Разбор таблицы PDF и отображение его в формате CSV(Java)
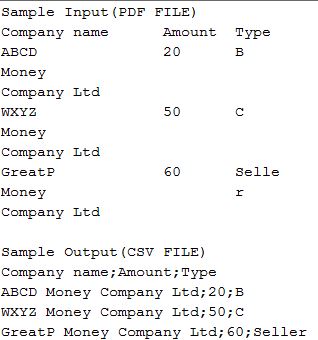
Я пытаюсь разобрать таблицу в файле PDF и отобразить его как CSV. Я приложил пример данных из PDF ниже (только несколько столбцов) и пример вывода для того же. Ширина каждого столбца фиксирована, скажем, Название компании (18 символов), Количество (8 символов), Тип (5 символов) и т. Д. Я пытался использовать банки I text и PDFBox, чтобы получать данные каждой страницы и анализировать их построчно, но звучит так не является хорошим решением, так как разрывы строк и разрывов страниц в PDF некорректны. Пожалуйста, дайте мне знать, если есть другое подходящее решение. Мы хотим использовать любое программное обеспечение с открытым исходным кодом для этого.
1 ответ
Это очень сложная проблема. Об этом даже есть несколько главных диссертаций.
Простая аналогия: у меня 5000 кусочков головоломки, все они идеально квадратные и могут поместиться где угодно. У некоторых из них есть кусочки строк, у некоторых есть отрывки текста.
Однако это не означает, что это невозможно сделать. Это просто займет работу.
Общий подход:
- используйте iText (в частности, IEventListener), чтобы получить информацию обо всех событиях рендеринга для каждой страницы
- выберите те события рендеринга, которые имеют смысл для вашего приложения. PathRenderInfo и TextRenderInfo.
- События в PDF не должны появляться в порядке в соответствии со спецификацией. Решите эту проблему, внедрив компаратор через IEventData. Этот компаратор должен сортировать в соответствии с порядком чтения. Это подразумевает, что вам, возможно, придется реализовать какое-то базовое определение языка, поскольку не каждый язык читает слева направо.
- После сортировки вы можете начать кластеризацию элементов в соответствии с любой эвристикой, найденной в литературе. Например, два символа могут быть сгруппированы в фрагмент текста, если они следуют друг за другом в отсортированном списке событий (то есть они появляются рядом друг с другом в порядке чтения), если позиция y не слишком сильно отличается (индекс и верхний индекс может ввернуть это), и, если положение х не слишком сильно отличается (кернинг).
- Продолжайте кластеризацию символов, пока не сформируете слова
- Предполагая, что вы сформировали слова, используйте аналогичный алгоритм, чтобы сформировать слова в строки. Используйте PathRenderInfo, чтобы запретить слияние слов, если они пересекаются со строкой.
- Предполагая, что вам удалось создать строки, теперь ищите таблицы. Одним из возможных подходов является применение горизонтальной и вертикальной проекции. И найдите те подзоны на странице, которые (при проецировании) показывают сетчатую структуру.
Такой подход высокого уровня должен сделать до боли очевидным, почему это не является широко доступной вещью. Это очень сложно реализовать. Это требует знания предметной области как PDF, шрифтов, так и машинного обучения.
Если вы согласны с коммерческими решениями, попробуйте pdf2Data. Это дополнение к iText, которое обладает именно этой функциональностью.