numpy и statsmodels дают разные значения при расчете корреляций. Как это интерпретировать?
Я не могу найти причину, почему вычисление корреляции между двумя сериями A и B, используя numpy.correlate дает мне другие результаты, чем те, которые я получаю с помощью statsmodels.tsa.stattools.ccf
Вот пример этой разницы, о которой я упоминаю:
import numpy as np
from matplotlib import pyplot as plt
from statsmodels.tsa.stattools import ccf
#Calculate correlation using numpy.correlate
def corr(x,y):
result = numpy.correlate(x, y, mode='full')
return result[result.size/2:]
#This are the data series I want to analyze
A = np.array([np.absolute(x) for x in np.arange(-1,1.1,0.1)])
B = np.array([x for x in np.arange(-1,1.1,0.1)])
#Using numpy i get this
plt.plot(corr(B,A))
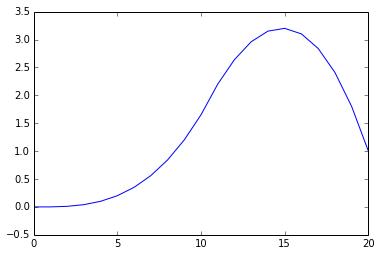
#Using statsmodels i get this
plt.plot(ccf(B,A,unbiased=False))
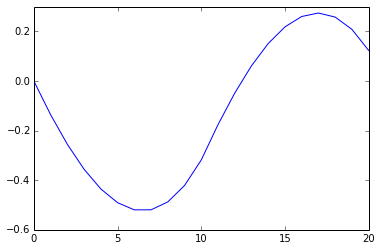
Результаты кажутся качественно различными, откуда эта разница?
1 ответ
Решение
statsmodels.tsa.stattools.ccf основывается на np.correlate но делает некоторые дополнительные вещи, чтобы дать корреляцию в статистическом смысле вместо смысла обработки сигнала, см. взаимную корреляцию в Википедии. Что именно происходит, вы можете увидеть в исходном коде, это очень просто.
Для удобства я скопировал соответствующие строки ниже:
def ccovf(x, y, unbiased=True, demean=True):
n = len(x)
if demean:
xo = x - x.mean()
yo = y - y.mean()
else:
xo = x
yo = y
if unbiased:
xi = np.ones(n)
d = np.correlate(xi, xi, 'full')
else:
d = n
return (np.correlate(xo, yo, 'full') / d)[n - 1:]
def ccf(x, y, unbiased=True):
cvf = ccovf(x, y, unbiased=unbiased, demean=True)
return cvf / (np.std(x) * np.std(y))