Как объединить два словаря в одном выражении?
У меня есть два словаря Python, и я хочу написать одно выражение, которое возвращает эти два словаря, объединенные. update() Метод был бы тем, что мне нужно, если бы он возвратил свой результат вместо того, чтобы изменить диктат на месте.
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> z = x.update(y)
>>> print(z)
None
>>> x
{'a': 1, 'b': 10, 'c': 11}
Как я могу получить этот последний объединенный диктат в zне x?
(Для большей ясности, обработка конфликта "последний-один-победитель" dict.update() это то, что я тоже ищу.)
68 ответов
Как я могу объединить два словаря Python в одном выражении?
Для словарей x а также y, z становится мелко объединенным словарем со значениями из y заменяя те из x,
В Python 3.5 или выше:
z = {**x, **y}В Python 2 (или 3.4 или ниже) напишите функцию:
def merge_two_dicts(x, y): z = x.copy() # start with x's keys and values z.update(y) # modifies z with y's keys and values & returns None return zи сейчас:
z = merge_two_dicts(x, y)
объяснение
Скажем, у вас есть два диктата, и вы хотите объединить их в новый, не изменяя исходные:
x = {'a': 1, 'b': 2}
y = {'b': 3, 'c': 4}
Желаемый результат - получить новый словарь (z) с объединенными значениями, а значения второго dict перезаписывают значения из первого.
>>> z
{'a': 1, 'b': 3, 'c': 4}
Новый синтаксис для этого, предложенный в PEP 448 и доступный с Python 3.5,
z = {**x, **y}
И это действительно единственное выражение.
Обратите внимание, что мы можем объединить и с буквенной нотацией:
z = {**x, 'foo': 1, 'bar': 2, **y}
и сейчас:
>>> z
{'a': 1, 'b': 3, 'foo': 1, 'bar': 2, 'c': 4}
Теперь он показывает, как реализовано в графике выпуска 3.5, PEP 478, и теперь он появился в документе " Что нового в Python 3.5".
Тем не менее, поскольку многие организации все еще используют Python 2, вы можете сделать это обратно совместимым образом. Классически Pythonic способ, доступный в Python 2 и Python 3.0-3.4, состоит в том, чтобы сделать это как двухэтапный процесс:
z = x.copy()
z.update(y) # which returns None since it mutates z
В обоих подходах y придет вторым и его значения заменит x ценности, таким образом 'b' будет указывать на 3 в нашем конечном результате.
Еще не на Python 3.5, но хочу одно выражение
Если вы еще не используете Python 3.5 или вам нужно написать обратно совместимый код, и вы хотите, чтобы это было в одном выражении, самый эффективный и правильный подход - поместить его в функцию:
def merge_two_dicts(x, y):
"""Given two dicts, merge them into a new dict as a shallow copy."""
z = x.copy()
z.update(y)
return z
и тогда у вас есть одно выражение:
z = merge_two_dicts(x, y)
Вы также можете создать функцию для слияния неопределенного числа диктовок от нуля до очень большого числа:
def merge_dicts(*dict_args):
"""
Given any number of dicts, shallow copy and merge into a new dict,
precedence goes to key value pairs in latter dicts.
"""
result = {}
for dictionary in dict_args:
result.update(dictionary)
return result
Эта функция будет работать в Python 2 и 3 для всех диктов. например, данные диктанты a в g:
z = merge_dicts(a, b, c, d, e, f, g)
и пары ключ-значение в g будет иметь приоритет над диктовками a в f, и так далее.
Критика других ответов
Не используйте то, что вы видите в ранее принятом ответе:
z = dict(x.items() + y.items())
В Python 2 вы создаете два списка в памяти для каждого dict, создаете третий список в памяти с длиной, равной длине первых двух вместе взятых, а затем отбрасываете все три списка для создания dict. В Python 3 это не удастся, потому что вы добавляете два dict_items объекты вместе, а не два списка -
>>> c = dict(a.items() + b.items())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'dict_items' and 'dict_items'
и вам придется явно создавать их в виде списков, например, z = dict(list(x.items()) + list(y.items())), Это пустая трата ресурсов и вычислительной мощности.
Точно так же, принимая союз items() в питоне 3 (viewitems() в Python 2.7) также потерпит неудачу, когда значения являются не подлежащими изменению объектами (например, списками). Даже если ваши значения являются хэшируемыми, поскольку наборы семантически неупорядочены, поведение не определено в отношении приоритета. Так что не делай этого:
>>> c = dict(a.items() | b.items())
Этот пример демонстрирует, что происходит, когда значения не различимы:
>>> x = {'a': []}
>>> y = {'b': []}
>>> dict(x.items() | y.items())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
Вот пример, где у должен иметь приоритет, но вместо этого значение из x сохраняется из-за произвольного порядка множеств:
>>> x = {'a': 2}
>>> y = {'a': 1}
>>> dict(x.items() | y.items())
{'a': 2}
Еще один хак, который вы не должны использовать:
z = dict(x, **y)
Это использует dict конструктор, и он очень быстрый и эффективный в использовании памяти (даже немного больше, чем наш двухэтапный процесс), но если вы точно не знаете, что здесь происходит (то есть второй dict передается в качестве аргументов ключевого слова в конструктор dict), это трудно читать, это не предполагаемое использование, и поэтому это не Pythonic.
Вот пример использования исправления в django.
Dicts предназначены для получения хешируемых ключей (например, frozensets или кортежей), но этот метод не работает в Python 3, когда ключи не являются строками.
>>> c = dict(a, **b)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: keyword arguments must be strings
Из списка рассылки создатель языка Гвидо ван Россум написал:
Я согласен с объявлением dict({}, **{1:3}) незаконным, поскольку в конце концов это злоупотребление ** механизмом.
а также
По-видимому, dict(x, **y) используется как "крутой хак" для "вызова x.update(y) и возврата x". Лично я нахожу это более презренным, чем крутым.
Это мое понимание (а также понимание создателя языка), что предполагаемое использование для dict(**y) предназначен для создания диктовок в целях читабельности, например:
dict(a=1, b=10, c=11)
вместо
{'a': 1, 'b': 10, 'c': 11}
Ответ на комментарии
Несмотря на то, что говорит Гвидо,
dict(x, **y)соответствует спецификации dict, что кстати. работает как для Python 2, так и для 3. Тот факт, что это работает только для строковых ключей, является прямым следствием того, как работают параметры ключевых слов, а не коротким переходом к dict. Также использование оператора ** в этом месте не является злоупотреблением механизмом, фактически ** был разработан именно для передачи слов в качестве ключевых слов.
Опять же, это не работает для 3, когда ключи не являются строками. Неявный контракт вызова заключается в том, что пространства имен принимают обычные диктовки, в то время как пользователи должны передавать только ключевые аргументы, которые являются строками. Все другие призывные силы принуждали его. dict нарушил эту последовательность в Python 2:
>>> foo(**{('a', 'b'): None})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: foo() keywords must be strings
>>> dict(**{('a', 'b'): None})
{('a', 'b'): None}
Это несоответствие было плохим, учитывая другие реализации Python (Pypy, Jython, IronPython). Таким образом, это было исправлено в Python 3, так как это использование может быть серьезным изменением.
Я утверждаю, что это злонамеренная некомпетентность - намеренно писать код, который работает только в одной версии языка или работает только при определенных произвольных ограничениях.
Больше комментариев:
dict(x.items() + y.items())до сих пор является наиболее читаемым решением для Python 2. Читаемость имеет значение.
Мой ответ: merge_two_dicts(x, y) на самом деле кажется мне намного понятнее, если мы действительно обеспокоены читаемостью. И это не совместимо с форвардом, так как Python 2 все более и более устарел.
{**x, **y}похоже не обрабатывает вложенные словари. содержимое вложенных ключей просто перезаписывается, а не сливается [...]. В итоге я сгорел от этих ответов, которые не сливаются рекурсивно, и я был удивлен, что никто не упомянул об этом. В моей интерпретации слова "слияние" эти ответы описывают "обновление одного диктанта другим", а не слияние.
Да. Я должен отослать вас обратно к вопросу, который требует поверхностного слияния двух словарей, причем значения первого перезаписываются значениями второго - в одном выражении.
Предполагая два словаря словарей, один может рекурсивно объединить их в одну функцию, но вы должны быть осторожны, чтобы не изменять указания из любого источника, и самый надежный способ избежать этого - сделать копию при назначении значений. Поскольку ключи должны быть хэшируемыми и, следовательно, обычно неизменяемыми, копировать их бессмысленно:
from copy import deepcopy
def dict_of_dicts_merge(x, y):
z = {}
overlapping_keys = x.keys() & y.keys()
for key in overlapping_keys:
z[key] = dict_of_dicts_merge(x[key], y[key])
for key in x.keys() - overlapping_keys:
z[key] = deepcopy(x[key])
for key in y.keys() - overlapping_keys:
z[key] = deepcopy(y[key])
return z
Использование:
>>> x = {'a':{1:{}}, 'b': {2:{}}}
>>> y = {'b':{10:{}}, 'c': {11:{}}}
>>> dict_of_dicts_merge(x, y)
{'b': {2: {}, 10: {}}, 'a': {1: {}}, 'c': {11: {}}}
Решение непредвиденных обстоятельств для других типов значений выходит далеко за рамки этого вопроса, поэтому я укажу вам на мой ответ на канонический вопрос "Словари слияния словарей".
Менее производительный, но правильный Ad-hocs
Эти подходы менее эффективны, но они обеспечат правильное поведение. Они будут намного менее производительными, чем copy а также update или новая распаковка, потому что они перебирают каждую пару ключ-значение на более высоком уровне абстракции, но они уважают порядок приоритета (последние диктанты имеют приоритет)
Вы также можете связать слова вручную в их понимании:
{k: v for d in dicts for k, v in d.items()} # iteritems in Python 2.7
или в Python 2.6 (и, возможно, уже в 2.4, когда были введены выражения генератора):
dict((k, v) for d in dicts for k, v in d.items())
itertools.chain объединит итераторы в пары ключ-значение в правильном порядке:
import itertools
z = dict(itertools.chain(x.iteritems(), y.iteritems()))
Анализ производительности
Я собираюсь провести анализ производительности только тех случаев, когда известно, что они ведут себя правильно.
import timeit
Следующее сделано в Ubuntu 14.04
В Python 2.7 (система Python):
>>> min(timeit.repeat(lambda: merge_two_dicts(x, y)))
0.5726828575134277
>>> min(timeit.repeat(lambda: {k: v for d in (x, y) for k, v in d.items()} ))
1.163769006729126
>>> min(timeit.repeat(lambda: dict(itertools.chain(x.iteritems(), y.iteritems()))))
1.1614501476287842
>>> min(timeit.repeat(lambda: dict((k, v) for d in (x, y) for k, v in d.items())))
2.2345519065856934
В Python 3.5 (deadsnakes PPA):
>>> min(timeit.repeat(lambda: {**x, **y}))
0.4094954460160807
>>> min(timeit.repeat(lambda: merge_two_dicts(x, y)))
0.7881555100320838
>>> min(timeit.repeat(lambda: {k: v for d in (x, y) for k, v in d.items()} ))
1.4525277839857154
>>> min(timeit.repeat(lambda: dict(itertools.chain(x.items(), y.items()))))
2.3143140770262107
>>> min(timeit.repeat(lambda: dict((k, v) for d in (x, y) for k, v in d.items())))
3.2069112799945287
Ресурсы по словарям
- Мое объяснение реализации словаря Python, обновлено для 3.6.
- Ответ о том, как добавить новые ключи в словарь
- Отображение двух списков в словарь
- Официальные документы Python по словарям
- Словарь еще могущественнее - выступление Брэндона Роудса на Pycon 2017
- Современные словари Python, слияние великих идей - выступление Рэймонда Хеттингера на Pycon 2017
В вашем случае вы можете сделать следующее:
z = dict(x.items() + y.items())
Это, как вы хотите, поставит окончательный zи сделать значение для ключа b быть правильно переопределенным вторым (y) значение dict:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> z = dict(x.items() + y.items())
>>> z
{'a': 1, 'c': 11, 'b': 10}
Если вы используете Python 3, это будет немного сложнее. Создавать z:
>>> z = dict(list(x.items()) + list(y.items()))
>>> z
{'a': 1, 'c': 11, 'b': 10}
Другой, более краткий вариант:
z = dict(x, **y)
Примечание: это стало популярным ответом, но важно отметить, что если y имеет любые нестроковые ключи, тот факт, что это работает вообще, является злоупотреблением деталями реализации CPython, и он не работает в Python 3, или в PyPy, IronPython или Jython. Кроме того, Гвидо не фанат. Поэтому я не могу рекомендовать эту технику для совместимого с прямым переносом кода или переносимого кода для перекрестной реализации, что на самом деле означает, что его следует полностью избегать
Это, вероятно, не будет популярным ответом, но вы почти наверняка не хотите этого делать. Если вы хотите копию, которая является слиянием, то используйте копию (или глубокую копию, в зависимости от того, что вы хотите), а затем обновите. Две строки кода гораздо более читабельны - более Pythonic - чем создание одной строки с помощью.items() + .items(). Явное лучше, чем неявное.
Кроме того, когда вы используете.items () (до Python 3.0), вы создаете новый список, содержащий элементы из dict. Если ваши словари большие, то это очень много накладных расходов (два больших списка, которые будут выброшены, как только будет создан объединенный диктат). update () может работать более эффективно, потому что он может проходить через второй элемент dict элемент за элементом.
С точки зрения времени:
>>> timeit.Timer("dict(x, **y)", "x = dict(zip(range(1000), range(1000)))\ny=dict(zip(range(1000,2000), range(1000,2000)))").timeit(100000)
15.52571702003479
>>> timeit.Timer("temp = x.copy()\ntemp.update(y)", "x = dict(zip(range(1000), range(1000)))\ny=dict(zip(range(1000,2000), range(1000,2000)))").timeit(100000)
15.694622993469238
>>> timeit.Timer("dict(x.items() + y.items())", "x = dict(zip(range(1000), range(1000)))\ny=dict(zip(range(1000,2000), range(1000,2000)))").timeit(100000)
41.484580039978027
ИМО крошечное замедление между первыми двумя стоит его для удобочитаемости. Кроме того, ключевые аргументы для создания словаря были добавлены только в Python 2.3, тогда как copy () и update () будут работать в более старых версиях.
В последующем ответе вы спросили об относительной эффективности этих двух альтернатив:
z1 = dict(x.items() + y.items())
z2 = dict(x, **y)
На моей машине, по крайней мере (довольно обычный x86_64 с Python 2.5.2), альтернатива z2 не только короче и проще, но и значительно быстрее. Вы можете убедиться в этом сами, используя timeit модуль, который поставляется с Python.
Пример 1: идентичные словари, отображающие 20 последовательных целых чисел на себя:
% python -m timeit -s 'x=y=dict((i,i) for i in range(20))' 'z1=dict(x.items() + y.items())'
100000 loops, best of 3: 5.67 usec per loop
% python -m timeit -s 'x=y=dict((i,i) for i in range(20))' 'z2=dict(x, **y)'
100000 loops, best of 3: 1.53 usec per loop
z2 выигрывает в 3,5 раза или около того. Различные словари, кажется, дают совершенно разные результаты, но z2 всегда кажется впереди. (Если вы получили противоречивые результаты для одного и того же теста, попробуйте передать -r с номером больше, чем по умолчанию 3.)
Пример 2: неперекрывающиеся словари, отображающие 252 короткие строки в целые числа и наоборот:
% python -m timeit -s 'from htmlentitydefs import codepoint2name as x, name2codepoint as y' 'z1=dict(x.items() + y.items())'
1000 loops, best of 3: 260 usec per loop
% python -m timeit -s 'from htmlentitydefs import codepoint2name as x, name2codepoint as y' 'z2=dict(x, **y)'
10000 loops, best of 3: 26.9 usec per loop
z2 выигрывает примерно в 10 раз. Это довольно большая победа в моей книге!
После сравнения этих двух, я подумал, z1 Низкая производительность может быть объяснена накладными расходами на создание двух списков элементов, что, в свою очередь, заставило меня задуматься, может ли этот вариант работать лучше:
from itertools import chain
z3 = dict(chain(x.iteritems(), y.iteritems()))
Несколько быстрых тестов, например
% python -m timeit -s 'from itertools import chain; from htmlentitydefs import codepoint2name as x, name2codepoint as y' 'z3=dict(chain(x.iteritems(), y.iteritems()))'
10000 loops, best of 3: 66 usec per loop
привести меня к выводу, что z3 несколько быстрее чем z1, но не так быстро, как z2, Определенно не стоит всего лишнего набора текста.
В этом обсуждении по-прежнему отсутствует что-то важное, а именно сравнение производительности этих альтернатив с "очевидным" способом объединения двух списков: использование update метод. Чтобы попытаться удержать вещи в равных условиях с выражениями, ни одно из которых не изменяет x или y, я собираюсь сделать копию x вместо ее изменения на месте, как показано ниже:
z0 = dict(x)
z0.update(y)
Типичный результат:
% python -m timeit -s 'from htmlentitydefs import codepoint2name as x, name2codepoint as y' 'z0=dict(x); z0.update(y)'
10000 loops, best of 3: 26.9 usec per loop
Другими словами, z0 а также z2 похоже, по существу идентичны производительности. Как вы думаете, это может быть совпадением? Я не....
На самом деле, я бы даже сказал, что для чистого кода Python невозможно добиться большего, чем этот. И если вы можете значительно улучшить работу модуля расширения C, я думаю, что пользователи Python вполне могут быть заинтересованы во включении вашего кода (или варианта вашего подхода) в ядро Python. Python использует dict во многих местах; Оптимизация его операций - это большое дело.
Вы также можете написать это как
z0 = x.copy()
z0.update(y)
как и Тони, но (что неудивительно) разница в обозначениях не оказывает какого-либо ощутимого влияния на производительность. Используйте то, что подходит вам. Конечно, он абсолютно прав, указывая на то, что версия с двумя утверждениями гораздо легче понять.
В Python 3 вы можете использовать collection.ChainMap, который группирует несколько диктовок или других сопоставлений для создания единого обновляемого представления:
>>> from collections import ChainMap
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> z = ChainMap({}, y, x)
>>> for k, v in z.items():
print(k, '-->', v)
a --> 1
b --> 10
c --> 11
Я хотел что-то похожее, но с возможностью указать, как значения на дубликатах ключей были объединены, поэтому я взломал это (но не проверил это сильно). Очевидно, что это не одно выражение, но это единственный вызов функции.
def merge(d1, d2, merge_fn=lambda x,y:y):
"""
Merges two dictionaries, non-destructively, combining
values on duplicate keys as defined by the optional merge
function. The default behavior replaces the values in d1
with corresponding values in d2. (There is no other generally
applicable merge strategy, but often you'll have homogeneous
types in your dicts, so specifying a merge technique can be
valuable.)
Examples:
>>> d1
{'a': 1, 'c': 3, 'b': 2}
>>> merge(d1, d1)
{'a': 1, 'c': 3, 'b': 2}
>>> merge(d1, d1, lambda x,y: x+y)
{'a': 2, 'c': 6, 'b': 4}
"""
result = dict(d1)
for k,v in d2.iteritems():
if k in result:
result[k] = merge_fn(result[k], v)
else:
result[k] = v
return result
Рекурсивно / глубокое обновление диктанта
def deepupdate(original, update):
"""
Recursively update a dict.
Subdict's won't be overwritten but also updated.
"""
for key, value in original.iteritems():
if key not in update:
update[key] = value
elif isinstance(value, dict):
deepupdate(value, update[key])
return updateДемонстрация:
pluto_original = {
'name': 'Pluto',
'details': {
'tail': True,
'color': 'orange'
}
}
pluto_update = {
'name': 'Pluutoo',
'details': {
'color': 'blue'
}
}
print deepupdate(pluto_original, pluto_update)Выходы:
{
'name': 'Pluutoo',
'details': {
'color': 'blue',
'tail': True
}
}Спасибо Rednaw за правки.
Я проверил предложенное с помощью perfplot и обнаружил, что старый добрый
temp = x.copy()
temp.update(y)
это самое быстрое решение вместе с новым
x | y
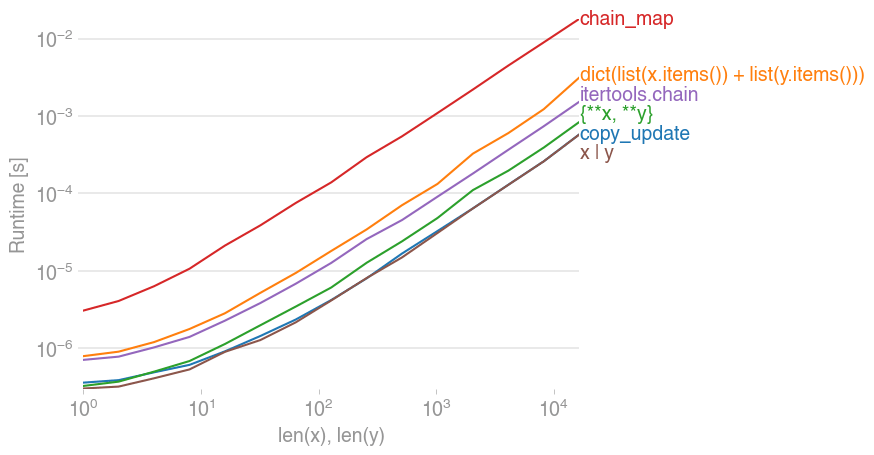
Код для воспроизведения сюжета:
from collections import ChainMap
from itertools import chain
import perfplot
def setup(n):
x = dict(zip(range(n), range(n)))
y = dict(zip(range(n, 2 * n), range(n, 2 * n)))
return x, y
def copy_update(data):
x, y = data
temp = x.copy()
temp.update(y)
return temp
def add_items(data):
x, y = data
return dict(list(x.items()) + list(y.items()))
def curly_star(data):
x, y = data
return {**x, **y}
def chain_map(data):
x, y = data
return dict(ChainMap({}, y, x))
def itertools_chain(data):
x, y = data
return dict(chain(x.items(), y.items()))
def python39_concat(data):
x, y = data
return x | y
perfplot.show(
setup=setup,
kernels=[
copy_update,
add_items,
curly_star,
chain_map,
itertools_chain,
python39_concat,
],
labels=[
"copy_update",
"dict(list(x.items()) + list(y.items()))",
"{**x, **y}",
"chain_map",
"itertools.chain",
"x | y",
],
n_range=[2 ** k for k in range(15)],
xlabel="len(x), len(y)",
equality_check=None,
)
Python 3.5 (PEP 448) допускает более приятную синтаксическую опцию:
x = {'a': 1, 'b': 1}
y = {'a': 2, 'c': 2}
final = {**x, **y}
final
# {'a': 2, 'b': 1, 'c': 2}
Или даже
final = {'a': 1, 'b': 1, **x, **y}
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
z = dict(x.items() + y.items())
print z
Для элементов с ключами в обоих словарях ('b') вы можете контролировать, какой из них окажется в выводе, поместив этот последний.
Лучшая версия, которую я мог бы подумать, не используя копию, была бы:
from itertools import chain
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
dict(chain(x.iteritems(), y.iteritems()))
Это быстрее чем dict(x.items() + y.items()) но не так быстро, как n = copy(a); n.update(b)по крайней мере на CPython. Эта версия также работает в Python 3, если вы измените iteritems() в items(), который автоматически выполняется инструментом 2to3.
Лично мне эта версия нравится больше всего, потому что она достаточно хорошо описывает то, что я хочу, в едином функциональном синтаксисе. Единственная незначительная проблема заключается в том, что не очевидно, что значения от y имеют приоритет над значениями от x, но я не верю, что это трудно понять.
Хотя на этот вопрос уже был дан ответ несколько раз, это простое решение проблемы еще не было перечислено.
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
z4 = {}
z4.update(x)
z4.update(y)
Это так же быстро, как z0 и зло z2, упомянутое выше, но легко понять и изменить.
def dict_merge(a, b):
c = a.copy()
c.update(b)
return c
new = dict_merge(old, extras)
Среди таких сомнительных и сомнительных ответов этот яркий пример - единственный и единственный хороший способ объединить диктанты в Python, одобренный диктатором на всю жизнь Гвидо ван Россумом! Кто-то предложил половину этого, но не включил его в работу.
print dict_merge(
{'color':'red', 'model':'Mini'},
{'model':'Ferrari', 'owner':'Carl'})
дает:
{'color': 'red', 'owner': 'Carl', 'model': 'Ferrari'}
Будьте питоничны. Используйте понимание:
z={i:d[i] for d in [x,y] for i in d}
>>> print z
{'a': 1, 'c': 11, 'b': 10}
Если вы думаете, что лямбды - это зло, не читайте дальше. По запросу вы можете написать быстрое и эффективное для памяти решение с одним выражением:
x = {'a':1, 'b':2}
y = {'b':10, 'c':11}
z = (lambda a, b: (lambda a_copy: a_copy.update(b) or a_copy)(a.copy()))(x, y)
print z
{'a': 1, 'c': 11, 'b': 10}
print x
{'a': 1, 'b': 2}
Как предложено выше, лучше всего использовать две строки или написать функцию.
В python3 items Метод больше не возвращает список, а скорее представление, которое действует как набор. В этом случае вам нужно взять объединение множеств, так как + не будет работать:
dict(x.items() | y.items())
Для Python3-подобного поведения в версии 2.7, viewitems метод должен работать вместо items:
dict(x.viewitems() | y.viewitems())
В любом случае, я предпочитаю эту запись, так как кажется более естественным думать о ней как об операции объединения множеств, а не о конкатенации (как видно из заголовка).
Редактировать:
Еще пара баллов за Python 3. Во-первых, обратите внимание, что dict(x, **y) трюк не будет работать в Python 3, если ключи в y Строки
Кроме того, ответ Chainmap Рэймонда Хеттингера довольно элегантен, поскольку он может принимать в качестве аргументов произвольное количество диктов, но из документов выглядит так, будто он последовательно просматривает список всех диктов для каждого поиска:
Поиски последовательно выполняют поиск соответствующих отображений, пока не будет найден ключ.
Это может замедлить вас, если в вашем приложении много поисков:
In [1]: from collections import ChainMap
In [2]: from string import ascii_uppercase as up, ascii_lowercase as lo; x = dict(zip(lo, up)); y = dict(zip(up, lo))
In [3]: chainmap_dict = ChainMap(y, x)
In [4]: union_dict = dict(x.items() | y.items())
In [5]: timeit for k in union_dict: union_dict[k]
100000 loops, best of 3: 2.15 µs per loop
In [6]: timeit for k in chainmap_dict: chainmap_dict[k]
10000 loops, best of 3: 27.1 µs per loop
Так что примерно на порядок медленнее для поисков. Я фанат Chainmap, но выглядит менее практичным там, где может быть много поисков.
Два словаря
def union2(dict1, dict2):
return dict(list(dict1.items()) + list(dict2.items()))
русский словарь
def union(*dicts):
return dict(itertools.chain.from_iterable(dct.items() for dct in dicts))
sum имеет плохую производительность. Смотрите https://mathieularose.com/how-not-to-flatten-a-list-of-lists-in-python/
Простое решение с использованием itertools, сохраняющее порядок (последние имеют приоритет)
import itertools as it
merge = lambda *args: dict(it.chain.from_iterable(it.imap(dict.iteritems, args)))
И это использование:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> merge(x, y)
{'a': 1, 'b': 10, 'c': 11}
>>> z = {'c': 3, 'd': 4}
>>> merge(x, y, z)
{'a': 1, 'b': 10, 'c': 3, 'd': 4}
Злоупотребление, приводящее к решению с одним выражением для ответа Мэтью:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> z = (lambda f=x.copy(): (f.update(y), f)[1])()
>>> z
{'a': 1, 'c': 11, 'b': 10}
Вы сказали, что хотели одно выражение, поэтому я оскорбил lambda связать имя и кортежи, чтобы переопределить лямбда-ограничение в одно выражение. Не стесняйтесь съеживаться.
Конечно, вы также можете сделать это, если не хотите копировать это:
>>> x = {'a':1, 'b': 2}
>>> y = {'b':10, 'c': 11}
>>> z = (x.update(y), x)[1]
>>> z
{'a': 1, 'b': 10, 'c': 11}
Несмотря на то, что ответы были хорошими для этого мелкого словаря, ни один из методов, определенных здесь, на самом деле не выполняет глубокое слияние словаря.
Примеры следуют:
a = { 'one': { 'depth_2': True }, 'two': True }
b = { 'one': { 'extra': False } }
print dict(a.items() + b.items())
Можно ожидать результата чего-то вроде этого:
{ 'one': { 'extra': False', 'depth_2': True }, 'two': True }
Вместо этого мы получаем это:
{'two': True, 'one': {'extra': False}}
Элемент 'one' должен был иметь значения 'deep_2' и 'extra' в качестве элементов внутри своего словаря, если это действительно слияние.
Использование цепочки также не работает:
from itertools import chain
print dict(chain(a.iteritems(), b.iteritems()))
Результаты в:
{'two': True, 'one': {'extra': False}}
Глубокое слияние, которое дал rcwesick, также создает тот же результат.
Да, это сработает для объединения образцов словарей, но ни один из них не является универсальным механизмом объединения. Я обновлю это позже, когда напишу метод, который выполняет истинное слияние.
Если вы не против мутировать x,
x.update(y) or x
Простой, читаемый, производительный. Вы знаете update() всегда возвращается None, который является ложным значением. Так что он всегда будет оценивать x,
Методы мутации в стандартной библиотеке, например update, вернуть None условно, так что этот трюк будет работать и на тех.
Если вы используете библиотеку, которая не следует этому соглашению, вы можете использовать отображение и индекс кортежа, чтобы сделать его одним выражением вместо or, но это не так читабельно.
(x.update(y), x)[-1]
Если у вас нет x в переменной еще можно использовать lambda сделать локальный без использования оператора присваивания. Это равносильно использованию lambda как выражение let, которое является обычной техникой в функциональных языках, но довольно непифоническим.
(lambda x: x.update(y) or x)({'a':1, 'b': 2})
Если вам нужна копия, лучше всего PEP 448 {**x, **y}, Но если это не доступно, пусть работает и здесь.
(lambda z: z.update(y) or z)(x.copy())
Новое в Python 3.9: используйте оператор объединения (|) объединить dicts похож на sets:
>>> d = {'a': 1, 'b': 2}
>>> e = {'a': 9, 'c': 3}
>>> d | e
{'a': 9, 'b': 2, 'c': 3}
Для совпадающих ключей правильныйdictимеет приоритет.
Это также работает для |= изменить dict на месте:
>>> e |= d # e = e | d
>>> e
{'a': 1, 'c': 3, 'b': 2}
Также возможно несколько соединений на линию:
>>> {'a': 1} | {'b': 2} | {'c': 3}
{'a': 1, 'b': 2, 'c': 3}
Может быть полезно для чего-то вроде module_defaults | user_defaults | user_arguments.
Опираясь на идеи здесь и в других местах, я понял функцию:
def merge(*dicts, **kv):
return { k:v for d in list(dicts) + [kv] for k,v in d.items() }
Использование (протестировано в Python 3):
assert (merge({1:11,'a':'aaa'},{1:99, 'b':'bbb'},foo='bar')==\
{1: 99, 'foo': 'bar', 'b': 'bbb', 'a': 'aaa'})
assert (merge(foo='bar')=={'foo': 'bar'})
assert (merge({1:11},{1:99},foo='bar',baz='quux')==\
{1: 99, 'foo': 'bar', 'baz':'quux'})
assert (merge({1:11},{1:99})=={1: 99})
Вы могли бы использовать лямбду вместо этого.
(Только для Python2.7*; для Python3* есть более простые решения.)
Если вы не против импортировать стандартный библиотечный модуль, вы можете сделать
from functools import reduce
def merge_dicts(*dicts):
return reduce(lambda a, d: a.update(d) or a, dicts, {})
(The or a немного в lambda необходимо, потому что dict.update всегда возвращается None на успех.)
Это так глупо, что .update ничего не возвращает.
Я просто использую простую вспомогательную функцию для решения проблемы:
def merge(dict1,*dicts):
for dict2 in dicts:
dict1.update(dict2)
return dict1
Примеры:
merge(dict1,dict2)
merge(dict1,dict2,dict3)
merge(dict1,dict2,dict3,dict4)
merge({},dict1,dict2) # this one returns a new copy
Благодаря PEP 572: Выражения назначения появится новая опция при выпуске Python 3.8 ( запланировано на 20 октября 2019 г.). Новый оператор выражения присваивания := позволяет назначить результат copy и до сих пор использовать его для вызова update оставляя объединенный код одним выражением, а не двумя, изменяя:
newdict = dict1.copy()
newdict.update(dict2)
чтобы:
(newdict := dict1.copy()).update(dict2)
при этом ведя себя одинаково во всех отношениях. Если вы также должны вернуть полученный dict (вы попросили выражение, возвращающее dict; вышесказанное создает и присваивает newdict, но не возвращает его, поэтому вы не можете использовать его для передачи аргумента функции как есть myfunc((newdict := dict1.copy()).update(dict2))), затем просто добавьте or newdict до конца (с update возвращается None, то есть ложь, то потом оценит и вернет newdict в результате выражения):
(newdict := dict1.copy()).update(dict2) or newdict
Важное предостережение: в целом, я бы не рекомендовал такой подход в пользу:
newdict = {**dict1, **dict2}
Подход к распаковке более понятен (для тех, кто в первую очередь знает об обобщенной распаковке, что вам следует), вообще не требует имени для результата (так что он гораздо более лаконичен при создании временного объекта, который немедленно передается функция или включена в list / tuple и т. д.), и почти наверняка быстрее, будучи (на CPython) примерно эквивалентным:
newdict = {}
newdict.update(dict1)
newdict.update(dict2)
но сделано на уровне С, используя бетон dict API, поэтому не требуются динамические поиск / привязка методов или служебные диспетчерские вызовы (где (newdict := dict1.copy()).update(dict2) неизбежно идентичен исходному двухстрочному поведению, выполняя работу дискретными шагами, с динамическим поиском / привязкой / вызовом методов.
Это также более расширяемый, так как объединение трех dict s очевидно:
newdict = {**dict1, **dict2, **dict3}
где использование выражений присваивания не будет так масштабироваться; самое близкое, что вы могли бы получить:
(newdict := dict1.copy()).update(dict2), newdict.update(dict3)
или без временного кортежа None с, но с проверкой правдивости каждого None результат:
(newdict := dict1.copy()).update(dict2) or newdict.update(dict3)
любой из которых, очевидно, намного уродливее, и включает в себя дальнейшую неэффективность (либо потерянный временный tuple из None s для разделения запятых, или бессмысленного проверки правдивости каждого update "s None вернуться за or разделение).
Единственное реальное преимущество в подходе выражения присваивания имеет место, если:
- У вас есть общий код, который должен обрабатывать оба
setс иdictс (оба поддерживаютcopyа такжеupdateпоэтому код работает примерно так, как вы ожидаете) - Вы ожидаете получить произвольные объекты типа dict, а не только
dictсам и должен сохранять тип и семантику левой стороны (а не заканчиваться простойdict). В то время какmyspecialdict({**speciala, **specialb})может сработать, это потребует дополнительных временныхdict, и еслиmyspecialdictимеет простые функцииdictне может сохранить (например, регулярноdicts теперь сохраняет порядок, основанный на первом появлении ключа, и значение, основанное на последнем появлении ключа; вам может потребоваться тот, который сохраняет порядок, основанный на последнем появлении ключа, поэтому обновление значения также перемещает его в конец), тогда семантика будет неправильной. Поскольку версия выражения присваивания использует именованные методы (которые предположительно перегружены для правильного поведения), она никогда не создаетdictвообще (еслиdict1был ужеdict), сохраняя исходный тип (и семантику исходного типа), избегая при этом любых временных.
from collections import Counter
dict1 = {'a':1, 'b': 2}
dict2 = {'b':10, 'c': 11}
result = dict(Counter(dict1) + Counter(dict2))
Это должно решить вашу проблему.
Проблема, с которой я столкнулся с решениями, перечисленными на сегодняшний день, заключается в том, что в объединенном словаре значение ключа "b" равно 10, но, по моему мнению, оно должно быть 12. В этом свете я представляю следующее:
import timeit
n=100000
su = """
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
"""
def timeMerge(f,su,niter):
print "{:4f} sec for: {:30s}".format(timeit.Timer(f,setup=su).timeit(n),f)
timeMerge("dict(x, **y)",su,n)
timeMerge("x.update(y)",su,n)
timeMerge("dict(x.items() + y.items())",su,n)
timeMerge("for k in y.keys(): x[k] = k in x and x[k]+y[k] or y[k] ",su,n)
#confirm for loop adds b entries together
x = {'a':1, 'b': 2}
y = {'b':10, 'c': 11}
for k in y.keys(): x[k] = k in x and x[k]+y[k] or y[k]
print "confirm b elements are added:",x
Результаты:
0.049465 sec for: dict(x, **y)
0.033729 sec for: x.update(y)
0.150380 sec for: dict(x.items() + y.items())
0.083120 sec for: for k in y.keys(): x[k] = k in x and x[k]+y[k] or y[k]
confirm b elements are added: {'a': 1, 'c': 11, 'b': 12}