Как улучшить обнаружение и сопоставление ключевых точек
Я работал над собственным проектом в области обработки изображений и робототехники, где вместо робота, как обычно, обнаруживающего цвета и выбирающего объект, он пытается обнаружить отверстия (напоминающие различные многоугольники) на плате. Для лучшего понимания настройки вот изображение:
Как вы можете видеть, я должен обнаружить эти отверстия, выяснить их формы и затем использовать робота, чтобы вставить объект в отверстия. Я использую камеру глубины Kinect, чтобы получить изображение глубины. Картинка показана ниже:
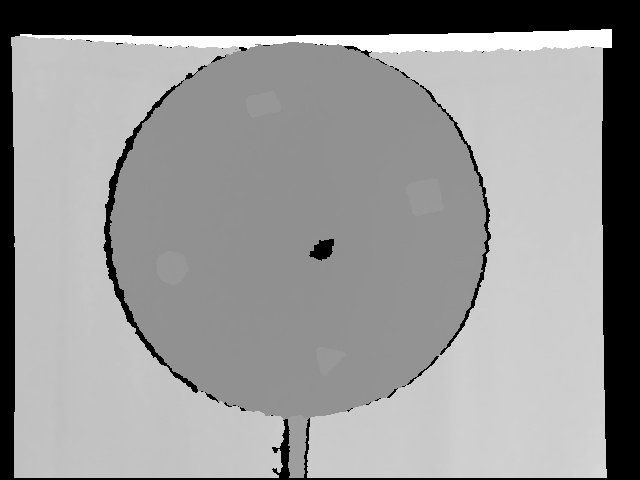
Я задумался о том, как обнаружить отверстия с помощью камеры, первоначально используя маскировку для удаления фоновой части и некоторой части переднего плана на основе измерения глубины, но это не сработало, поскольку при различных ориентациях камеры дырки слились бы с доской... что-то наподобие взвинчивания (оно полностью становится белым). Потом наткнулся adaptiveThreshold функция
adaptiveThreshold(depth1,depth3,255,ADAPTIVE_THRESH_GAUSSIAN_C,THRESH_BINARY,7,-1.0);
С устранением шума с использованием размытия, расширения и размытия по Гауссу; который обнаружил отверстия лучше, как показано на рисунке ниже. Затем я использовал детектор краев cvCanny для получения краев, но пока он не был хорошим, как показано на рисунке ниже. После этого я опробовал различные детекторы функций из SIFT, SURF, ORB, GoodFeaturesToTrack и обнаружил, что ORB дал лучший раз и функции обнаружены. После этого я попытался получить относительную позу камеры для изображения запроса, найдя его ключевые точки и сопоставив эти ключевые точки для хорошего соответствия, которое будет дано findHomography функция. Результаты показаны ниже, как на диаграмме:
В конце я хочу получить относительную позу камеры между двумя изображениями и переместить робота в это положение, используя векторы вращения и поступательного движения, полученные с помощью функции solvePnP.
Так есть ли какой-нибудь другой метод, с помощью которого я мог бы улучшить качество обнаруженных отверстий для обнаружения и сопоставления ключевых точек?
Я также пробовал обнаружение контуров и приближение PolyDP, но приблизительные формы не очень хороши:
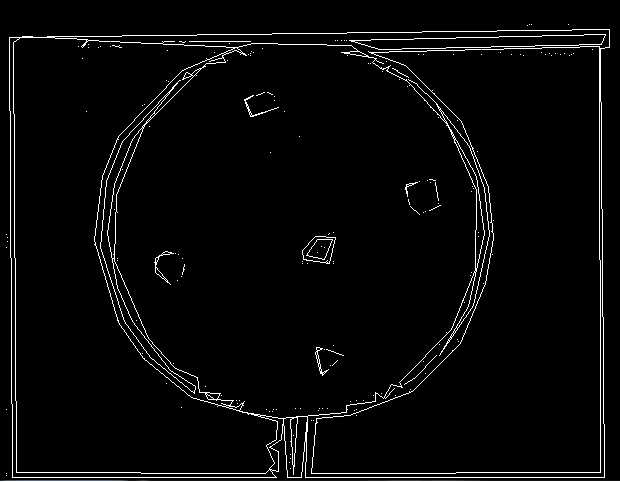
Я попытался настроить входные параметры для пороговых и сложных функций, но это лучшее, что я могу получить
Кроме того, мой подход к правильной позе камеры?
ОБНОВЛЕНИЕ: Независимо от того, что я пытался, я не мог получить хорошие повторяемые объекты на карту. Затем я прочитал в Интернете, что изображение глубины дешево в разрешении и используется только для маскировки и получения расстояний. Таким образом, меня поразило, что функции не являются правильными из-за изображения низкого разрешения с его грязными краями. Поэтому я подумал об обнаружении объектов на изображении RGB и использовании изображения глубины, чтобы получить только расстояния этих объектов. Качество функций, которые я получил, было буквально за чертой. Он даже обнаружил винты на плате! Вот ключевые точки, обнаруженные с помощью обнаружения ключевых точек GoodFeaturesToTrack. , Я столкнулся с другим препятствием, когда получал расстояние с расстояниями точек, не выходящими должным образом. Я искал возможные причины, и через некоторое время мне пришло в голову, что из-за смещения между камерами было смещение в изображениях RGB и глубины. Это видно по первым двум изображениям. Затем я искал в сети, как компенсировать это смещение, но не смог найти работающего решения.
, Я столкнулся с другим препятствием, когда получал расстояние с расстояниями точек, не выходящими должным образом. Я искал возможные причины, и через некоторое время мне пришло в голову, что из-за смещения между камерами было смещение в изображениях RGB и глубины. Это видно по первым двум изображениям. Затем я искал в сети, как компенсировать это смещение, но не смог найти работающего решения.
Если бы кто-нибудь из вас мог помочь мне компенсировать компенсацию, это было бы здорово!
ОБНОВЛЕНИЕ: я не мог эффективно использовать функцию goodFeaturesToTrack. Функция дает углы в типе Point2f. Если вы хотите вычислить дескрипторы, нам нужны ключевые точки, а преобразование Point2f в ключевую точку с помощью приведенного ниже фрагмента кода приводит к потере масштаба и инвариантности вращения.
for( size_t i = 0; i < corners1.size(); i++ )
{
keypoints_1.push_back(KeyPoint(corners1[i], 1.f));
}
Отвратительный результат сопоставления объектов показан ниже  ,
,
Я должен начать на различных совпадениях функций. Я буду публиковать дальнейшие обновления. Было бы очень полезно, если бы кто-то мог помочь в устранении проблемы смещения.
2 ответа
Компенсация разницы между выводом изображения и мировыми координатами:
Вы должны использовать старый добрый подход к калибровке камеры для калибровки отклика камеры и, возможно, генерации матрицы коррекции для выхода камеры (чтобы преобразовать их в реальные масштабы).
Это не так сложно, как только вы распечатали шаблон шахматной доски и сделали различные снимки. (Для этого приложения вам не нужно беспокоиться об инвариантности вращения. Просто откалибруйте мировоззрение с помощью массива изображений.)
Вы можете найти больше информации здесь: http://www.vision.caltech.edu/bouguetj/calib_doc/htmls/own_calib.html
-
Теперь, так как я не могу комментировать вопрос, я хотел бы спросить, требует ли ваше конкретное приложение, чтобы машина "узнала" форму отверстия на лету. Если имеется ограниченное количество форм отверстий, вы можете затем математически смоделировать их и найти пиксели, которые поддерживают предопределенные модели на черно-белом изображении.
Например, (x)^2+(y)^2-r^2=0 для круга с радиусом r, тогда как x и y - это пиксельные координаты.
При этом я считаю, что необходимы дополнительные разъяснения относительно требований приложения (определение формы).
Если вы собираетесь обнаруживать определенные формы, такие как фигуры в предоставленном вами изображении, то вам лучше использовать классификатор. Погрузитесь в классификаторы Хаара, или, еще лучше, посмотрите на Мешок Слов.
Используя BoW, вам нужно будет обучить несколько наборов данных, состоящих из положительных и отрицательных образцов. Положительные образцы будут содержать N уникальных образцов каждой формы, которую вы хотите обнаружить. Лучше, если N будет> 10, лучше всего, если>100 и очень вариабельно и уникально, для хорошей и надежной тренировки классификатора.
Отрицательные образцы (очевидно) будут содержать материал, который не представляет ваши формы в любом случае. Это просто для проверки точности классификатора.
Кроме того, как только вы обучите свой классификатор, вы можете распространять данные своего классификатора (скажем, предположим, что вы используете SVM).
Вот несколько ссылок, с которых можно начать работу с Bag of Words: https://gilscvblog.wordpress.com/2013/08/23/bag-of-words-models-for-visual-categorization/
Пример кода: http://answers.opencv.org/question/43237/pyopencv_from-and-pyopencv_to-for-keypoint-class/