Как посчитать вхождение определенного элемента в ndarray в Python?
В Python у меня есть ndarray yэто напечатано как array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
Я пытаюсь посчитать сколько 0и сколько 1s есть в этом массиве.
Но когда я печатаю y.count(0) или же y.count(1)это говорит
numpy.ndarrayобъект не имеет атрибутаcount
Что я должен делать?
32 ответа
>>> a = numpy.array([0, 3, 0, 1, 0, 1, 2, 1, 0, 0, 0, 0, 1, 3, 4])
>>> unique, counts = numpy.unique(a, return_counts=True)
>>> dict(zip(unique, counts))
{0: 7, 1: 4, 2: 1, 3: 2, 4: 1}
Не бесшумный способ:
использование collections.Counter;
>> import collections, numpy
>>> a = numpy.array([0, 3, 0, 1, 0, 1, 2, 1, 0, 0, 0, 0, 1, 3, 4])
>>> collections.Counter(a)
Counter({0: 7, 1: 4, 3: 2, 2: 1, 4: 1})
Как насчет использования numpy.count_nonzero, что-то вроде
>>> import numpy as np
>>> y = np.array([1, 2, 2, 2, 2, 0, 2, 3, 3, 3, 0, 0, 2, 2, 0])
>>> np.count_nonzero(y == 1)
1
>>> np.count_nonzero(y == 2)
7
>>> np.count_nonzero(y == 3)
3
Лично я бы пошел на:(y == 0).sum() а также (y == 1).sum()
Например
import numpy as np
y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
num_zeros = (y == 0).sum()
num_ones = (y == 1).sum()
Для вашего случая вы также можете посмотреть на numpy.bincount
In [56]: a = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
In [57]: np.bincount(a)
Out[57]: array([8, 4]) #count of zeros is at index 0 : 8
#count of ones is at index 1 : 4
y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
Если вы знаете, что они просто 0 а также 1:
np.sum(y)
дает вам количество единиц. np.sum(1-y) дает нули.
Для небольшой общности, если вы хотите посчитать 0 а не ноль (но возможно 2 или 3):
np.count_nonzero(y)
дает число ненулевое.
Но если вам нужно что-то более сложное, я не думаю, что Numpy обеспечит хороший count вариант. В этом случае перейдите в коллекции:
import collections
collections.Counter(y)
> Counter({0: 8, 1: 4})
Это ведет себя как диктат
collections.Counter(y)[0]
> 8
Конвертировать ваш массив y к списку l а затем сделать l.count(1) а также l.count(0)
>>> y = numpy.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
>>> l = list(y)
>>> l.count(1)
4
>>> l.count(0)
8
Если вы точно знаете, какой номер вы ищете, вы можете использовать следующее;
lst = np.array([1,1,2,3,3,6,6,6,3,2,1])
(lst == 2).sum()
возвращает, сколько раз 2 произошло в вашем массиве.
Честно говоря, мне проще всего преобразовать его в серию панд или DataFrame:
import pandas as pd
import numpy as np
df = pd.DataFrame({'data':np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])})
print df['data'].value_counts()
Или эта милая строчка, предложенная Робертом Мюлом:
pd.Series([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1]).value_counts()
Никто не предложил использовать numpy.bincount(input, minlength) с minlength = np.size(input), но, похоже, это хорошее решение и, безусловно, самое быстрое:
In [1]: choices = np.random.randint(0, 100, 10000)
In [2]: %timeit [ np.sum(choices == k) for k in range(min(choices), max(choices)+1) ]
100 loops, best of 3: 2.67 ms per loop
In [3]: %timeit np.unique(choices, return_counts=True)
1000 loops, best of 3: 388 µs per loop
In [4]: %timeit np.bincount(choices, minlength=np.size(choices))
100000 loops, best of 3: 16.3 µs per loop
Это безумное ускорение между numpy.unique(x, return_counts=True) а также numpy.bincount(x, minlength=np.max(x))!
Если вас интересует максимально быстрое выполнение, вы заранее знаете, какое значение (а) искать, и ваш массив - 1D, или вас иным образом интересует результат в сглаженном массиве (в этом случае вход функции должен быть np.flatten(arr) а не просто arr), тогда Нумба ваш друг:
import numba as nb
@nb.jit
def count_nb(arr, value):
result = 0
for x in arr:
if x == value:
result += 1
return result
или для очень больших массивов, где может быть полезно распараллеливание:
@nb.jit(parallel=True)
def count_nbp(arr, value):
result = 0
for i in nb.prange(arr.size):
if arr[i] == value:
result += 1
return result
Сравнение их с np.count_nonzero() (который также имеет проблему создания временного массива, которого можно избежать) и np.unique()-основное решение
import numpy as np
def count_np(arr, value):
return np.count_nonzero(arr == value)
import numpy as np
def count_np2(arr, value):
uniques, counts = np.unique(a, return_counts=True)
counter = dict(zip(uniques, counts))
return counter[value] if value in counter else 0
для ввода, созданного с помощью:
def gen_input(n, a=0, b=100):
return np.random.randint(a, b, n)
получаются следующие графики (вторая строка графиков - увеличенное изображение для более быстрого подхода):
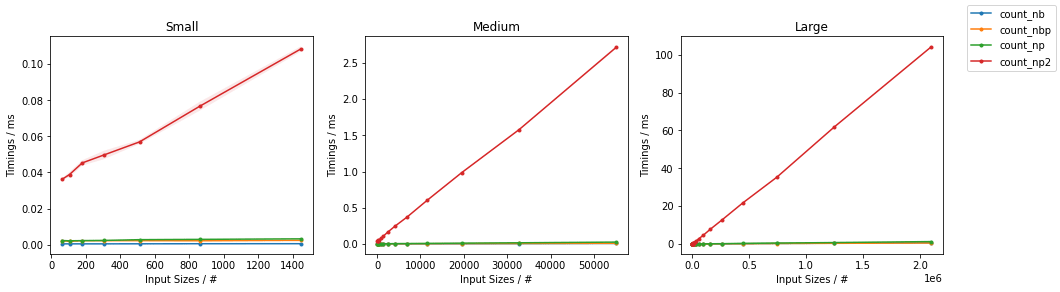
Показано, что решение на основе Numba заметно быстрее, чем аналоги NumPy, а для очень больших входных данных параллельный подход быстрее, чем наивный.
Полный код доступен здесь.
Для подсчета количества вхождений вы можете использовать np.unique(array, return_counts=True):
In [75]: boo = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
# use bool value `True` or equivalently `1`
In [77]: uniq, cnts = np.unique(boo, return_counts=1)
In [81]: uniq
Out[81]: array([0, 1]) #unique elements in input array are: 0, 1
In [82]: cnts
Out[82]: array([8, 4]) # 0 occurs 8 times, 1 occurs 4 times
Я бы использовал np.where:
how_many_0 = len(np.where(a==0.)[0])
how_many_1 = len(np.where(a==1.)[0])
y.tolist().count(val)
с val 0 или 1
Так как список питонов имеет встроенную функцию countПреобразование в список перед использованием этой функции является простым решением.
Попробуй это:
a = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
list(a).count(1)
Еще одним простым решением может быть использование numpy.count_nonzero ():
import numpy as np
y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
y_nonzero_num = np.count_nonzero(y==1)
y_zero_num = np.count_nonzero(y==0)
y_nonzero_num
4
y_zero_num
8
Не позволяйте имени вводить вас в заблуждение, если вы используете его с логическим значением, как в примере, это поможет.
Использовать методы, предлагаемые серией:
>>> import pandas as pd
>>> y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
>>> pd.Series(y).value_counts()
0 8
1 4
dtype: int64
Вы можете использовать словарное понимание, чтобы создать аккуратную однострочную строку. Больше о понимании словаря можно найти здесь
>>>counts = {int(value): list(y).count(value) for value in set(y)}
>>>print(counts)
{0: 8, 1: 4}
Это создаст словарь со значениями в вашем ndarray в качестве ключей и подсчетом значений в качестве значений для ключей соответственно.
Это будет работать всякий раз, когда вы хотите посчитать вхождения значения в массивах этого формата.
У вас есть специальный массив только с 1 и 0 здесь. Так что хитрость заключается в использовании
np.mean(x)
который дает вам процент 1 с в вашем массиве. В качестве альтернативы используйте
np.sum(x)
np.sum(1-x)
даст вам абсолютное число 1 и 0 в вашем массиве.
dict(zip(*numpy.unique(y, return_counts=True)))
Просто скопировал здесь комментарий Сеппо Энарви, который заслуживает правильного ответа.
Для общих записей:
x = np.array([11, 2, 3, 5, 3, 2, 16, 10, 10, 3, 11, 4, 5, 16, 3, 11, 4])
n = {i:len([j for j in np.where(x==i)[0]]) for i in set(x)}
ix = {i:[j for j in np.where(x==i)[0]] for i in set(x)}
Будет выводить счет:
{2: 2, 3: 4, 4: 2, 5: 2, 10: 2, 11: 3, 16: 2}
И показатели:
{2: [1, 5],
3: [2, 4, 9, 14],
4: [11, 16],
5: [3, 12],
10: [7, 8],
11: [0, 10, 15],
16: [6, 13]}
Общий и простой ответ будет:
numpy.sum(MyArray==x) # sum of a binary list of the occurence of x (=0 or 1) in MyArray
что привело бы к этому полному коду в качестве примера
import numpy
MyArray=numpy.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1]) # array we want to search in
x=0 # the value I want to count (can be iterator, in a list, etc.)
numpy.sum(MyArray==0) # sum of a binary list of the occurence of x in MyArray
Теперь, если MyArray находится в нескольких измерениях, и вы хотите посчитать возникновение распределения значений в строке (= образец в дальнейшем)
MyArray=numpy.array([[6, 1],[4, 5],[0, 7],[5, 1],[2, 5],[1, 2],[3, 2],[0, 2],[2, 5],[5, 1],[3, 0]])
x=numpy.array([5,1]) # the value I want to count (can be iterator, in a list, etc.)
temp = numpy.ascontiguousarray(MyArray).view(numpy.dtype((numpy.void, MyArray.dtype.itemsize * MyArray.shape[1]))) # convert the 2d-array into an array of analyzable patterns
xt=numpy.ascontiguousarray(x).view(numpy.dtype((numpy.void, x.dtype.itemsize * x.shape[0]))) # convert what you search into one analyzable pattern
numpy.sum(temp==xt) # count of the searched pattern in the list of patterns
Он включает еще один шаг, но более гибкое решение, которое также будет работать для 2d-массивов и более сложных фильтров, состоит в создании логической маски и последующем использовании.sum() для маски.
>>>>y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
>>>>mask = y == 0
>>>>mask.sum()
8
Эта функция возвращает количество вхождений переменной в массиве:
def count(array,variable):
number = 0
for i in range(array.shape[0]):
for j in range(array.shape[1]):
if array[i,j] == variable:
number += 1
return number
Поскольку ваш ndarray содержит только 0 и 1, вы можете использовать sum(), чтобы получить вхождение 1s, и len()-sum(), чтобы получить вхождение 0s.
num_of_ones = sum(array)
num_of_zeros = len(array)-sum(array)
Это можно легко сделать следующим способом
y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
y.tolist().count(1)
Если вы имеете дело с очень большими массивами, использование генераторов может быть вариантом. Приятно то, что этот подход отлично работает как для массивов, так и для списков, и вам не нужен дополнительный пакет. Кроме того, вы не используете столько памяти.
my_array = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
sum(1 for val in my_array if val==0)
Out: 8
Вот у меня есть кое-что, с помощью которого вы можете посчитать количество вхождений того или иного числа: по вашему коду
count_of_zero= список (y[y==0]).count(0)
печать (count_of_zero)
// в соответствии с совпадением будут логические значения, а в соответствии со значением True будет возвращено число 0
Самый простой, комментируйте если не надо
import numpy as np
y = np.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1])
count_0, count_1 = 0, 0
for i in y_train:
if i == 0:
count_0 += 1
if i == 1:
count_1 += 1
count_0, count_1
Если вы не хотите использовать numpy или модуль коллекций, вы можете использовать словарь:
d = dict()
a = [0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1]
for item in a:
try:
d[item]+=1
except KeyError:
d[item]=1
результат:
>>>d
{0: 8, 1: 4}
Конечно, вы также можете использовать оператор if/else. Я думаю, что функция Counter делает почти то же самое, но это более прозрачно.