Есть ли существенная разница между UTF-8 и UTF-16?
Я вызываю веб-службу, которая возвращает мне ответный XML-файл с кодировкой UTF-8. Я проверил это в Java, используя getAllHeaders() метод.
Теперь, в своем коде Java, я беру этот ответ и затем выполняю некоторую обработку на нем. А позже передайте его другому сервису.
Теперь я немного погуглил и обнаружил, что по умолчанию в Java для строк используется кодировка UTF-16.
В моем ответе xml один из элементов имел символ É. Теперь это было ввернуто в запрос пост-обработки, который я делаю к другому сервису.
Вместо того, чтобы отправлять É, он отправлял какие-то нелепые вещи. Теперь я хотел бы знать, будет ли действительно большая разница в этих двух кодировках? И если бы я хотел знать, что É преобразует из UTF-8 в UTF-16, то как я могу это сделать?
Спасибо
4 ответа
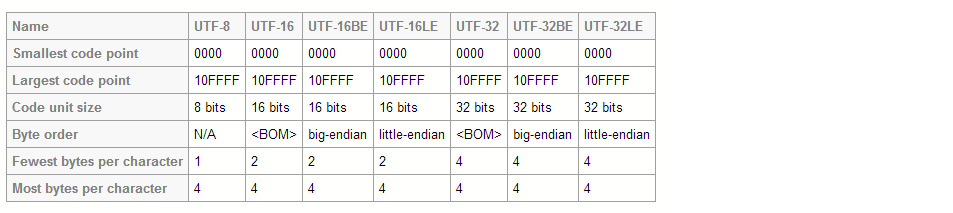 И UTF-8, и UTF-16 являются кодировками переменной длины. Однако в UTF-8 символ может занимать минимум 8 битов, тогда как в UTF-16 длина символа начинается с 16 битов.
И UTF-8, и UTF-16 являются кодировками переменной длины. Однако в UTF-8 символ может занимать минимум 8 битов, тогда как в UTF-16 длина символа начинается с 16 битов.
Основные плюсы UTF-8:
- Основные символы ASCII, такие как цифры, латинские символы без акцентов и т. Д., Занимают один байт, который идентичен представлению US-ASCII. Таким образом, все строки US-ASCII становятся действительными UTF-8, что обеспечивает приличную обратную совместимость во многих случаях.
- Отсутствие нулевых байтов, что позволяет использовать строки с нулевым символом в конце, что также обеспечивает большую обратную совместимость.
Основные минусы UTF-8:
- Многие обычные символы имеют разную длину, что ужасно замедляет индексацию и вычисление длины строки.
Основные плюсы UTF-16:
- Наиболее разумные символы, такие как латиница, кириллица, китайский, японский, могут быть представлены 2 байтами. Если не нужны действительно экзотические символы, это означает, что 16-битное подмножество UTF-16 может использоваться в качестве кодирования фиксированной длины, что ускоряет индексацию.
Основные минусы UTF-16:
- Много нулевых байтов в строках US-ASCII, что означает отсутствие строк с нулевым символом в конце и много потерянной памяти.
В общем, UTF-16 обычно лучше для представления в памяти, тогда как UTF-8 чрезвычайно хорош для текстовых файлов и сетевого протокола.
Есть две вещи:
- кодировка, в которой вы обмениваетесь данными;
- внутреннее строковое представление Java.
Вы не должны быть озабочены вторым пунктом;) Дело в том, чтобы использовать соответствующие методы для преобразования ваших данных (байтовые массивы) в String с (char массивы в конечном итоге), и преобразовать форму String с вашими данными.
Самые основные классы, о которых вы можете подумать: CharsetDecoder а также CharsetEncoder, Но есть много других. String.getBytes(), все Reader с и Writer Это всего лишь два возможных метода. И есть все статические методы Character также.
Если в какой-то момент вы видите тарабарщину, это означает, что вам не удалось декодировать или кодировать исходные байтовые данные в строки Java. Но опять же, тот факт, что строки Java используют UTF-16, здесь не имеет значения.
В частности, вы должны знать, что при создании Reader или же Writer, вы должны указать кодировку; если вы этого не сделаете, будет использоваться кодировка JVM по умолчанию, и это может быть или не быть UTF-8.
Этот сайт предоставляет UTF TO UTF конверсию
http://www.fileformat.info/convert/text/utf2utf.htm
UTF-32, пожалуй, самая удобочитаемая из форм Unicode Encoding Forms, потому что шестнадцатеричное представление с большим порядком байтов - это просто скалярное значение Unicode без префикса "U+", дополненное нулями до восьми цифр и в то время как представление UTF-32 делает сделать модель программирования несколько проще, увеличенный средний размер хранилища имеет реальные недостатки, что делает полный переход на UTF-32 менее привлекательным.
ТЕМ НЕ МЕНИЕ
UTF-32 - то же самое, что и старое кодирование UCS-4, и остается фиксированной ширины. Почему это может оставаться фиксированной шириной? Поскольку теперь UTF-16 является форматом, который может кодировать наименьшее количество символов, он устанавливает ограничение для всех форматов. Было определено, что 1 112 064 было общим числом кодовых точек, которые когда-либо будут определены либо Unicode, либо ISO 10646. Поскольку Unicode теперь определяется только от 0 до 10FFFF, UTF-32 звучит немного как бессмысленное кодирование сейчас, так как его ширина 32 бита, но используется только 21 бит, что делает это очень расточительным.
UTF-8: Вообще говоря, вы должны использовать UTF-8. В большинстве HTML-документов используется эта кодировка.
Он использует не менее 8 бит данных для хранения каждого символа. Это может привести к более эффективному хранению, особенно когда текст содержит в основном английские символы ASCII. Но для символов более высокого порядка, таких как символы, отличные от ASCII, может потребоваться до 24 бит для каждого!
UTF-16: эта кодировка использует не менее 16 бит для кодирования символов, включая символы ASCII более низкого порядка и символы не ASCII более высокого порядка.
Если вы кодируете текст, состоящий в основном из неанглийских или не-ASCII символов, UTF-16 может привести к уменьшению размера файла. Но если вы используете UTF-16 для кодирования в основном текста ASCII, он займет больше места.