Что делает "vperm v0,v0,v0,v17" с неиспользованным v0?
Я работаю над реализацией SHA-256 с использованием встроенных модулей Power8. Производительность немного отключена. Я оцениваю это примерно на 2 цикла на байт (cpb).
Код C/C++ для выполнения SHA над блоком выглядит так:
// Schedule 64-byte message
SHA256_SCHEDULE(W, data);
uint32x4_p8 a = abcd, e = efgh;
uint32x4_p8 b = VectorShiftLeft<4>(a);
uint32x4_p8 f = VectorShiftLeft<4>(e);
uint32x4_p8 c = VectorShiftLeft<4>(b);
uint32x4_p8 g = VectorShiftLeft<4>(f);
uint32x4_p8 d = VectorShiftLeft<4>(c);
uint32x4_p8 h = VectorShiftLeft<4>(g);
for (unsigned int i=0; i<64; i+=4)
{
const uint32x4_p8 k = VectorLoad32x4u(K, i*4);
const uint32x4_p8 w = VectorLoad32x4u(W, i*4);
SHA256_ROUND<0>(w,k, a,b,c,d,e,f,g,h);
SHA256_ROUND<1>(w,k, a,b,c,d,e,f,g,h);
SHA256_ROUND<2>(w,k, a,b,c,d,e,f,g,h);
SHA256_ROUND<3>(w,k, a,b,c,d,e,f,g,h);
}
Я компилирую программу с помощью GCC, используя -O3 а также -mcpu=power8 на машине ppc64-le. Когда я смотрю на разборки, я вижу несколько из них:
...
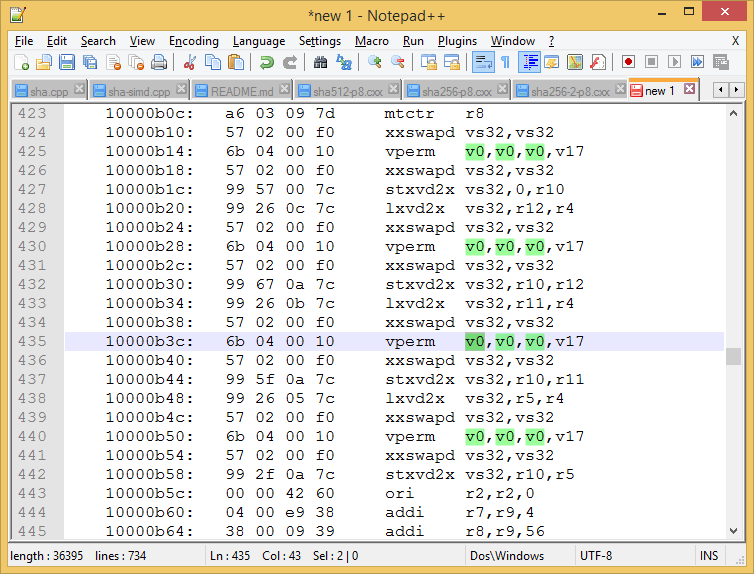
10000b0c: a6 03 09 7d mtctr r8
10000b10: 57 02 00 f0 xxswapd vs32,vs32
10000b14: 6b 04 00 10 vperm v0,v0,v0,v17
10000b18: 57 02 00 f0 xxswapd vs32,vs32
10000b1c: 99 57 00 7c stxvd2x vs32,0,r10
10000b20: 99 26 0c 7c lxvd2x vs32,r12,r4
10000b24: 57 02 00 f0 xxswapd vs32,vs32
10000b28: 6b 04 00 10 vperm v0,v0,v0,v17
10000b2c: 57 02 00 f0 xxswapd vs32,vs32
10000b30: 99 67 0a 7c stxvd2x vs32,r10,r12
10000b34: 99 26 0b 7c lxvd2x vs32,r11,r4
10000b38: 57 02 00 f0 xxswapd vs32,vs32
10000b3c: 6b 04 00 10 vperm v0,v0,v0,v17
10000b40: 57 02 00 f0 xxswapd vs32,vs32
10000b44: 99 5f 0a 7c stxvd2x vs32,r10,r11
10000b48: 99 26 05 7c lxvd2x vs32,r5,r4
10000b4c: 57 02 00 f0 xxswapd vs32,vs32
10000b50: 6b 04 00 10 vperm v0,v0,v0,v17
10000b54: 57 02 00 f0 xxswapd vs32,vs32
10000b58: 99 2f 0a 7c stxvd2x vs32,r10,r5
...
vperm v0,v0,v0,v17 кажутся мертвыми инструкциями, потому что v0 не используется после перестановки.
Что значит vperm v0,v0,v0,v17 делать?
Исходный код C++ доступен по адресу sha256-p8.cxx,
Исходный файл был скомпилирован с g++ -g3 -O3 -Wall -DTEST_MAIN -mcpu=power8 sha256-2-p8.cxx -o sha256-2-p8.exe,
Полная разборка доступна на разборке PPC64 SHA-256.
Я думаю, что фрагмент выше производится SHA256_SCHEDULE, Я вижу коллекцию VectorShiftLeft (vsldoi) после рассматриваемого блока.
Чтобы еще больше обнулить, я вполне уверен, что это первые два слова в конце:
const uint8x16_p8 mask = {3,2,1,0, 7,6,5,4, 11,10,9,8, 15,14,13,12};
for (unsigned int i=0; i<16; i+=4)
VectorStore32x4u(VectorPermute32x4(VectorLoad32x4u(data, i*4), mask), W, i*4);
SHA256_SCHEDULE выглядит так:
// +2 because Schedule reads beyond the last element
void SHA256_SCHEDULE(uint32_t W[64+2], const uint8_t* data)
{
#if (__LITTLE_ENDIAN__)
const uint8x16_p8 mask = {3,2,1,0, 7,6,5,4, 11,10,9,8, 15,14,13,12};
for (unsigned int i=0; i<16; i+=4)
VectorStore32x4u(VectorPermute32x4(VectorLoad32x4u(data, i*4), mask), W, i*4);
#else
for (unsigned int i=0; i<16; i+=4)
VectorStore32x4u(VectorLoad32x4u(data, i*4), W, i*4);
#endif
// At i=62, W[i-2] reads the 65th and 66th elements. W[] has 2 extra "don't care" elements.
for (unsigned int i = 16; i < 64; i+=2)
{
const uint32x4_p8 s0 = Vector_sigma0(VectorLoad32x4u(W, (i-15)*4));
const uint32x4_p8 w0 = VectorLoad32x4u(W, (i-16)*4);
const uint32x4_p8 s1 = Vector_sigma1(VectorLoad32x4u(W, (i-2)*4));
const uint32x4_p8 w1 = VectorLoad32x4u(W, (i-7)*4);
const uint32x4_p8 r = vec_add(s1, vec_add(w1, vec_add(s0, w0)));
VectorStore32x4u(r, W, i*4);
}
}
Вот изображение рассматриваемого раздела с v0 подсвечен.
1 ответ
На первый взгляд, вы проделали всю тяжелую работу, этот скриншот выглядит так, словно это будет секция обмена с прямым порядком байтов LE. Я предполагаю, что вы здесь. Я ожидаю, что v17 является переменной маски - она загружается как vs49 из оглавления ранее.
Ключевая часть информации, которую вы упускаете, это то, что v0 - это vs32 (я знаю, что это очень запутанно). Я не уверен, где лучшее место, чтобы продемонстрировать это, но ABI сделает. Вы можете скачать его здесь: https://members.openpowerfoundation.org/document/dl/576.
Рисунок 2-17. Векторные регистры как часть VSR на странице 44 должны помочь проиллюстрировать, что я имею в виду, именно так оно и есть в аппаратном обеспечении.