSQL и пытаюсь подключиться к удаленному метастагу Hive. Единственный способ установить метасторье Hive - это включить hive-site.xml в путь к классам (или скопировать его в /etc/spark/ конф /).
Есть ли способ установить этот параметр программно в коде Java без включения hive-site.xml? Если да, то какую конфигурацию Spark использовать?
11 ответов
Для Spark 1.x вы можете установить с помощью:
System.setProperty("hive.metastore.uris", "thrift://METASTORE:9083");
final SparkConf conf = new SparkConf();
SparkContext sc = new SparkContext(conf);
HiveContext hiveContext = new HiveContext(sc);
Или же
final SparkConf conf = new SparkConf();
SparkContext sc = new SparkContext(conf);
HiveContext hiveContext = new HiveContext(sc);
hiveContext.setConf("hive.metastore.uris", "thrift://METASTORE:9083");
Обновление, если улей Kerberized:
Попробуйте установить их перед созданием HiveContext:
System.setProperty("hive.metastore.sasl.enabled", "true");
System.setProperty("hive.security.authorization.enabled", "false");
System.setProperty("hive.metastore.kerberos.principal", hivePrincipal);
System.setProperty("hive.metastore.execute.setugi", "true");
В spark 2.0.+ Это должно выглядеть примерно так:
Не забудьте заменить "hive.metastore.uris" своим. Предполагается, что у вас уже запущена служба метастазов кустов (не сервер hive).
val spark = SparkSession
.builder()
.appName("interfacing spark sql to hive metastore without configuration file")
.config("hive.metastore.uris", "thrift://localhost:9083") // replace with your hivemetastore service's thrift url
.enableHiveSupport() // don't forget to enable hive support
.getOrCreate()
import spark.implicits._
import spark.sql
// create an arbitrary frame
val frame = Seq(("one", 1), ("two", 2), ("three", 3)).toDF("word", "count")
// see the frame created
frame.show()
/**
* +-----+-----+
* | word|count|
* +-----+-----+
* | one| 1|
* | two| 2|
* |three| 3|
* +-----+-----+
*/
// write the frame
frame.write.mode("overwrite").saveAsTable("t4")
Я тоже сталкивался с такой же проблемой, но решил. Просто следуйте этим шагам в версии Spark 2.0
Шаг 1: Скопируйте файл hive-site.xml из папки Hive conf в файл conf conf. 
Шаг 2: отредактируйте файл spark-env.sh и настройте драйвер mysql. (Если вы используете Mysql в качестве метастаза улья.) 
Или добавьте драйверы MySQL в Maven/SBT (при их использовании)
Шаг 3. Когда вы создаете сеанс spark, добавьте enableHiveSupport ()
val spark = SparkSession.builder.master ("local"). appName ("testing").enableHiveSupport ().getOrCreate ()
Образец кода:
package sparkSQL
/**
* Created by venuk on 7/12/16.
*/
import org.apache.spark.sql.SparkSession
object hivetable {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder.master("local[*]").appName("hivetable").enableHiveSupport().getOrCreate()
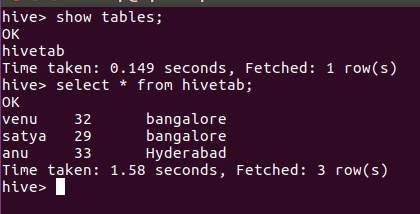
spark.sql("create table hivetab (name string, age int, location string) row format delimited fields terminated by ',' stored as textfile")
spark.sql("load data local inpath '/home/hadoop/Desktop/asl' into table hivetab").show()
val x = spark.sql("select * from hivetab")
x.write.saveAsTable("hivetab")
}
}
Выход:
Некоторые из похожих вопросов помечены как повторяющиеся, это для подключения к Hive из Spark без использования hive.metastore.uris или отдельный сберегательный сервер (9083) и не копировать hive-site.xml в SPARK_CONF_DIR.
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("hive-check")
.config(
"spark.hadoop.javax.jdo.option.ConnectionURL",
"JDBC_CONNECT_STRING"
)
.config(
"spark.hadoop.javax.jdo.option.ConnectionDriverName",
"org.postgresql.Driver"
)
.config("spark.sql.warehouse.dir", "/user/hive/warehouse")
.config("spark.hadoop.javax.jdo.option.ConnectionUserName", "JDBC_USER")
.config("spark.hadoop.javax.jdo.option.ConnectionPassword", "JDBC_PASSWORD")
.enableHiveSupport()
.getOrCreate()
spark.catalog.listDatabases.show(false)
Я заметил одно странное поведение при попытке подключиться к хранилищу метаданных улья из Spark без использования hive-site.xml.
Все работает нормально, когда мы используем
hive.metastore.urisсвойство в искровом коде при создании SparkSession. Но если мы не указываем в коде, а указываем при использовании
spark-shell или
spark-submit с участием
--conf флаг работать не будет.
Он выдаст предупреждение, как показано ниже, и не будет подключаться к удаленному хранилищу метаданных.
Warning: Ignoring non-Spark config property: hive.metastore.uris
Один из способов решения этой проблемы - использовать свойство ниже.
spark.hadoop.hive.metastore.uris
Для искры 3.x:
// Scala
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", "hive_warehouse_hdfs_path")
.enableHiveSupport()
.getOrCreate()
# Python
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.config("spark.sql.warehouse.dir", "hive_warehouse_hdfs_path") \
.enableHiveSupport() \
.getOrCreate()
Проверить доступные базы данных с помощью:
spark.catalog.listDatabases().show()
Версия Spark: 2.0.2
Улей версия: 1.2.1
Ниже код Java работал для меня, чтобы подключиться к Hive metastore от Spark:
import org.apache.spark.sql.SparkSession;
public class SparkHiveTest {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("Java Spark Hive Example")
.config("spark.master", "local")
.config("hive.metastore.uris",
"thrift://maxiqtesting123.com:9083")
.config("spark.sql.warehouse.dir", "/apps/hive/warehouse")
.enableHiveSupport()
.getOrCreate();
spark.sql("SELECT * FROM default.survey_data limit 5").show();
}
}
Ниже код работал для меня. Мы можем игнорировать конфиг hive.metastore.uris для локального метастаза, спарк создаст объекты улья в каталоге запасного склада локально.
import org.apache.spark.sql.SparkSession;
object spark_hive_support1
{
def main (args: Array[String])
{
val spark = SparkSession
.builder()
.master("yarn")
.appName("Test Hive Support")
//.config("hive.metastore.uris", "jdbc:mysql://localhost/metastore")
.enableHiveSupport
.getOrCreate();
import spark.implicits._
val testdf = Seq(("Word1", 1), ("Word4", 4), ("Word8", 8)).toDF;
testdf.show;
testdf.write.mode("overwrite").saveAsTable("WordCount");
}
}
В Hadoop 3 каталоги Spark и Hive разделены следующим образом:
Для искрового снаряда (в комплекте.enableHiveSupport() по умолчанию) просто попробуйте:
pyspark-shell --conf spark.hadoop.metastore.catalog.default=hive
Для искровых отправить задание создать вам искровую сессию, как это:
SparkSession.builder.appName("Test").enableHiveSupport().getOrCreate()
затем добавьте этот conf в свою команду spark-submit:
--conf spark.hadoop.metastore.catalog.default=hive
Но для таблицы ORC (и, в целом, внутренней таблицы) рекомендуется использовать HiveWareHouse Connector.
У меня сработала установка spark.hadoop.metastore.catalog.default=hive.
Я получаю следующую ошибку со Spark 2.4.8 или Spark 3.1.3 или Spark 3.2.2. Версия Hadoop — 3.2, Hbase 2.4.14, Hive 3.1.13 и Scala 2.12.
Исключение в потоке "main" java.io.IOException: не удается создать средство чтения записей из-за предыдущей ошибки. Дополнительные сведения см. в предыдущих строках полного журнала задачи. в org.apache.hadoop.hbase.mapreduce.TableInputFormatBase.getSplits(TableInputFormatBase.java:253) в org.apache.spark.rdd.NewHadoopRDD.getPartitions(NewHadoopRDD.scala:131) в org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) Я вызываю spark-submit следующим образом.
export HBASE_JAR_FILES="/usr/local/hbase/lib/hbase-unsafe-4.1.1.jar,/usr/local/hbase/lib/hbase-common-2.4.14.jar,/usr/local/hbase/lib/hbase-client-2.4.14.jar,/usr/local/hbase/lib/hbase-protocol-2.4.14.jar,/usr/local/hbase/lib/guava-11.0.2.jar,/usr/local/hbase/lib/client-facing-thirdparty/htrace-core4-4.2.0-incubating.jar"
/opt/spark/bin/spark-submit --master local[*] --deploy-mode client --num-executors 1 --executor-cores 1 --executor-memory 480m --driver-memory 512m --driver-class-path $(echo $HBASE_JAR_FILES | tr ',' ':') --jars "$HBASE_JAR_FILES" --files /usr/local/hive/conf/hive-site.xml --conf "spark.hadoop.metastore.catalog.default=hive" --files /usr/local/hbase/conf/hbase-site.xml --class com.hbase.dynamodb.migration.HbaseToDynamoDbSparkMain --conf "spark.driver.maxResultSize=256m" /home/hadoop/scala-2.12/sbt-1.0/HbaseToDynamoDb-assembly-0.1.0-SNAPSHOT.jar
The code is as follows.
val spark: SparkSession = SparkSession.builder()
.master("local[*]")
.appName("Hbase To DynamoDb migration demo")
.config("hive.metastore.warehouse.dir", "/user/hive/warehouse")
.config("hive.metastore.uris","thrift://localhost:9083")
.enableHiveSupport()
.getOrCreate()
spark.catalog.listDatabases().show()
val sqlDF = spark.sql("select rowkey, office_address, office_phone, name, personal_phone from hvcontacts")
sqlDF.show()
Внешняя таблица куста была создана поверх Hbase следующим образом.
create external table if not exists hvcontacts (rowkey STRING, office_address STRING, office_phone STRING, name STRING, personal_phone STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Office:Address,Office:Phone,Personal:name,Personal:Phone') TBLPROPERTIES ('hbase.table.name' = 'Contacts');
Хранилище метаданных находится в mysql, и я могу запросить таблицу tbls, чтобы проверить внешнюю таблицу в улье. Кто-нибудь еще сталкивается с подобной проблемой?
ПРИМЕЧАНИЕ. Я не использую здесь искровой соединитель улья.