Несколько совпадений регулярных выражений в формуле Google Sheets
Я пытаюсь получить список всех цифр, предшествующих дефису в данной строке (скажем, в ячейке A1), используя формулу регулярных выражений Google Sheets:
=REGEXEXTRACT(A1, "\d-")
Моя проблема в том, что он возвращает только первое совпадение... как я могу получить все совпадения?
Пример текста:
"A1-Nutrition;A2-ActPhysiq;A2-BioMeta;A2-Patho-jour;A2-StgMrktg2;H2-Bioth2/EtudeCas;H2-Bioth2/Gemmo;H2-Bioth2/Oligo;H2-Bioth2/Opo;H2-Bioth2/Organo;H3-Endocrino;H3-Génétiq"
Моя формула возвращается 1-тогда как я хочу получить 1-2-2-2-2-2-2-2-2-2-3-3- (в виде массива или связанного текста).
Я знаю, что мог бы использовать скрипт или другую функцию (например, SPLIT), чтобы достичь желаемого результата, но я действительно хочу знать, как я могу получить регулярное выражение re2, чтобы возвращать такие множественные совпадения в "REGEX.*"Формула листов Google. Что-то вроде опции"g lobal - не возвращаться после первого матча "на http://regex101.com/
Я также попытался удалить нежелательный текст с REGEXREPLACE, но безуспешно (я не мог избавиться от других цифр, не предшествующих дефису).
Любая помощь приветствуется! Спасибо:)
8 ответов
редактировать
Я придумал более общее решение:
=regexreplace(A1,"(.)?(\d-)|(.)","$2")
Попробуйте эту формулу:
=regexreplace(regexreplace(A1,"[^\-0-9]",""),"(\d-)|(.)","$1")Он будет обрабатывать строку следующим образом:
"A1-Nutrition;A2-ActPhysiq;A2-BioM---eta;A2-PH3-Généti***566*9q"с выходом:
1-2-2-2-3-
На самом деле вы можете сделать это в одной формуле, используя regexreplace, чтобы окружить все значения группой захвата вместо замены текста:
=join("",REGEXEXTRACT(A1,REGEXREPLACE(A1,"(\d-)","($1)")))
в основном то, что он делает, это окружить все экземпляры \d- с помощью "группы захвата", а затем с помощью извлечения регулярных выражений, он аккуратно возвращает все захваты. если вы хотите объединить его обратно в одну строку, вы можете просто использовать объединение, чтобы упаковать его обратно в одну ячейку:

Вы можете создать свою собственную функцию в редакторе скриптов:
function ExtractAllRegex(input, pattern,groupId) {
return Array.from(input.matchAll(new RegExp(pattern,'g')), x=>x[groupId]);
}
Или, если вам нужно вернуть все совпадения в одной ячейке, объединенной каким-либо разделителем:
function ExtractAllRegex(input, pattern,groupId,separator) {
return Array.from(input.matchAll(new RegExp(pattern,'g')), x=>x[groupId]).join(separator);
}
Тогда просто назовите это как =ExtractAllRegex(A1, "\d-", 0, ", ").
Описание:
input- текущее значение ячейкиpattern- шаблон регулярного выраженияgroupId- Захват идентификатора группы, который вы хотите извлечьseparator- текст, используемый для объединения совпадающих результатов.
Я не смог получить принятый ответ для моего дела. Я хотел бы сделать это таким образом, но мне нужно было быстрое решение и пойти со следующим:
Входные данные:
1111 days, 123 hours 1234 minutes and 121 seconds
Ожидаемый результат:
1111 123 1234 121
Формула:
=split(REGEXREPLACE(C26,"[a-z,]"," ")," ")
Самое короткое регулярное выражение:
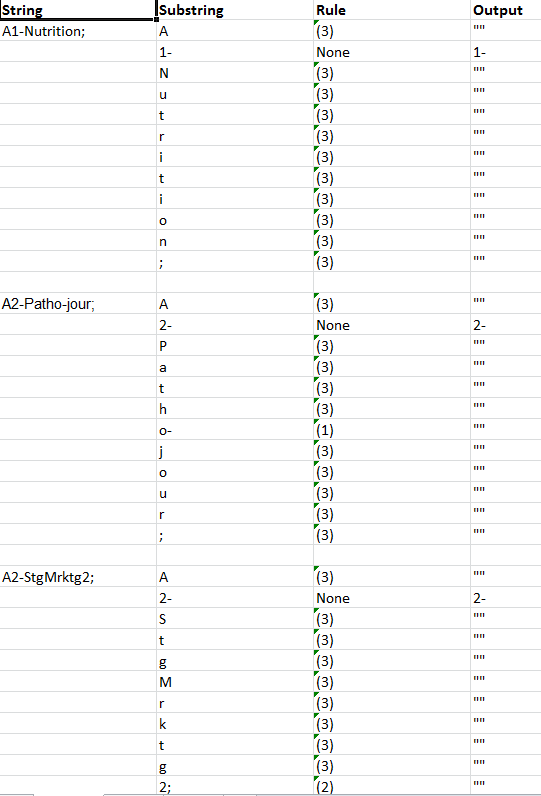
=regexreplace(A1,".?(\d-)|.", "$1")
Что возвращает1-2-2-2-2-2-2-2-2-2-3-3-для"A1-Nutrition;A2-ActPhysiq;A2-BioMeta;A2-Patho-jour;A2-StgMrktg2;H2-Bioth2/EtudeCas;H2-Bioth2/Gemmo;H2-Bioth2/Oligo;H2-Bioth2/Opo;H2-Bioth2/Organo;H3-Endocrino;H3-Génétiq".
Объяснение регулярного выражения:
-
.?-- необязательный символ -
(\d-)-- группа захвата 1 с цифрой, за которой следует тире (указать(\d+-)несколько цифр) -
|-- логический или -
.-- любой символ - замена
"$1"использует только группу захвата 1 и отбрасывает все остальное
Узнайте больше о регулярном выражении: https://twiki.org/cgi-bin/view/Codev/TWikiPresentation2018x10x14Regex
Кажется, это работает, и я попытался проверить это.
Логика
(1) Заменить букву и дефис на ничего
(2) Заменить любую цифру без дефиса ничем
(3) Заменить все, что не является цифрой или дефисом, ничем
=regexreplace(A1,"[a-zA-Z]-|[0-9][^-]|[a-zA-Z;/é]","")
Результат
1-2-2-2-2-2-2-2-2-2-3-3-
Анализ
Я должен был пройти через это процедурно, чтобы убедить себя, что это правильно. Согласно этой ссылке, когда есть альтернативы, разделенные символом канала, регулярное выражение должно соответствовать им в порядке слева направо. Приведенная выше формула не будет работать должным образом, если только правило 1 не будет первым (в противном случае все символы, кроме цифры или дефиса, обнуляются до того, как правило (1) может войти в игру, и вы получите дополнительный дефис из "Patho-jour").
Вот несколько примеров того, как я думаю, что это должно иметь дело с текстом
Существует два общих («Excel»/«нативный»/не-Apps Script) решения для возврата массива совпадений регулярных выражений в стилеREGEXEXTRACT:
Способ 1)вставьте разделитель вокруг совпадений, удалите мусор и вызовите
Регулярные выражения работают, перебирая строку слева направо и «потребляя». Если мы будем осторожны с потреблением ненужных значений, мы можем их выбросить.
(Это позволяет обойти проблему, с которой сталкивается принятое в настоящее время решение, а именно то, что, как упоминает Карлос Эдуардо Оливейра, оно явно не удастся, если текст корпуса содержит специальные символы регулярных выражений.)
Сначала мы выбираем разделитель, которого еще не должно быть в тексте. Правильный способ сделать это - проанализировать текст, чтобы временно заменить наш разделитель «временным разделителем», например, если мы собирались использовать запятые.","мы бы сначала заменили все существующие запятые чем-то вроде"<<QUOTED-COMMA>>"затем отменить их замену позже. НО, для простоты, мы просто возьмем случайный символ, такой какиз блоков юникода для частного использования и использовать его в качестве нашего специального разделителя (обратите внимание, что это 2 байта... электронные таблицы Google могут не считать байты в графемах согласованным образом, но мы будем осторожны позже).
=SPLIT(
LAMBDA(temp,
MID(temp, 1, LEN(temp)-LEN(""))
)(
REGEXREPLACE(
"xyzSixSpaces:[ ]123ThreeSpaces:[ ]aaaa 12345",".*?( |$)",
"$1"
)
),
""
)
Мы просто используем лямбду, чтобы определить temp="match1match2match3", затем используем это, чтобы удалить последний разделитель в "match1match2match3", затемSPLITэто.
ПринимаяCOLUMNSрезультата докажет, что возвращается правильный результат, т.е.{" ", " ", " "}.
Это особенно хорошая функция, чтобы превратить ее в именованную функцию и назвать ее как-то такREGEXGLOBALEXTRACT(text,regex)илиREGEXALLEXTRACT(text,regex), например:
=SPLIT(
LAMBDA(temp,
MID(temp, 1, LEN(temp)-LEN(""))
)(
REGEXREPLACE(
text,
".*?("®ex&"|$)",
"$1"
)
),
""
)
Способ 2)
использовать рекурсию
С (т.е. позволяет вам определить функцию, как и любой другой язык программирования) вы можете использовать некоторые приемы из хорошо изученного лямбда-исчисления и программирования функций: у вас есть доступ к рекурсии. Определение рекурсивной функции сбивает с толку, потому что у нее нет простого способа ссылаться на себя, поэтому вам нужно использовать трюк/соглашение:
трюк для рекурсивных функций: чтобы фактически определить функцию f, которая должна ссылаться на себя , вместо этого определите функцию, которая принимает параметр
itselfи возвращает функцию, которую вы действительно хотите ; передать это «соглашение» Y-комбинатору, чтобы превратить его в настоящую рекурсивную функцию
Сантехника, выполняющая такую функцию, называется Y-комбинатором. Вот хорошая статья, чтобы понять это, если у вас есть опыт программирования.
Например, чтобы получить результат 5! (5 факториал, т.е. реализовать собственныйFACT(5)), мы могли бы определить:
Именованная функцияY(f)"="LAMBDA(f, (LAMBDA(x,x(x)))( LAMBDA(x, f(LAMBDA(y, x(x)(y)))) ) )(это Y-комбинатор, и он волшебный; вам не нужно понимать его, чтобы использовать)
Именованная функцияMY_FACTORIAL(n)"="
Y(LAMBDA(self,
LAMBDA(n,
IF(n=0, 1, n*self(n-1))
)
))
РезультатMY_FACTORIAL(5): 120
Y-комбинатор делает написание рекурсивных функций относительно простым, как введение в курс программирования. Я использую именованные функции для ясности, но вы можете просто свалить все вместе за счет здравомыслия...
=LAMBDA(Y,
Y(LAMBDA(self, LAMBDA(n, IF(n=0,1,n*self(n-1))) ))(5)
)(
LAMBDA(f, (LAMBDA(x,x(x)))( LAMBDA(x, f(LAMBDA(y, x(x)(y)))) ) )
)
Как это применимо к рассматриваемой проблеме? Ну рекурсивное решение выглядит следующим образом:
в приведенном ниже псевдокоде я использую «функцию» вместоLAMBDA, но это одно и то же:
// code to get around the fact that you can't have 0-length arrays
function emptyList() {
return {"ignore this value"}
}
function listToArray(myList) {
return OFFSET(myList,0,1)
}
function allMatches(text, regex) {
allMatchesHelper(emptyList(), text, regex)
}
function allMatchesHelper(resultsToReturn, text, regex) {
currentMatch = REGEXEXTRACT(...)
if (currentMatch succeeds) {
textWithoutMatch = SUBSTITUTE(text, currentMatch, "", 1)
return allMatches(
{resultsToReturn,currentMatch},
textWithoutMatch,
regex
)
} else {
return listToArray(resultsToReturn)
}
}
К сожалению, рекурсивный подход имеет квадратичный порядок роста (поскольку он снова и снова добавляет результаты к себе, воссоздавая гигантскую строку поиска, извлекая из нее все меньшие и меньшие кусочки, поэтому 1+2+3+ 4 +5+... = big^2, что может занять много времени), поэтому может быть медленным, если у вас много совпадений. Для скорости лучше оставаться внутри механизма регулярных выражений, так как он, вероятно, сильно оптимизирован.
Конечно, вы можете избежать использования именованных функций, выполняя временные привязки с помощьюLAMBDA(varName, expr)(varValue)если вы хотите использовать varName в выражении. (Вы можете определить этот шаблон как именованную функцию=cont(varValue)инвертировать порядок параметров, чтобы сделать код чище или нет.)
- Всякий раз, когда я использую
varName = varValue, напишите это вместо этого. - чтобы увидеть, успешно ли совпадение, используйте
ISNA(...)
Это будет выглядеть примерно так:
Именованная функцияallMatches(resultsToReturn, text, regex): НЕ ПРОВЕРЕНО :
LAMBDA(helper,
OFFSET(
helper({"ignore"}, text, regex),
0,1)
)(
Y(LAMBDA(helperItself,
LAMBDA(results, partialText,
LAMBDA(currentMatch,
IF(ISNA(currentMatch),
results,
LAMBDA(textWithoutMatch,
helperItself({results,currentMatch}, textWithoutMatch)
)(
SUBSTITUTE(partialText, currentMatch, "", 1)
)
)
)(
REGEXEXTRACT(partialText, regex)
)
)
))
)
Решение для захвата групп с помощью RegexReplace, а затем выполнения RegexExctract работает и здесь, но есть одна загвоздка.
=join("",REGEXEXTRACT(A1,REGEXREPLACE(A1,"(\d-)","($1)")))
Если ячейка, в которую вы пытаетесь получить значения, содержит специальные символы, такие как круглые скобки «(» или вопросительный знак «?», предоставленное решение не будет работать.
В моем случае я пытался перечислить все «текстовые переменные», содержащиеся в ячейке. Этот «текст переменных» был написан внутри так: «{example_name}». Но полное содержимое ячейки содержало специальные символы, из-за которых формула регулярного выражения не работала. Когда я удалил эти специальные символы, я мог перечислить все захваченные группы, как это сделало решение.