В каком сценарии я использую определенный контейнер STL?
Я читал о контейнерах STL в моей книге по C++, в частности, о STL и его контейнерах. Теперь я понимаю, что у каждого из них есть свои специфические свойства, и я близок к тому, чтобы запомнить их все... Но я пока не понимаю, в каком сценарии используется каждый из них.
Какое объяснение? Пример кода гораздо предпочтительнее.
10 ответов
Этот шпаргалка предоставляет довольно хорошее резюме различных контейнеров.
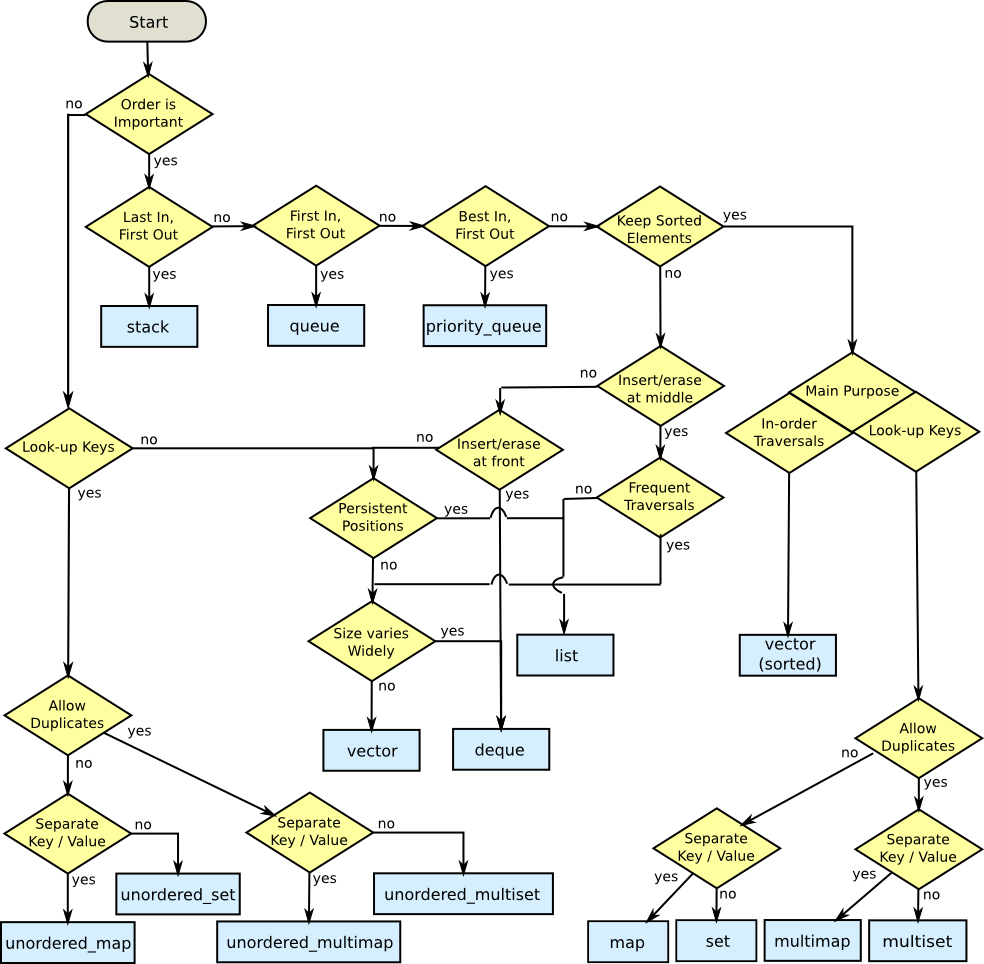
См. Блок-схему внизу как руководство по использованию в различных сценариях использования:

Создано Дэвидом Муром и лицензировано CC BY-SA 3.0
Вот блок-схема, вдохновленная созданной мной версией Дэвида Мура (см. Выше), которая соответствует (в основном) новому стандарту (C++11). Это только мое личное взятие на него, это не бесспорный, но я полагал, что это могло бы быть полезным для этой дискуссии:
Простой ответ: используйте std::vector за все, если у вас нет реальной причины поступить иначе.
Когда вы найдете случай, когда вы думаете: "Ну и дела, std::vector здесь плохо работает из-за X", иди на основе X.
Посмотрите на "Эффективный STL" Скотта Мейерса. Это хорошо объясняет, как использовать STL.
Если вы хотите сохранить определенное / неопределенное количество объектов и никогда не будете удалять их, тогда вам нужен вектор. Это замена по умолчанию для массива C, и он работает как один, но не переполняется. Вы также можете установить его размер заранее с помощью Reserve().
Если вы хотите сохранить неопределенное количество объектов, но вы будете добавлять и удалять их, то вам, вероятно, нужен список... потому что вы можете удалить элемент, не перемещая следующие элементы - в отличие от вектора. Однако он занимает больше памяти, чем вектор, и вы не можете последовательно получить доступ к элементу.
Если вы хотите взять кучу элементов и найти только уникальные значения этих элементов, чтение их всех в набор сделает это, и это также отсортирует их для вас.
Если у вас много пар ключ-значение, и вы хотите отсортировать их по ключу, тогда карта полезна... но она будет содержать только одно значение на ключ. Если вам нужно более одного значения для каждого ключа, вы можете использовать вектор / список в качестве значения на карте или использовать мультикарту.
Это не в STL, но в обновлении TR1 для STL: если у вас есть много пар ключ-значение, которые вы собираетесь искать по ключу, и вам не важен их порядок, вы можете хочу использовать хеш - это tr1::unordered_map. Я использовал его с Visual C++ 7.1, где он назывался stdext::hash_map. У него есть поиск O(1) вместо поиска O(log n) для map.
Я переработал блок-схему, чтобы иметь 3 свойства:
- Я думаю, что контейнеры STL разделены на 2 основных класса. Основные контейнеры и те используют основные контейнеры для реализации политики.
- Сначала блок-схема должна разделить процесс принятия решения на основные ситуации, в которых мы должны принять решение, а затем подробно остановиться на каждом конкретном случае.
- Некоторые расширенные контейнеры имеют возможность выбора другого базового контейнера в качестве своего внутреннего контейнера. Блок-схема должна учитывать ситуации, в которых может использоваться каждый из основных контейнеров.
Блок-схема: 
Более подробная информация предоставлена по этой ссылке.
Важным моментом, только кратко упомянутым, является то, что если вам требуется непрерывная память (как дает массив C), то вы можете использовать только vector, array, или же string,
использование array если размер известен во время компиляции.
использование string если вам нужно работать только с символьными типами и вам нужна строка, а не просто контейнер общего назначения.
использование vector во всех остальных случаях (vector в любом случае в большинстве случаев должен быть выбран контейнер по умолчанию).
Со всеми тремя из них вы можете использовать data() Функция-член для получения указателя на первый элемент контейнера.
Все зависит от того, что вы хотите хранить и что вы хотите делать с контейнером. Вот некоторые (очень не исчерпывающие) примеры для контейнерных классов, которые я обычно использую:
vector: Компактная компоновка с небольшим объемом памяти или без нее на каждый содержащийся объект. Эффективно перебирать. Добавить, вставить и стереть может быть дорого, особенно для сложных объектов. Дешево найти содержащийся объект по индексу, например, myVector[10]. Используйте там, где вы бы использовали массив в C. Хорошо, когда у вас много простых объектов (например, int). Не забудьте использовать reserve() перед добавлением большого количества объектов в контейнер.
listНебольшие накладные расходы памяти для каждого объекта. Эффективно перебирать. Добавить, вставить и стереть дешево. Используйте, где вы бы использовали связанный список в C.
set (а также multiset): Значительные накладные расходы памяти на каждый содержащийся объект. Используйте там, где вам нужно быстро выяснить, содержит ли этот контейнер данный объект, или эффективно объединить контейнеры.
map (а также multimap): Значительные накладные расходы памяти на каждый содержащийся объект. Используйте, где вы хотите хранить пары ключ-значение и быстро искать значения по ключу.
Блок-схема на шпаргалке, предложенная zdan, дает более исчерпывающее руководство.
Я ответил на это в другом вопросе, который помечен как дубликат этого. Но я чувствую, что приятно сослаться на несколько хороших статей, касающихся решения о выборе стандартного контейнера.
Как ответил @David Thornley, std::vector - это то, что нужно, если нет других особых потребностей. Это совет, данный создателем C++ Бьярном Страуструпом в блоге 2014 года.
Вот ссылка на статью https://isocpp.org/blog/2014/06/stroustrup-lists
и цитата из этого,
И да, я рекомендую использовать std:: vector по умолчанию.
В комментариях пользователь @NathanOliver также предоставляет еще один хороший блог, в котором есть более конкретные измерения. https://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html.
Один урок, который я усвоил: попытайтесь обернуть его в классе, поскольку изменение типа контейнера в один прекрасный день может принести большие сюрпризы.
class CollectionOfFoo {
Collection<Foo*> foos;
.. delegate methods specifically
}
Это не требует больших затрат и экономит время на отладку, когда вы хотите прервать работу, когда кто-то выполняет операцию x с этой структурой.
Приходя к выбору идеальной структуры данных для работы:
Каждая структура данных предоставляет несколько операций, которые могут быть различной временной сложности:
O (1), O (LG N), O (N) и т. Д.
По сути, вам нужно сделать предположение, какие операции будут выполняться чаще всего, и использовать структуру данных, которая имеет эту операцию как O(1).
Просто, не правда ли (-:
Я расширил фантастическую схему Mikael Persson. Я добавил несколько категорий контейнеров, контейнер массивов и некоторые заметки. Если вы хотите свою собственную копию, вот чертеж Google. Спасибо, Микаэль, за проделанную работу! Сборщик контейнеров C++