Считать файл Json в data.frame без вложенных списков
Я пытаюсь загрузить файл JSON в data.frame в r. Мне повезло с функцией fromJSON в пакете jsonlite - но я получаю вложенные списки и не уверен, как сгладить ввод в двумерный data.frame. Jsonlite считывает файл как data.frame, но оставляет вложенные списки в некоторых переменных.
Есть ли у кого-нибудь советы по загрузке JSON-файла в data.frame, когда он читает с помощью вложенных списков.
#*#*#*#*#*#*#*#*#*##*#*#*#*#*#*#*#*#*# HERE IS MY EXAMPLE #*#*#*#*#*#*#*#*#*##*#*#*#*#*#*#*#*#*#
# loads the packages
library("httr")
library( "jsonlite")
# downloads an example file
providers <- fromJSON( "http://fm.formularynavigator.com/jsonFiles/publish/11/47/providers.json" , simplifyDataFrame=TRUE )
# the flatten function breaks the name variable into three vars ( first name, middle name, last name)
providers <- flatten( providers )
# but many of the columns are still lists:
sapply( providers , class)
# Some of these lists have a single level
head( providers$facility_type )
# Some have lot more than two - for example nine
providers[ , 6][[1]]
Я хочу одну строку для каждого npi, а затем отдельные столбцы для каждого среза отдельных списков - чтобы во фрейме данных были столбцы для "plan_id_type","plan_id","network_tier" девять раз, может быть, colnames, от 0 до 8 Я смог использовать этот сайт: http://www.convertcsv.com/json-to-csv.htm чтобы получить этот файл в двух измерениях, но так как я делаю сотни из них, я бы хотел иметь возможность делать это динамически. Это файл: http://s000.tinyupload.com/download.php?file_id=10808537503095762868&t=1080853750309576286812811 - я хотел бы загрузить файл с этой структурой в виде data.frame, используя функцию fromJson
Вот несколько вещей, которые я пробовал; Итак, я подумал о двух подходах; Во-первых: используйте другую функцию для чтения в файле Json, я посмотрел на
rjson but that reads in a list
library( rjson )
providers <- fromJSON( getURL( "https://fm.formularynavigator.com/jsonFiles/publish/11/47/providers.json") )
class( providers )
и я попробовал RJSONIO - я попробовал это Получение импортированных данных JSON в фрейм данных в R
json-data-into-a-data-frame-in-r
library( RJSONIO )
providers <- fromJSON( getURL( "https://fm.formularynavigator.com/jsonFiles/publish/11/47/providers.json") )
json_file <- lapply(providers, function(x) {
x[sapply(x, is.null)] <- NA
unlist(x)
})
# but When converting the lists to a data.frame I get an error
a <- do.call("rbind", json_file)
Итак, второй подход, который я попробовал, заключается в преобразовании всех списков в переменные в моем data.frame.
detach("package:RJSONIO", unload = TRUE )
detach("package:rjson", unload = TRUE )
library( "jsonlite")
providers <- fromJSON( "http://fm.formularynavigator.com/jsonFiles/publish/11/47/providers.json" , simplifyDataFrame=TRUE )
providers <- flatten( providers )
Я могу вытащить один из списков - но из-за пропусков я не могу слиться с моим фреймом данных
a <- data.frame(Reduce(rbind, providers$facility_type))
length( a ) == nrow( providers )
Я также попробовал эти предложения: Преобразование вложенного списка в dataframe. Ну, как и некоторые другие вещи, но не повезло
a <- sapply( providers$facility_type, unlist )
as.data.frame(t(sapply( providers$providers, unlist )) )
Любая помощь высоко ценится
4 ответа
Обновление: 21 февраля 2016 г.
col_fixer обновлен, чтобы включить vec2col аргумент, который позволяет вам сгладить столбец списка в одну строку или набор столбцов.
в data.frame Вы загрузили, я вижу несколько разных типов столбцов. Есть нормальные столбцы, содержащие векторы одного типа. Есть столбцы списка, где элементы могут быть NULL или сами могут быть плоским вектором. Есть столбцы списка, где есть data.frames как элементы списка. Есть столбцы списка, которые содержат data.frame из того же числа строк, что и основной data.frame,
Вот примерный набор данных, воссоздающий эти условия:
mydf <- data.frame(id = 1:3, type = c("A", "A", "B"),
facility = I(list(c("x", "y"), NULL, "x")),
address = I(list(data.frame(v1 = 1, v2 = 2, v4 = 3),
data.frame(v1 = 1:2, v2 = 3:4, v3 = 5),
data.frame(v1 = 1, v2 = NA, v3 = 3))))
mydf$person <- data.frame(name = c("AA", "BB", "CC"), age = c(20, 32, 23),
preference = c(TRUE, FALSE, TRUE))
str этого образца data.frame похоже:
str(mydf)
## 'data.frame': 3 obs. of 5 variables:
## $ id : int 1 2 3
## $ type : Factor w/ 2 levels "A","B": 1 1 2
## $ facility:List of 3
## ..$ : chr "x" "y"
## ..$ : NULL
## ..$ : chr "x"
## ..- attr(*, "class")= chr "AsIs"
## $ address :List of 3
## ..$ :'data.frame': 1 obs. of 3 variables:
## .. ..$ v1: num 1
## .. ..$ v2: num 2
## .. ..$ v4: num 3
## ..$ :'data.frame': 2 obs. of 3 variables:
## .. ..$ v1: int 1 2
## .. ..$ v2: int 3 4
## .. ..$ v3: num 5 5
## ..$ :'data.frame': 1 obs. of 3 variables:
## .. ..$ v1: num 1
## .. ..$ v2: logi NA
## .. ..$ v3: num 3
## ..- attr(*, "class")= chr "AsIs"
## $ person :'data.frame': 3 obs. of 3 variables:
## ..$ name : Factor w/ 3 levels "AA","BB","CC": 1 2 3
## ..$ age : num 20 32 23
## ..$ preference: logi TRUE FALSE TRUE
## NULL
Один из способов "сгладить" это - "исправить" столбцы списка. Есть три исправления.
flatten(из "jsonlite") позаботится о столбцах, подобных столбцу person.- Столбцы типа столбца "средство" можно исправить с помощью
toString, который будет преобразовывать каждый элемент в разделенный запятыми элемент или который может быть преобразован в несколько столбцов. - Колонны там, где есть
data.frames, некоторые с несколькими строками, сначала должны быть сведены в одну строку (путем преобразования в "широкий" формат), а затем должны быть связаны вместе как одинdata.table, (Я использую "data.table" для изменения формы и связывания строк).
Мы можем позаботиться о втором и третьем моментах с помощью функции, подобной следующей:
col_fixer <- function(x, vec2col = FALSE) {
if (!is.list(x[[1]])) {
if (isTRUE(vec2col)) {
as.data.table(data.table::transpose(x))
} else {
vapply(x, toString, character(1L))
}
} else {
temp <- rbindlist(x, use.names = TRUE, fill = TRUE, idcol = TRUE)
temp[, .time := sequence(.N), by = .id]
value_vars <- setdiff(names(temp), c(".id", ".time"))
dcast(temp, .id ~ .time, value.var = value_vars)[, .id := NULL]
}
}
Мы интегрируем это и flatten функция в другой функции, которая будет делать большую часть обработки.
Flattener <- function(indf, vec2col = FALSE) {
require(data.table)
require(jsonlite)
indf <- flatten(indf)
listcolumns <- sapply(indf, is.list)
newcols <- do.call(cbind, lapply(indf[listcolumns], col_fixer, vec2col))
indf[listcolumns] <- list(NULL)
cbind(indf, newcols)
}
Запуск функции дает нам:
Flattener(mydf)
## id type person.name person.age person.preference facility address.v1_1
## 1 1 A AA 20 TRUE x, y 1
## 2 2 A BB 32 FALSE 1
## 3 3 B CC 23 TRUE x 1
## address.v1_2 address.v2_1 address.v2_2 address.v4_1 address.v4_2 address.v3_1
## 1 NA 2 NA 3 NA NA
## 2 2 3 4 NA NA 5
## 3 NA NA NA NA NA 3
## address.v3_2
## 1 NA
## 2 5
## 3 NA
Или с векторами, идущими в отдельные столбцы:
Flattener(mydf, TRUE)
## id type person.name person.age person.preference facility.V1 facility.V2
## 1 1 A AA 20 TRUE x y
## 2 2 A BB 32 FALSE <NA> <NA>
## 3 3 B CC 23 TRUE x <NA>
## address.v1_1 address.v1_2 address.v2_1 address.v2_2 address.v4_1 address.v4_2
## 1 1 NA 2 NA 3 NA
## 2 1 2 3 4 NA NA
## 3 1 NA NA NA NA NA
## address.v3_1 address.v3_2
## 1 NA NA
## 2 5 5
## 3 3 NA
Вот str:
str(Flattener(mydf))
## 'data.frame': 3 obs. of 14 variables:
## $ id : int 1 2 3
## $ type : Factor w/ 2 levels "A","B": 1 1 2
## $ person.name : Factor w/ 3 levels "AA","BB","CC": 1 2 3
## $ person.age : num 20 32 23
## $ person.preference: logi TRUE FALSE TRUE
## $ facility : chr "x, y" "" "x"
## $ address.v1_1 : num 1 1 1
## $ address.v1_2 : num NA 2 NA
## $ address.v2_1 : num 2 3 NA
## $ address.v2_2 : num NA 4 NA
## $ address.v4_1 : num 3 NA NA
## $ address.v4_2 : num NA NA NA
## $ address.v3_1 : num NA 5 3
## $ address.v3_2 : num NA 5 NA
## NULL
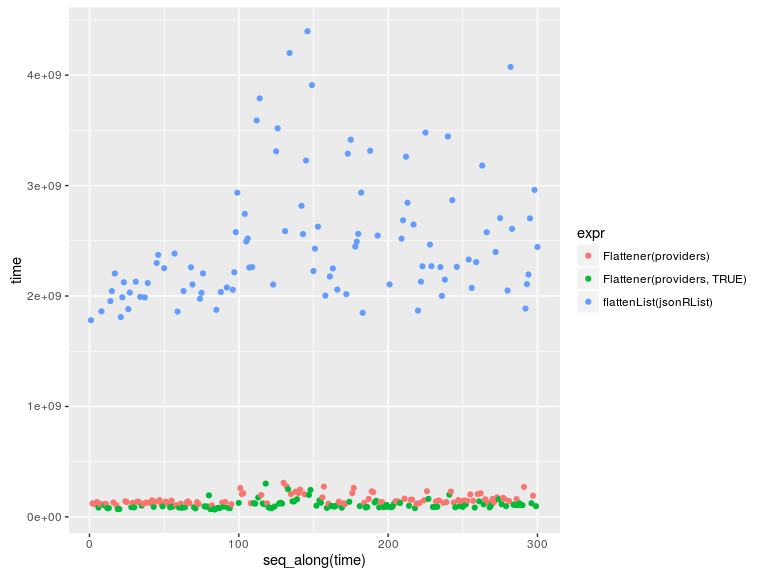
На вашем объекте "провайдеры" это выполняется очень быстро и последовательно:
library(microbenchmark)
out <- microbenchmark(Flattener(providers), Flattener(providers, TRUE), flattenList(jsonRList))
out
# Unit: milliseconds
# expr min lq mean median uq max neval
# Flattener(providers) 104.18939 126.59295 157.3744 138.4185 174.5222 308.5218 100
# Flattener(providers, TRUE) 67.56471 86.37789 109.8921 96.3534 121.4443 301.4856 100
# flattenList(jsonRList) 1780.44981 2065.50533 2485.1924 2269.4496 2694.1487 4397.4793 100
library(ggplot2)
qplot(y = time, data = out, colour = expr) ## Via @TylerRinker
Моим первым шагом было загрузить данные через RCurl::getURL() а также rjson::fromJSON()согласно второму примеру кода:
##--------------------------------------
## libraries
##--------------------------------------
library(rjson);
library(RCurl);
##--------------------------------------
## get data
##--------------------------------------
URL <- 'https://fm.formularynavigator.com/jsonFiles/publish/11/47/providers.json';
jsonRList <- fromJSON(getURL(URL)); ## recursive list representing the original JSON data
Далее, чтобы получить глубокое понимание структуры и чистоты данных, я написал набор вспомогательных функций:
##--------------------------------------
## helper functions
##--------------------------------------
## apply a function to a set of nodes at the same depth level in a recursive list structure
levelApply <- function(
nodes, ## the root node of the list (recursive calls pass deeper nodes as they drill down into the list)
keyList, ## another list, expected to hold a sequence of keys (component names, integer indexes, or NULL for all) specifying which nodes to select at each depth level
func=identity, ## a function to run separately on each node once keyList has been exhausted
..., ## further arguments passed to func()
joinFunc=NULL ## optional function for joining the return values of func() at each successive depth, as the stack is unwound. An alternative is calling unlist() on the result, but careful not to lose the top-level index association
) {
if (length(keyList) == 0L) {
ret <- if (is.null(nodes)) NULL else func(nodes,...)
} else if (is.null(keyList[[1L]]) || length(keyList[[1L]]) != 1L) {
ret <- lapply(if (is.null(keyList[[1L]])) nodes else nodes[keyList[[1L]]],levelApply,keyList[-1L],func,...,joinFunc=joinFunc);
if (!is.null(joinFunc))
ret <- do.call(joinFunc,ret);
} else {
ret <- levelApply(nodes[[keyList[[1L]]]],keyList[-1L],func,...,joinFunc=joinFunc);
}; ## end if
ret;
}; ## end if
## these two wrappers automatically attempt to simplify the results of func() to a vector or matrix/data.frame, respectively
levelApplyToVec <- function(...) levelApply(...,joinFunc=c);
levelApplyToFrame <- function(...) levelApply(...,joinFunc=rbind); ## can return matrix or data.frame, depending on ret
Ключом к пониманию вышеизложенного является keyList параметр. Допустим, у вас есть такой список:
list(NULL,'addresses',2:3,'city')
Это позволило бы выбрать все строки города под вторым и третьим адресными элементами под списком адресов под всеми элементами основного списка.
В R нет встроенных функций применения, которые могли бы работать на таких "параллельных" выборках узлов (rapply() это близко, но без сигары), поэтому я написал свой собственный. levelApply() находит каждый из подходящих узлов и запускает заданный func() на нем (по умолчанию identity()таким образом возвращая сам узел), возвращая результаты вызывающему joinFunc()или в той же структуре рекурсивного списка, в которой эти узлы существовали во входном списке. Быстрая демонстрация:
unname(levelApplyToVec(jsonRList,list(4L,'addresses',1:2,c('address','city'))));
## [1] "1001 Noble St" "Fairbanks" "1650 Cowles St" "Fairbanks"
Вот остальные вспомогательные функции, которые я написал в процессе работы над этой проблемой:
## for the given node selection key union, retrieve a data.frame of logicals representing the unique combinations of keys possessed by the selected nodes, possibly with a count
keyCombos <- function(node,keyList,allKeys) `rownames<-`(setNames(unique(as.data.frame(levelApplyToFrame(node,keyList,function(h) allKeys%in%names(h)))),allKeys),NULL);
keyCombosWithCount <- function(node,keyList,allKeys) { ks <- keyCombos(node,keyList,allKeys); ks$.count <- unname(apply(ks,1,function(combo) sum(levelApplyToVec(node,keyList,function(h) identical(sort(names(ks)[combo]),sort(names(h))))))); ks; };
## return a simple two-component list with type (list, namedlist, or atomic vector type) and len for non-namedlist types; tlStr() returns a nice stringified form of said list
tl <- function(e) { if (is.null(e)) return(NULL); ret <- typeof(e); if (ret == 'list' && !is.null(names(e))) ret <- list(type='namedlist') else ret <- list(type=ret,len=length(e)); ret; };
tlStr <- function(e) { if (is.null(e)) return(NA); ret <- tl(e); if (is.null(ret$len)) ret <- ret$type else ret <- paste0(ret$type,'[',ret$len,']'); ret; };
## stringification functions for display
mkcsv <- function(v) paste0(collapse=',',v);
keyListToStr <- function(keyList) paste0(collapse='','/',sapply(keyList,function(key) if (is.null(key)) '*' else paste0(collapse=',',key)));
## return a data.frame giving a comma-separated list of the unique types possessed by the selected nodes; useful for learning about the structure of the data
keyTypes <- function(node,keyList,allKeys) data.frame(key=allKeys,tl=sapply(allKeys,function(key) mkcsv(unique(na.omit(levelApplyToVec(node,c(keyList,key),tlStr))))),row.names=NULL);
## useful for testing; can call npiToFrame() to show the row with a specified npi value, in a nice vertical form
rowToFrame <- function(dfrow) data.frame(column=names(dfrow),value=c(as.matrix(dfrow)));
getNPIRow <- function(df,npi) which(df$npi == npi);
npiToFrame <- function(df,npi) rowToFrame(df[getNPIRow(df,npi),]);
Я попытался зафиксировать последовательность команд, которые я запускал для данных, когда я впервые их изучил. Ниже приведены результаты, показывающие команды, которые я выполнил, вывод команды и ведущие комментарии, описывающие мое намерение, и мой вывод из вывода:
##--------------------------------------
## data examination
##--------------------------------------
## type of object -- plain unnamed list => array, length 3256
levelApplyToVec(jsonRList,list(),tlStr);
## [1] "list[3256]"
## unique types of main array elements => all named lists => hashes
unique(levelApplyToVec(jsonRList,list(NULL),tlStr));
## [1] "namedlist"
## get the union of keys among all hashes
allKeys <- unique(levelApplyToVec(jsonRList,list(NULL),names)); allKeys;
## [1] "npi" "type" "facility_name" "facility_type" "addresses" "plans" "last_updated_on" "name" "speciality" "accepting" "languages" "gender"
## get the unique pattern of keys among all hashes, and how often each occurs => shows there are inconsistent key sets among the top-level hashes
keyCombosWithCount(jsonRList,list(NULL),allKeys);
## npi type facility_name facility_type addresses plans last_updated_on name speciality accepting languages gender .count
## 1 TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE 279
## 2 TRUE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE 2973
## 3 TRUE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE 4
## for each key, get the unique set of types it takes on among all hashes, ignoring hashes where the key is omitted => some scalar strings, some multi-string, addresses is a variable-length list, plans is length-9 list, and name is a hash
keyTypes(jsonRList,list(NULL),allKeys);
## key tl
## 1 npi character[1]
## 2 type character[1]
## 3 facility_name character[1]
## 4 facility_type character[1],character[2],character[3]
## 5 addresses list[1],list[2],list[3],list[6],list[5],list[7],list[4],list[8],list[9],list[13],list[12]
## 6 plans list[9]
## 7 last_updated_on character[1]
## 8 name namedlist
## 9 speciality character[1],character[2],character[3],character[4]
## 10 accepting character[1]
## 11 languages character[2],character[3],character[4],character[6],character[5]
## 12 gender character[1]
## must look deeper into addresses array, plans array, and name hash; we'll have to flatten them
## ==== addresses =====
## note: the addresses key is always present under main array elements
## unique types of address elements across all hashes => all named lists, thus nested hashes
unique(levelApplyToVec(jsonRList,list(NULL,'addresses',NULL),tlStr));
## [1] "namedlist"
## union of keys among all address element hashes
allAddressKeys <- unique(levelApplyToVec(jsonRList,list(NULL,'addresses',NULL),names)); allAddressKeys;
## [1] "address" "city" "state" "zip" "phone" "address_2"
## pattern of keys among address elements => only address_2 varies, similar frequency with it as without it
keyCombosWithCount(jsonRList,list(NULL,'addresses',NULL),allAddressKeys);
## address city state zip phone address_2 .count
## 1 TRUE TRUE TRUE TRUE TRUE FALSE 1898
## 2 TRUE TRUE TRUE TRUE TRUE TRUE 2575
## for each address element key, get the unique set of types it takes on among all hashes, ignoring hashes where the key (only address_2 in this case) is omitted => all scalar strings
keyTypes(jsonRList,list(NULL,'addresses',NULL),allAddressKeys);
## key tl
## 1 address character[1]
## 2 city character[1]
## 3 state character[1]
## 4 zip character[1]
## 5 phone character[1]
## 6 address_2 character[1]
## ==== plans =====
## note: the plans key is always present under main array elements
## unique types of plan elements across all hashes => all named lists, thus nested hashes
unique(levelApplyToVec(jsonRList,list(NULL,'plans',NULL),tlStr));
## [1] "namedlist"
## union of keys among all plan element hashes
allPlanKeys <- unique(levelApplyToVec(jsonRList,list(NULL,'plans',NULL),names)); allPlanKeys;
## [1] "plan_id_type" "plan_id" "network_tier"
## pattern of keys among plan elements => good, all plan elements have all 3 keys, perfectly consistent
keyCombosWithCount(jsonRList,list(NULL,'plans',NULL),allPlanKeys);
## plan_id_type plan_id network_tier .count
## 1 TRUE TRUE TRUE 29304
## for each plan element key, get the unique set of types it takes on among all hashes (note: no plan keys are ever omitted, so don't have to worry about that) => all scalar strings
keyTypes(jsonRList,list(NULL,'plans',NULL),allPlanKeys);
## key tl
## 1 plan_id_type character[1]
## 2 plan_id character[1]
## 3 network_tier character[1]
## ==== name =====
## note: the name key is *not* always present under main array elements
## union of keys among all name hashes
allNameKeys <- unique(levelApplyToVec(jsonRList,list(NULL,'name'),names)); allNameKeys;
## [1] "first" "middle" "last"
## pattern of keys among name elements => sometimes middle is missing, relatively infrequently
keyCombosWithCount(jsonRList,list(NULL,'name'),allNameKeys);
## first middle last .count
## 1 TRUE TRUE TRUE 2679
## 2 TRUE FALSE TRUE 298
## for each name element key, get the unique set of types it takes on among all hashes, ignoring hashes where the key (only middle in this case) is omitted => all scalar strings
keyTypes(jsonRList,list(NULL,'name'),allNameKeys);
## key tl
## 1 first character[1]
## 2 middle character[1]
## 3 last character[1]
Вот мое резюме данных:
- один главный список верхнего уровня, длина 3256.
- каждый элемент - это хеш с несовместимыми наборами ключей. Всего по всем основным хэшам имеется 12 ключей с 3 наборами ключей.
- 6 значений хеш-функции - скалярные строки, 3 - строковые векторы переменной длины,
addressesсписок переменной длины,plansсписок всегда имеет длину 9 иnameэто хеш - каждый
addressesЭлемент списка представляет собой хеш с 5 или 6 ключами для скалярных строк,address_2быть противоречивым. - каждый
plansЭлемент списка представляет собой хеш с 3 ключами для скалярных строк, без несоответствий. - каждый
nameхэш имеетfirstа такжеlastно не всегдаmiddleскалярные струны.
Наиболее важным наблюдением здесь является то, что нет никаких типовых несоответствий между параллельными узлами (кроме пропусков и различий в длине). Это означает, что мы можем объединить все параллельные узлы в векторы без учета приведения типов. Мы можем сгладить все данные в двумерную структуру, если мы связываем столбцы с достаточно глубокими узлами, так что все столбцы соответствуют одному скалярному строковому узлу во входном списке.
Ниже мое решение. Обратите внимание, что это зависит от вспомогательных функций tl(), keyListToStr(), а также mkcsv() Я определил ранее.
##--------------------------------------
## solution
##--------------------------------------
## recursively traverse the list structure, building up a column at each leaf node
extractLevelColumns <- function(
nodes, ## current level node selection
..., ## additional arguments to data.frame()
keyList=list(), ## current key path under main list
sep=NULL, ## optional string separator on which to join multi-element vectors; if NULL, will leave as separate columns
mkname=function(keyList,maxLen) paste0(collapse='.',if (is.null(sep) && maxLen == 1L) keyList[-length(keyList)] else keyList) ## name builder from current keyList and character vector max length across node level; default to dot-separated keys, and remove last index component for scalars
) {
cat(sprintf('extractLevelColumns(): %s\n',keyListToStr(keyList)));
if (length(nodes) == 0L) return(list()); ## handle corner case of empty main list
tlList <- lapply(nodes,tl);
typeList <- do.call(c,lapply(tlList,`[[`,'type'));
if (length(unique(typeList)) != 1L) stop(sprintf('error: inconsistent types (%s) at %s.',mkcsv(typeList),keyListToStr(keyList)));
type <- typeList[1L];
if (type == 'namedlist') { ## hash; recurse
allKeys <- unique(do.call(c,lapply(nodes,names)));
ret <- do.call(c,lapply(allKeys,function(key) extractLevelColumns(lapply(nodes,`[[`,key),...,keyList=c(keyList,key),sep=sep,mkname=mkname)));
} else if (type == 'list') { ## array; recurse
lenList <- do.call(c,lapply(tlList,`[[`,'len'));
maxLen <- max(lenList,na.rm=T);
allIndexes <- seq_len(maxLen);
ret <- do.call(c,lapply(allIndexes,function(index) extractLevelColumns(lapply(nodes,function(node) if (length(node) < index) NULL else node[[index]]),...,keyList=c(keyList,index),sep=sep,mkname=mkname))); ## must be careful to guard out-of-bounds to NULL; happens automatically with string keys, but not with integer indexes
} else if (type%in%c('raw','logical','integer','double','complex','character')) { ## atomic leaf node; build column
lenList <- do.call(c,lapply(tlList,`[[`,'len'));
maxLen <- max(lenList,na.rm=T);
if (is.null(sep)) {
ret <- lapply(seq_len(maxLen),function(i) setNames(data.frame(sapply(nodes,function(node) if (length(node) < i) NA else node[[i]]),...),mkname(c(keyList,i),maxLen)));
} else {
## keep original type if maxLen is 1, IOW don't stringify
ret <- list(setNames(data.frame(sapply(nodes,function(node) if (length(node) == 0L) NA else if (maxLen == 1L) node else paste(collapse=sep,node)),...),mkname(keyList,maxLen)));
}; ## end if
} else stop(sprintf('error: unsupported type %s at %s.',type,keyListToStr(keyList)));
if (is.null(ret)) ret <- list(); ## handle corner case of exclusively empty sublists
ret;
}; ## end extractLevelColumns()
## simple interface function
flattenList <- function(mainList,...) do.call(cbind,extractLevelColumns(mainList,...));
extractLevelColumns() Функция пересекает входной список и извлекает все значения узлов в каждой позиции конечного узла, объединяя их в вектор с NA, где значение отсутствовало, и затем преобразовывая в data-frame из одного столбца. Имя столбца устанавливается сразу, используя параметризованный mkname() функция для определения строкового keyList на имя столбца строки. Несколько столбцов возвращаются в виде списка data.frames из каждого рекурсивного вызова, а также из вызова верхнего уровня.
Это также подтверждает, что между параллельными узлами нет несоответствий типов. Несмотря на то, что ранее я вручную проверял согласованность данных, я пытался написать как можно более универсальное и повторно используемое решение, потому что это всегда хорошая идея, поэтому этот этап проверки является подходящим.
flattenList() является основной интерфейсной функцией; это просто звонки extractLevelColumns() а потом do.call(cbind,...) объединить столбцы в один data.frame.
Преимущество этого решения в том, что оно полностью универсальное; он может обрабатывать неограниченное количество уровней глубины за счет полной рекурсии. Кроме того, он не имеет зависимостей пакета, параметризует логику построения имени столбца и пересылает переменные аргументы в data.frame()так, например, вы можете передать stringsAsFactors=F запретить автоматическую факторизацию символьных столбцов, обычно выполняемую data.frame()и / или row.names={namevector} установить имена строк результирующего data.frame, или row.names=NULL предотвратить использование имен компонентов списка верхнего уровня в качестве имен строк, если таковые существуют в списке ввода.
Я также добавил sep параметр по умолчанию NULL, Если NULLмногоэлементные конечные узлы будут разделены на несколько столбцов, по одному на элемент, с индексным суффиксом к имени столбца для дифференциации. В противном случае он считается разделителем строк, в котором все элементы объединяются в одну строку, и для узла создается только один столбец.
С точки зрения производительности, это очень быстро. Вот демо:
## actually run it
system.time({ df <- flattenList(jsonRList); });
## extractLevelColumns(): /
## extractLevelColumns(): /npi
## extractLevelColumns(): /type
## extractLevelColumns(): /facility_name
## extractLevelColumns(): /facility_type
## extractLevelColumns(): /addresses
## extractLevelColumns(): /addresses/1
## extractLevelColumns(): /addresses/1/address
## extractLevelColumns(): /addresses/1/city
##
## ... snip ...
##
## extractLevelColumns(): /plans/9/network_tier
## extractLevelColumns(): /last_updated_on
## extractLevelColumns(): /name
## extractLevelColumns(): /name/first
## extractLevelColumns(): /name/middle
## extractLevelColumns(): /name/last
## extractLevelColumns(): /speciality
## extractLevelColumns(): /accepting
## extractLevelColumns(): /languages
## extractLevelColumns(): /gender
## user system elapsed
## 2.265 0.000 2.268
Результат:
class(df); dim(df); names(df);
## [1] "data.frame"
## [1] 3256 126
## [1] "npi" "type" "facility_name" "facility_type.1" "facility_type.2" "facility_type.3" "addresses.1.address" "addresses.1.city" "addresses.1.state"
## [10] "addresses.1.zip" "addresses.1.phone" "addresses.1.address_2" "addresses.2.address" "addresses.2.city" "addresses.2.state" "addresses.2.zip" "addresses.2.phone" "addresses.2.address_2"
## [19] "addresses.3.address" "addresses.3.city" "addresses.3.state" "addresses.3.zip" "addresses.3.phone" "addresses.3.address_2" "addresses.4.address" "addresses.4.city" "addresses.4.state"
## [28] "addresses.4.zip" "addresses.4.phone" "addresses.4.address_2" "addresses.5.address" "addresses.5.address_2" "addresses.5.city" "addresses.5.state" "addresses.5.zip" "addresses.5.phone"
## [37] "addresses.6.address" "addresses.6.address_2" "addresses.6.city" "addresses.6.state" "addresses.6.zip" "addresses.6.phone" "addresses.7.address" "addresses.7.address_2" "addresses.7.city"
## [46] "addresses.7.state" "addresses.7.zip" "addresses.7.phone" "addresses.8.address" "addresses.8.address_2" "addresses.8.city" "addresses.8.state" "addresses.8.zip" "addresses.8.phone"
## [55] "addresses.9.address" "addresses.9.address_2" "addresses.9.city" "addresses.9.state" "addresses.9.zip" "addresses.9.phone" "addresses.10.address" "addresses.10.address_2" "addresses.10.city"
## [64] "addresses.10.state" "addresses.10.zip" "addresses.10.phone" "addresses.11.address" "addresses.11.address_2" "addresses.11.city" "addresses.11.state" "addresses.11.zip" "addresses.11.phone"
## [73] "addresses.12.address" "addresses.12.address_2" "addresses.12.city" "addresses.12.state" "addresses.12.zip" "addresses.12.phone" "addresses.13.address" "addresses.13.city" "addresses.13.state"
## [82] "addresses.13.zip" "addresses.13.phone" "plans.1.plan_id_type" "plans.1.plan_id" "plans.1.network_tier" "plans.2.plan_id_type" "plans.2.plan_id" "plans.2.network_tier" "plans.3.plan_id_type"
## [91] "plans.3.plan_id" "plans.3.network_tier" "plans.4.plan_id_type" "plans.4.plan_id" "plans.4.network_tier" "plans.5.plan_id_type" "plans.5.plan_id" "plans.5.network_tier" "plans.6.plan_id_type"
## [100] "plans.6.plan_id" "plans.6.network_tier" "plans.7.plan_id_type" "plans.7.plan_id" "plans.7.network_tier" "plans.8.plan_id_type" "plans.8.plan_id" "plans.8.network_tier" "plans.9.plan_id_type"
## [109] "plans.9.plan_id" "plans.9.network_tier" "last_updated_on" "name.first" "name.middle" "name.last" "speciality.1" "speciality.2" "speciality.3"
## [118] "speciality.4" "accepting" "languages.1" "languages.2" "languages.3" "languages.4" "languages.5" "languages.6" "gender"
Полученный data.frame довольно широкий, но мы можем использовать rowToFrame() а также npiToFrame() чтобы получить хорошее вертикальное расположение одного ряда за раз. Например, вот первый ряд:
rowToFrame(df[1L,]);
## column value
## 1 npi 1063645026
## 2 type FACILITY
## 3 facility_name EXPRESS SCRIPTS
## 4 facility_type.1 Pharmacies
## 5 facility_type.2 <NA>
## 6 facility_type.3 <NA>
## 7 addresses.1.address 4750 E 450 S
## 8 addresses.1.city WHITESTOWN
## 9 addresses.1.state IN
## 10 addresses.1.zip 46075
## 11 addresses.1.phone 2012695236
## 12 addresses.1.address_2 <NA>
## 13 addresses.2.address <NA>
## 14 addresses.2.city <NA>
## 15 addresses.2.state <NA>
## 16 addresses.2.zip <NA>
## 17 addresses.2.phone <NA>
## 18 addresses.2.address_2 <NA>
## 19 addresses.3.address <NA>
## 20 addresses.3.city <NA>
## 21 addresses.3.state <NA>
##
## ... snip ...
##
## 77 addresses.12.zip <NA>
## 78 addresses.12.phone <NA>
## 79 addresses.13.address <NA>
## 80 addresses.13.city <NA>
## 81 addresses.13.state <NA>
## 82 addresses.13.zip <NA>
## 83 addresses.13.phone <NA>
## 84 plans.1.plan_id_type HIOS-PLAN-ID
## 85 plans.1.plan_id 38344AK0620003
## 86 plans.1.network_tier HERITAGE-PLUS
## 87 plans.2.plan_id_type HIOS-PLAN-ID
## 88 plans.2.plan_id 38344AK0620004
## 89 plans.2.network_tier HERITAGE-PLUS
## 90 plans.3.plan_id_type HIOS-PLAN-ID
## 91 plans.3.plan_id 38344AK0620006
## 92 plans.3.network_tier HERITAGE-PLUS
## 93 plans.4.plan_id_type HIOS-PLAN-ID
## 94 plans.4.plan_id 38344AK0620008
## 95 plans.4.network_tier HERITAGE-PLUS
## 96 plans.5.plan_id_type HIOS-PLAN-ID
## 97 plans.5.plan_id 38344AK0570001
## 98 plans.5.network_tier HERITAGE-PLUS
## 99 plans.6.plan_id_type HIOS-PLAN-ID
## 100 plans.6.plan_id 38344AK0570002
## 101 plans.6.network_tier HERITAGE-PLUS
## 102 plans.7.plan_id_type HIOS-PLAN-ID
## 103 plans.7.plan_id 38344AK0980003
## 104 plans.7.network_tier HERITAGE-PLUS
## 105 plans.8.plan_id_type HIOS-PLAN-ID
## 106 plans.8.plan_id 38344AK0980006
## 107 plans.8.network_tier HERITAGE-PLUS
## 108 plans.9.plan_id_type HIOS-PLAN-ID
## 109 plans.9.plan_id 38344AK0980012
## 110 plans.9.network_tier HERITAGE-PLUS
## 111 last_updated_on 2015-10-14
## 112 name.first <NA>
## 113 name.middle <NA>
## 114 name.last <NA>
## 115 speciality.1 <NA>
## 116 speciality.2 <NA>
## 117 speciality.3 <NA>
## 118 speciality.4 <NA>
## 119 accepting <NA>
## 120 languages.1 <NA>
## 121 languages.2 <NA>
## 122 languages.3 <NA>
## 123 languages.4 <NA>
## 124 languages.5 <NA>
## 125 languages.6 <NA>
## 126 gender <NA>
Я довольно тщательно протестировал результат, выполнив много выборочных проверок отдельных записей, и все выглядит правильно. Дайте знать, если у вас появятся вопросы.
Этот ответ является скорее предложением организации данных (и он намного короче, чем ответы, привлекающие награды;)
Если вы хотите сохранить семантику полей, как сохранить все plan_idВ одном столбце вы можете немного нормализовать свой дизайн данных и впоследствии выполнять объединения, если вам нужна эта информация вместе:
library(dplyr)
# notice the simplifyVector=F
providers <- fromJSON( "http://fm.formularynavigator.com/jsonFiles/publish/11/47/providers.json", simplifyVector=F)
# pick and repeat fields for each element of array
# {field1:val, field2:val2, array:[{af1:av1, af2:av2}, {af1:av3, af2:av4}]}
# gives data.frame
# field1, field2 array.af1 array.af2
# val val2 av1 av2
# val val2 av3 av4
denormalize <- function(data, fields, array) {
data.frame(
c(
data[fields],
as.list(
bind_rows(
lapply(data[[array]], data.frame)))))
}
plans_df <- bind_rows(lapply(providers, denormalize, c('npi'), 'plans'))
addresses_df <- bind_rows(lapply(providers, denormalize, c('npi'), 'addresses'))
npis <- bind_rows(lapply(providers, function(d, fields) data.frame(d[fields]),
c('npi', 'type', 'last_updated_on')))
Затем вы можете сначала отфильтровать данные и впоследствии присоединиться к другой информации:
addresses_df %>%
filter(city == "Healy") %>%
left_join(plans_df, by="npi") ->
plans_in_healy
Так что это не совсем подходящее решение, поскольку оно не дает прямого ответа на вопрос, но вот как я буду анализировать эти данные.
Сначала я должен был понять ваш набор данных. Похоже, это информация о поставщиках медицинских услуг.
providers <- fromJSON( "http://fm.formularynavigator.com/jsonFiles/publish/11/47/providers.json" , simplifyDataFrame=FALSE )
types = sapply(providers,"[[","type")
table(types)
# FACILITY INDIVIDUAL
# 279 2977
FACILITYзаписи имеют поля "ID"facility_nameа такжеfacility_type,INDIVIDUALзаписи имеют поля "ID"name,speciality,accepting,languages, а такжеgender,- Все записи имеют поля "ID"
npiа такжеlast_updated_on, - Все записи имеют два вложенных поля:
addressesа такжеplans, Напримерaddressesэтоlistсодержит город, штат и т. д.
Поскольку есть несколько адресов для каждого npiЯ бы предпочел преобразовать их в фрейм данных со столбцами для города, штата и т. Д. Я также сделаю аналогичный фрейм данных для plans, Тогда я присоединюсь addresses а также plans в один фрейм данных. Следовательно, если имеется 4 адреса и 8 планов, в объединенном фрейме данных будет 4*8=32 строки. Наконец, я коснусь аналогично денормализованного фрейма данных с информацией "ID", используя другое слияние.
library(dplyr)
unfurl_npi_data = function (x) {
repeat_cols = c("plans","addresses")
id_cols = setdiff(names(x),repeat_cols)
repeat_data = x[repeat_cols]
id_data = x[id_cols]
# Denormalized ID data
id_data_df = Reduce(function(x,y) merge(x,y,by=NULL), id_data, "")[,-1]
atomic_colnames = names(which(!sapply(id_data, is.list)))
df_atomic_cols = unlist(sapply(id_data,function(x) if(is.list(x)) rep(FALSE, length(x)) else TRUE))
colnames(id_data_df)[df_atomic_cols] = atomic_colnames
# Join the plans and addresses (denormalized)
repeated_data = lapply(repeat_data, rbind_all)
repeated_data_crossed = Reduce(merge, repeated_data, repeated_data[[1]])
merge(id_data_df, repeated_data_crossed)
}
providers2 = split(providers, types)
providers3 = lapply(providers2, function(x) rbind_all(lapply(x, unfurl_npi_data)))
Тогда сделайте некоторую очистку.
unique_df = function(x) {
chr_col_names = names(which(sapply(x, class) == "character"))
for( col in chr_col_names )
x[[col]] = toupper(x[[col]])
unique(x)
}
providers3 = lapply(providers3, unique_df)
facilities = providers3[["FACILITY"]]
individuals = providers3[["INDIVIDUAL"]]
rm(providers, providers2, providers3)
А теперь вы можете задать несколько интересных вопросов. Например, сколько адресов имеет каждый поставщик медицинских услуг?
unique_providers = individuals %>% select(first, middle, last, gender, state, city, address) %>% unique()
num_addresses = unique_providers %>% count(first, middle, last, gender)
table(num_addresses$n)
# 1 2 3 4 5 6 7 8 9 12 13
# 2258 492 119 33 43 21 6 1 2 1 1
Каков процент мужчин, предоставляющих медицинские услуги, по адресам более пяти человек?
address_pcts = unique_providers %>%
group_by(address, city, state) %>%
filter(n()>5) %>%
arrange(address) %>%
summarise(pct_male = sum(gender=="MALE")/n())
library(ggplot2)
qplot(address_pcts$pct_male, binwidth=1/7) + xlim(0,1)

И так далее...