Где находится официальная документация для T-SQL "ORDER BY RAND()" и "ORDER BY NEWID()"?
Я ищу официальную документацию T-SQL для "ORDER BY RAND()" и "ORDER BY NEWID()". Есть множество статей, описывающих их, поэтому они должны быть где-то задокументированы.
Я ищу ссылку на официальную страницу документации по SQL Server, например: http://technet.microsoft.com/en-us/library/ms188385.aspx
ПОЯСНЕНИЯ:
Что я ищу, так это документация для "order_by_expression", которая объясняет разницу в поведении между неотрицательной целочисленной константой, функцией, которая возвращает неотрицательное целое число, и функцией, которая возвращает любое другое значение (например, RAND () или NEWID()).
ОТВЕТ:
Я прошу прощения за отсутствие ясности в моем первоначальном вопросе. Как и в случае с большинством проблем, связанных с программированием, решение проблемы заключается прежде всего в выяснении того, на какой вопрос вы действительно пытаетесь ответить.
Всем спасибо.
Ответ в этом документе: От: http://www.wiscorp.com/sql200n.zip
Information technology — Database languages — SQL — Part 2: Foundation (SQL/Foundation)
22.2 <direct select statement: multiple rows> includes a <cursor specification>.
На данный момент у нас есть первая половина ответа:
Утверждение SELECT является типом CURSOR, что означает, что операции могут выполняться итеративно в каждой строке. Несмотря на то, что я не нашел в документах утверждения о том, что это объясняется явным объяснением, я согласен предположить, что выражение в порядке_объявления будет выполняться для каждой строки.
Теперь имеет смысл, что происходит, когда вы используете RAND () или NEWID () или CEILING(RAND() + .5) / 2, а не числовую константу или имя столбца.
Выражение никогда не будет рассматриваться как номер столбца. Это всегда будет значение, которое генерируется для каждой строки, которое будет использоваться в качестве основы для определения порядка строк.
Однако для полноты давайте продолжим полное определение того, каким может быть выражение.
14.3 <cursor specification> includes ORDER BY <sort specification list>.
10.10 <sort specification list> defines:
<sort specification> ::= <sort key> [ <ordering specification> ] [ <null ordering> ]
<sort key> ::= <value expression>
<ordering specification> ::= ASC | DESC
<null ordering> ::= NULLS FIRST | NULLS LAST
Что приводит нас к:
6.25 <value expression>
Где мы находим вторую половину ответа:
<value expression> ::=
<common value expression>
| <boolean value expression>
| <row value expression>
<common value expression> ::=
<numeric value expression>
| <string value expression>
| <datetime value expression>
| <interval value expression>
| <user-defined type value expression>
| <reference value expression>
| <collection value expression>
<user-defined type value expression> ::= <value expression primary>
<reference value expression> ::= <value expression primary>
<collection value expression> ::= <array value expression> | <multiset value expression>
Отсюда мы опускаемся до многочисленных возможных типов выражений, которые можно использовать.
NEWID () возвращает уникальный идентификатор.
Представляется разумным предположить, что уникальные идентификаторы сравниваются численно, поэтому, если выражением является NEWID (), нашим <выражением общего значения> будет <выражение числового значения>.
Точно так же RAND () возвращает числовое значение, и оно также будет оцениваться как <выражение числового значения>.
Итак, хотя я не смог найти в официальной документации Microsoft ничего, что объясняет, что делает ORDER BY при вызове с использованием выражения order_by_expression, это действительно задокументировано, как я и знал, что должно быть.
3 ответа
Если вы пытаетесь определить, почему они ведут себя по-разному, причина проста: один оценивается один раз и рассматривается как постоянная времени выполнения (RAND()), а другой оценивается для каждой строки (NEWID()). Посмотрите на этот простой пример:
SELECT TOP (5) RAND(), NEWID() FROM sys.objects;
Результаты:
0.240705716465209 8D5D2B55-E5DE-4FF9-BA84-BC82F37B8F3A
0.240705716465209 C4CBF1CA-E6D0-4076-B6A6-5048EA612048
0.240705716465209 9BFAE5BB-B5B9-47DE-B8F9-77AAEFA5F9DB
0.240705716465209 89FFD8A1-AC73-4CEB-A5C0-00A76D040382
0.240705716465209 BCC89923-735E-43B3-9ECA-622A8C98AD7D
Теперь, если вы примените порядок к левому столбцу, SQL Server скажет, хорошо, но все значения одинаковы, поэтому я просто игнорирую ваш запрос и перехожу к следующему столбцу ORDER BY. Если его нет, SQL Server по умолчанию будет возвращать строки в любом порядке, который он считает наиболее эффективным.
Если вы примените порядок к правому столбцу, теперь SQL Server фактически должен отсортировать все значения. Это вводит Sort (или TopN Sort если TOP используется оператор) в план, и, вероятно, будет занимать больше ЦП (хотя общая продолжительность может не быть существенно затронута, в зависимости от размера набора и других факторов).
Давайте сравним планы для этих двух запросов:
SELECT RAND() FROM sys.all_columns ORDER BY RAND();
План:
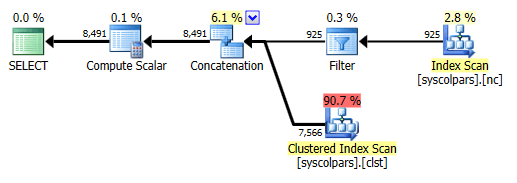
Оператор сортировки не выполняется, и оба сканирования Ordered = False - это означает, что SQL Server не решил явно реализовать какой-либо порядок, но это, конечно , не означает, что порядок будет отличаться при каждом выполнении - это просто означает, что порядок является недетерминированным (если вы не добавите вторичный ORDER BY - но даже в этом случае RAND() порядок все еще игнорируется, потому что, ну, это одинаковое значение в каждой строке).
И сейчас NEWID():
SELECT NEWID() FROM sys.all_columns ORDER BY NEWID();
План:
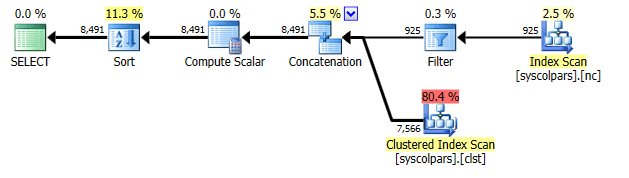
Есть новый Sort оператор там, что означает, что SQL Server должен переупорядочить все строки, которые должны быть возвращены в порядке сгенерированных значений GUID для каждой строки. Сканы, конечно, все еще неупорядочены, но Sort в конечном итоге применяется порядок.
Я не знаю, что эта конкретная деталь реализации где-либо официально документирована, хотя я нашел эту статью, которая включает в себя явный ORDER BY NEWID(), Я сомневаюсь, что вы найдете что-нибудь официальное, что документы ORDER BY RAND() в любом случае, потому что это просто бессмысленно делать, официально поддерживается или нет.
Re: комментарий, который назначает SQL Server a seed value at random - это не должно быть истолковано как a seed value **per row** at random, Демонстрация:
SELECT MAX(r), MIN(r) FROM
(
SELECT RAND() FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
) AS x(r);
Результаты:
0.4866202638872 0.4866202638872
На моей машине это заняло около 15 секунд, и результаты всегда были одинаковыми для обоих MIN а также MAX, Продолжайте увеличивать количество возвращаемых строк и количество времени, которое требуется, и я гарантирую, что вы будете продолжать видеть то же самое значение для RAND() на каждом ряду. Он рассчитывается ровно один раз, и это не потому, что SQL Server мудр к тому, что я не возвращаю все строки. Это также дало тот же результат (и на заполнение всей таблицы 72 миллионами строк ушло чуть менее 2 минут):
SELECT RAND() AS r INTO #x
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
CROSS JOIN sys.all_columns AS s3;
SELECT MAX(r), MIN(r) FROM #x;
(На самом деле SELECT заняло почти столько же времени, сколько первоначальное население. Не пытайтесь сделать это на одноядерном ноутбуке с 4 ГБ ОЗУ.)
Результат:
0.302690214345828 0.302690214345828
Проверьте ссылки ниже.
ORDER BY, RAND и NEWID являются частью операторов и функций языка TSQL.
Объединение их для случайного выбора или генерации данных - это шаблон проектирования.
Смотрите первые две статьи.
Генерация случайных целых чисел без столкновений
http://www.sqlperformance.com/2013/09/t-sql-queries/random-collisions
MSDN - случайный выбор строк из большой таблицы
http://msdn.microsoft.com/en-us/library/cc441928.aspx
MSDN - RAND
http://technet.microsoft.com/en-us/library/ms177610.aspx
MSDN - NEWID
http://msdn.microsoft.com/fr-fr/library/ms190348.aspx
MSDN - ЗАКАЗАТЬ ПО
http://technet.microsoft.com/en-us/library/ms188385.aspx
Очень хорошо читаю Аарона.
Но опять же, взятые отдельно (RAND, NEWID, ORDER BY) являются элементами языка TSQL.
Использование их для случайного выбора данных - это шаблон проектирования.
Также вы можете вызвать RAND() в цикле while - RBAR() выдает случайные числа.
Это связано с тем, что в плане запроса RAND() больше не является константой.
-- RBAR solution
declare @x float = 0;
declare @y int = 0;
while (@y < 100)
begin
set @x = rand();
print @x;
set @y += 1;
end;
go

Если мы настаиваем на деталях, вопрос, который вы задали, был, по сути, "Где документы для ~". Ответ - нигде, нет документа, подобного тому, который вы ищете.
В любом случае, не один, есть несколько документов, которые обрабатывают NEWID(), RAND() и ORDER BY по отдельности, и вы должны собрать их вместе.
В принципе,
- ORDER BY может принимать выражение для *order_by_expression*.
- Выражения http://technet.microsoft.com/en-us/library/ms190286.aspx включают скалярные функции
- RAND () и NEWID () являются функциями
Это позволяет вам знать, что это правильный синтаксис, но нет единой ссылки, на которую вы могли бы указать.