Как игнорировать первый элемент в Groupby в Scala /Spark?
Я использую Spark2, Zeppelin и Scala, чтобы показать 10 лучших вхождений слов в наборе данных. Мой код:
z.show(dfFlat.groupBy("value").count().sort(desc("count")), 10)
дает: 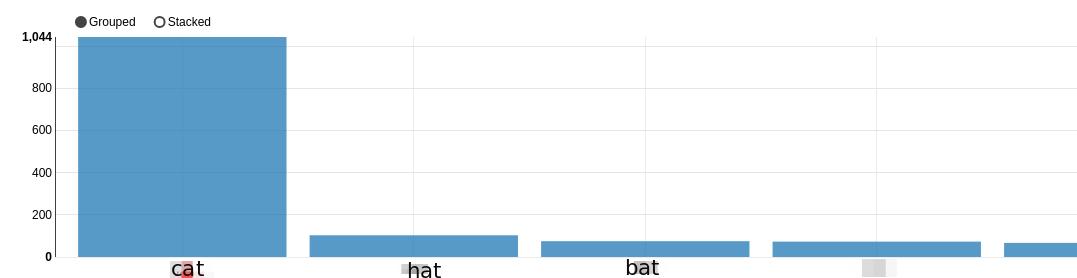 Как мне проигнорировать "кошку" и сделать так, чтобы сюжет начинался с "шляпы", т.е. показывал элементы со второго по последний?
Как мне проигнорировать "кошку" и сделать так, чтобы сюжет начинался с "шляпы", т.е. показывал элементы со второго по последний?
Я старался:
z.show(dfFlat.groupBy("value").count().sort(desc("count")).slice(2,4), 10)
но это дает:
error: value slice is not a member of org.apache.spark.sql.Dataset[org.apache.spark.sql.Row]
2 ответа
Решение
Не просто удалить первую строку в кадре данных (см. также Удаление первой строки Spark DataFrame). Но вы можете сделать это с помощью оконных функций:
val df = Seq(
"cat", "cat", "cat", "hat", "hat", "bat"
).toDF("value")
val dfGrouped = df
.groupBy($"value").count()
.sort($"count".desc)
dfGrouped.show()
+-----+-----+
|value|count|
+-----+-----+
| cat| 3|
| hat| 2|
| bat| 1|
+-----+-----+
val dfWithoutFirstRow = dfGrouped
.withColumn("rank", dense_rank().over(Window.partitionBy().orderBy($"count".desc)))
.where($"rank" =!= 1).drop($"rank") // this filters "cat"
.sort($"count".desc)
dfWithoutFirstRow
.show()
+-----+-----+
|value|count|
+-----+-----+
| hat| 2|
| bat| 1|
+-----+-----+
Первый ряд можно удалить таким образом:
val filteredValue = dfGrouped.first.get(0)
val result = dfGrouped.filter(s"value!='$filteredValue'")