Максимальный размер локальной памяти потока потока графического процессора (C++ AMP)
Я хотел бы создать целочисленный массив из 100 и еще один из ~10-100 целых чисел (зависит от ввода пользователя) в каждом потоке. Я буду повторно использовать данные в array_views несколько раз в потоке, поэтому я хочу скопировать содержимое aray view в качестве локальных данных, чтобы увеличить время доступа к памяти. (Каждый поток отвечает за свои "собственные" 100 элементов array_view, создание одного потока для каждого элемента с моим алгоритмом невозможно). Если это невозможно, то статическая память тайлов тоже подойдет, но поток локальный будет будь лучше.
Мой вопрос: сколько байтов я могу выделить в потоке как локальную переменную / массив (минимальное количество, которое будет работать на большинстве графических процессоров)? Кроме того, с помощью какого программного обеспечения я могу запрашивать возможности моего графического процессора (количество регистров на поток, размер статической памяти на плитку и т. Д.) В CUDA SDK есть служебное приложение, которое запрашивает возможности графического процессора, но у меня есть AMD один, Radeon HD 5770, и он не будет работать с моим графическим процессором, если я прав.
1 ответ
Opencl api может запрашивать устройства gpu или cpu о возможностях программ opencl, но результаты должны быть одинаковыми для любой нативно оптимизированной структуры. Но если ваш C++ AMP основан на HLSL или аналогичном, вы не сможете использовать LDS.
32 КБ LDS и постоянный кэш 24 КБ на вычислительную единицу означает, что при выборе 32 потоков на вычислительную единицу вы можете иметь 1 КБ LDS + 0,75 КБ на поток. Но водители могут использовать некоторые из них для других целей, вы всегда можете проверить для разных размеров. Посмотрите на постоянную пропускную способность кэша, его удвоенную производительность LDS bw.
Если вы используете эти массивы без совместного использования с другими потоками (или без какой-либо синхронизации), вы можете использовать регистровое пространство 256 КБ на вычислительную единицу (8 КБ на поток (настройка 32 потока на куб.)) С пропускной способностью в шесть раз большей, чем у LDS. Но всегда есть некоторые ограничения, поэтому фактическая полезная стоимость может составлять половину этого.
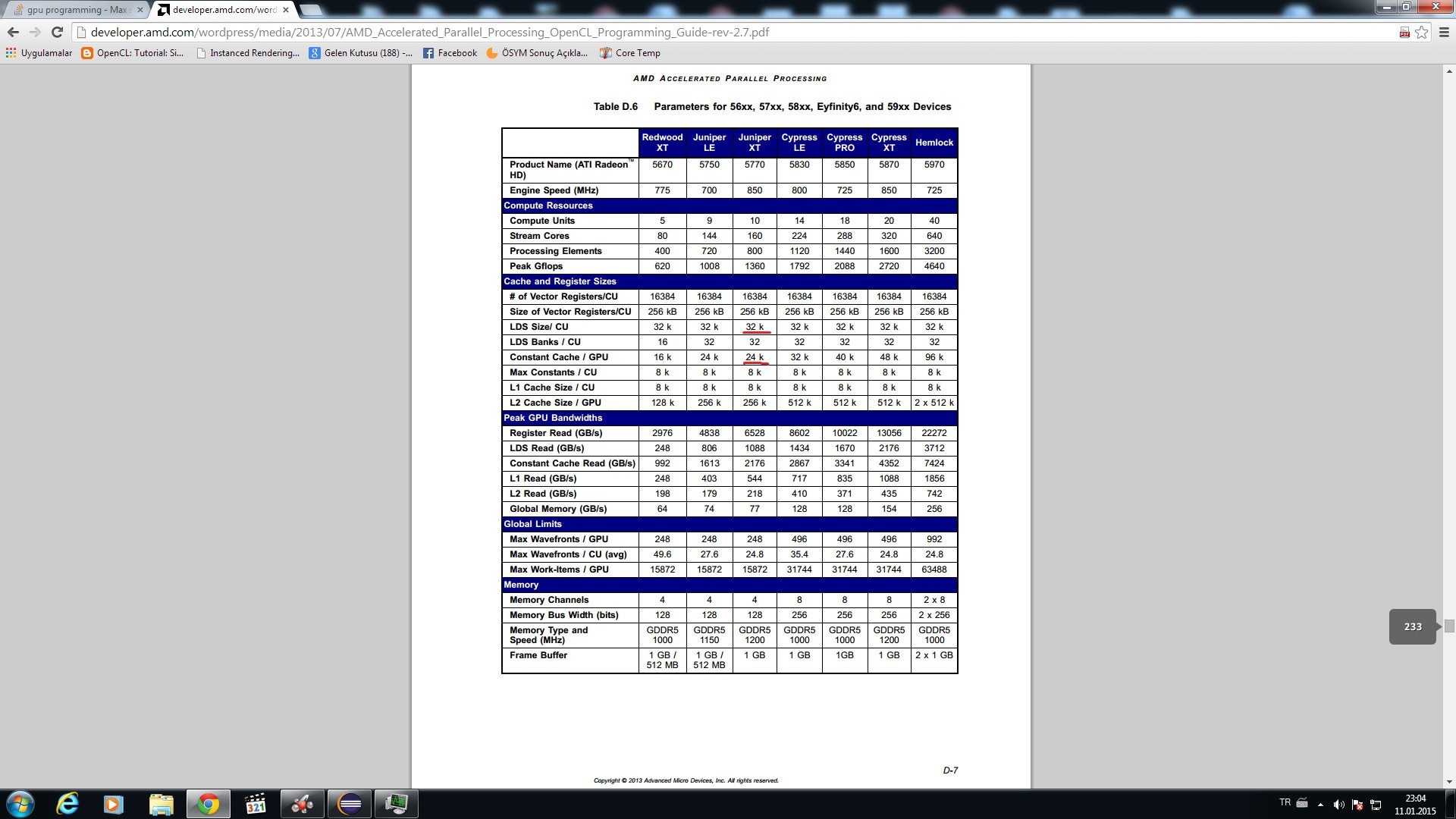
взято из приложения - d из http://developer.amd.com/wordpress/media/2013/07/AMD_Accelerated_Parallel_Processing_OpenCL_Programming_Guide-rev-2.7.pdf