Стэнфордский парсер: как извлечь зависимости
Я хотел бы извлечь все зависимости в предложении, используя анализатор Стэнфорда. Рассмотрим следующий код
LexicalizedParser lp = LexicalizedParser.loadModel();
lp.setOptionFlags(new String[] { "-maxLength", "80", "-retainTmpSubcategories" });
String[] sent = "There is a football on the grass pitch which is 50% white with a pressure flow of 1".split(" ");
List<CoreLabel> rawWords = Sentence.toCoreLabelList(sent);
Tree parse = lp.apply(rawWords);
parse.pennPrint();
System.out.println();
TreebankLanguagePack tlp = new PennTreebankLanguagePack();
GrammaticalStructureFactory gsf = tlp.grammaticalStructureFactory();
GrammaticalStructure gs = gsf.newGrammaticalStructure(parse);
List<TypedDependency> tdl = gs.typedDependenciesCCprocessed();
System.out.println(tdl);
TreePrint tp = new TreePrint("penn,typedDependenciesCollapsed");
tp.printTree(parse);
Collection<TypedDependency> td = gs.typedDependenciesCollapsed();
//System.out.println(td);
Object[] list = td.toArray();
System.out.println(list.length);
TypedDependency typedDependency;
for (Object object : list) {
typedDependency = (TypedDependency) object;
System.out.println(
"Depdency Name " + typedDependency.dep().toString() + " :: " + typedDependency.reln());
if (typedDependency.reln().getShortName().equals("something")) {
// your code
}
}
так что это позволяет мне видеть зависимости как
Depdency Name There/EX :: expl
Depdency Name is/VBZ :: root
Depdency Name a/DT :: det
Depdency Name football/NN :: nsubj
Depdency Name on/IN :: case
Depdency Name the/DT :: det
Depdency Name grass/NN :: compound
Depdency Name pitch/NN :: nmod:on
Depdency Name which/WDT :: nsubj
Depdency Name is/VBZ :: cop
Depdency Name 50%/CD :: nummod
Depdency Name white/JJ :: amod
Depdency Name with/IN :: case
Depdency Name a/DT :: det
Depdency Name pressure/NN :: nmod:with
Depdency Name flow/NN :: acl:relcl
Depdency Name of/IN :: case
Depdency Name 1/CD :: nmod:of
теперь, когда я визуализирую то же самое на http://nlp.stanford.edu:8080/corenlp/process
я вижу
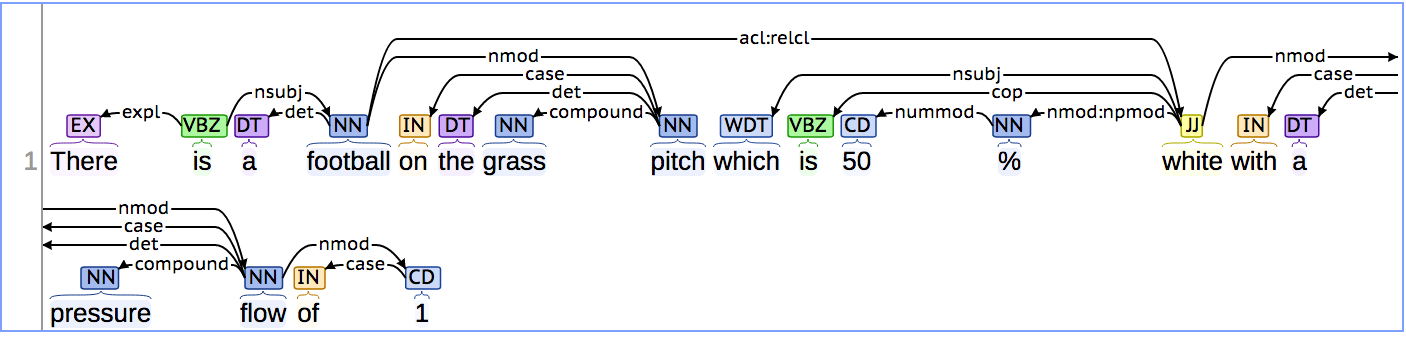
Как я могу извлечь все, что зависит от nsubj? Например, в этом случае
Я хочу знать, что такое солнечный объект. Это легко, так как я просто ищу имя узла
nsubjТеперь я также хочу следующую информацию
- Где футбол?
on the grass pitch - Любые другие атрибуты футбола?
which is 50% whiteа такжеpressure flow of 1
- Где футбол?
Как я должен перемещаться по дереву, чтобы извлечь эти зависимости? Есть ли способ для меня начать с nsubj узел и перейти на все зависимости?