Какова основная структура данных набора STL в C++?
Я хотел бы знать, как набор реализован в C++. Если бы я реализовал свой собственный набор-контейнер без использования контейнера, предоставленного STL, каков был бы лучший способ выполнить эту задачу?
Я понимаю, что наборы STL основаны на абстрактной структуре данных двоичного дерева поиска. Итак, какова основная структура данных? Массив?
Кроме того, как это insert() работать на съемочную площадку? Как набор проверяет, существует ли в нем элемент?
Я прочитал в википедии, что еще один способ реализовать набор с помощью хэш-таблицы. Как это будет работать?
6 ответов
Вы можете реализовать двоичное дерево поиска, сначала определив Node структура:
struct Node
{
void *nodeData;
Node *leftChild;
Node *rightChild;
}
Затем вы можете определить корень дерева с другим Node *rootNode;
Запись в Википедии о бинарном дереве поиска содержит довольно хороший пример того, как реализовать метод вставки, поэтому я также рекомендовал бы проверить это.
Что касается дубликатов, они, как правило, не допускаются в наборах, так что вы можете просто отбросить этот ввод, выбросить исключение и т. Д., В зависимости от вашей спецификации.
Шаг отладки в g++ 6.4 stdlibC++ source
Знаете ли вы, что по умолчанию в Ubuntu 16.04 g++-6 пакет или сборку GCC 6.4 из исходного кода, вы можете войти в библиотеку C++ без дальнейшей настройки?
Делая это, мы легко заключаем, что красно-черное дерево используется.
Это имеет смысл, так как std::set можно пройти по порядку, что было бы неэффективно, если бы использовалась хэш-карта.
a.cpp:
#include <cassert>
#include <set>
int main() {
std::set<int> s;
s.insert(1);
s.insert(2);
assert(s.find(1) != s.end());
assert(s.find(2) != s.end());
assert(s.find(3) == s3.end());
}
Компилировать и отлаживать:
g++ -g -std=c++11 -O0 -o a.out ./a.cpp
gdb -ex 'start' -q --args a.out
Теперь, если вы вступите в s.insert(1) вы сразу достигнете /usr/include/c++/6/bits/stl_set.h:
487 #if __cplusplus >= 201103L
488 std::pair<iterator, bool>
489 insert(value_type&& __x)
490 {
491 std::pair<typename _Rep_type::iterator, bool> __p =
492 _M_t._M_insert_unique(std::move(__x));
493 return std::pair<iterator, bool>(__p.first, __p.second);
494 }
495 #endif
который явно только вперед _M_t._M_insert_unique,
Итак, мы открываем исходный файл в vim и находим определение _M_t:
typedef _Rb_tree<key_type, value_type, _Identity<value_type>,
key_compare, _Key_alloc_type> _Rep_type;
_Rep_type _M_t; // Red-black tree representing set.
Так _M_t имеет тип _Rep_type а также _Rep_type это _Rb_tree,
Хорошо, теперь это достаточно доказательств для меня. Если вы не верите этому _Rb_tree черно-красное дерево, шагните немного дальше и прочитайте алгоритм
unordered_set использует хэш-таблицу
Та же процедура, но заменить set с unordered_set на коде.
Это имеет смысл, так как std::unordered_set не может быть пройден по порядку, поэтому стандартная библиотека выбрала хэш-карту вместо красно-черного дерева, так как хэш-карта имеет большую амортизированную сложность времени вставки.
Шагая в insert приводит к /usr/include/c++/6/bits/unordered_set.h:
415 std::pair<iterator, bool>
416 insert(value_type&& __x)
417 { return _M_h.insert(std::move(__x)); }
Итак, мы открываем исходный файл в vim и искать _M_h:
typedef __uset_hashtable<_Value, _Hash, _Pred, _Alloc> _Hashtable;
_Hashtable _M_h;
Так что хэш-таблица это.
std::map а также std::unordered_map
Аналог для std::set против std:unordered_set: Какая структура данных находится внутри std::map в C++?
Характеристики производительности
Вы также можете сделать вывод о структуре данных, используемой для их синхронизации.
Мы четко видим для:
std::set, логарифмическое время вставкиstd::unordered_set, более сложный шаблон hashmap pattern:- на не масштабированном графике мы отчетливо видим удвоение динамического массива на огромном от линейно увеличивающихся пиков
на увеличенном графике мы видим, что времена в основном постоянны и идут к 250 нс, поэтому намного быстрее, чем
std::mapкроме очень маленьких размеров картыНесколько полос хорошо видны, и их наклон становится меньше, когда массив удваивается.
Я полагаю, что это связано со средним линейным увеличением количества связанных списков в каждом бине. Затем, когда массив удваивается, у нас есть больше корзин, поэтому более короткие прогулки.
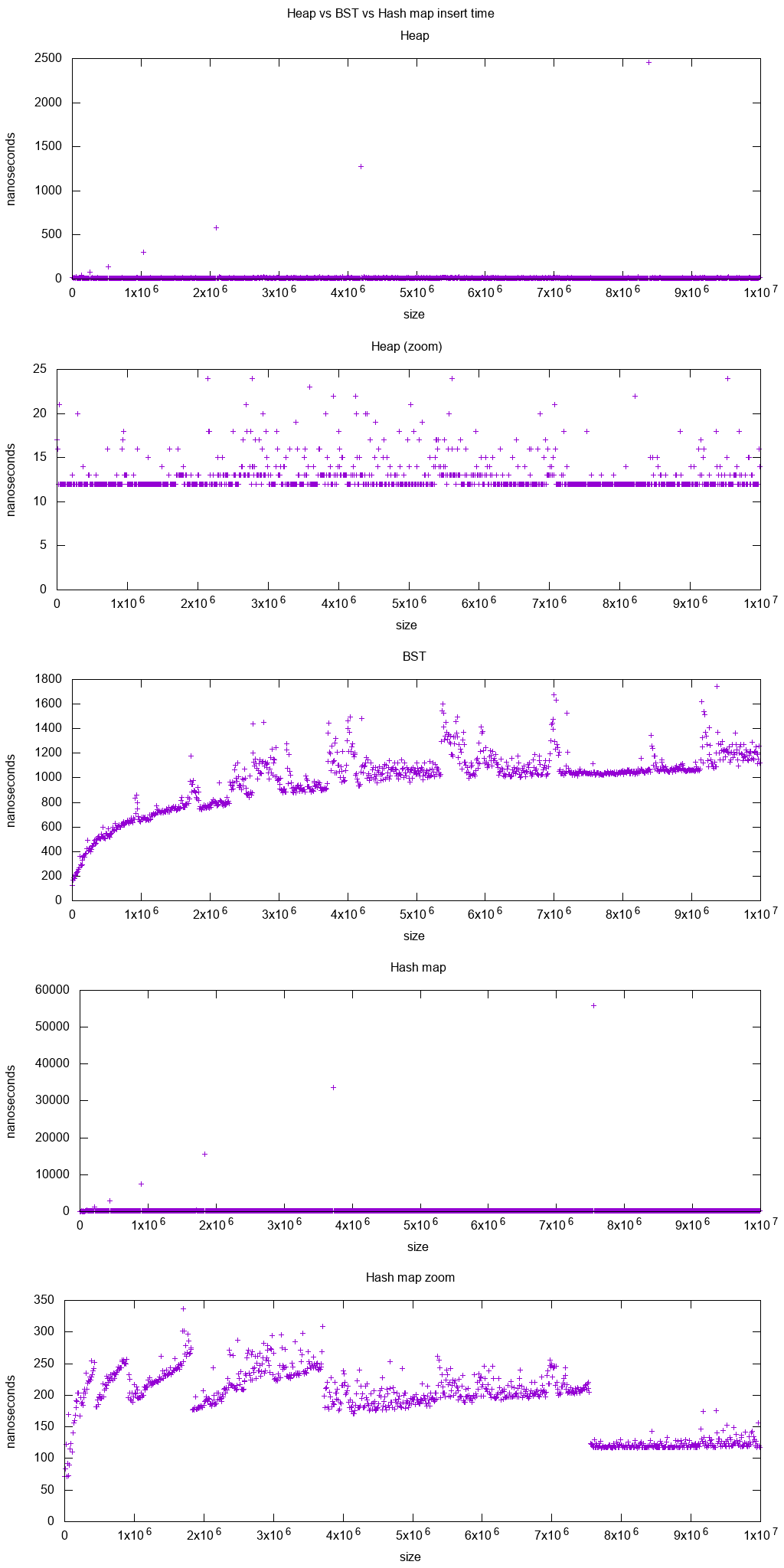
График создан с:
- код: https://github.com/cirosantilli/cpp-cheat/blob/15066739601a701d5f4d702ec28c6c615cdbb17b/cpp/interactive/bst_vs_heap.cpp
- Система: Ubuntu 18.04, GCC 7.3, процессор Intel i7-7820HQ, оперативная память DDR4 2400 МГц, Lenovo Thinkpad P51.
Анализ кучи против BST в: Кучи против дерева двоичного поиска (BST)
Как сказал KTC, как std::set Реализация может варьироваться - стандарт C++ просто определяет абстрактный тип данных. Другими словами, стандарт не определяет, как контейнер должен быть реализован, а только какие операции он должен поддерживать. Однако большинство реализаций STL, насколько мне известно, используют красно-черные деревья или другие сбалансированные двоичные деревья поиска какого-либо вида (например, GNU libstdC++ использует красно-черные деревья).
Хотя теоретически можно реализовать набор в виде хеш-таблицы и получить более быструю асимптотическую производительность (амортизированное O(длина ключа) по сравнению с O(log n) для поиска и вставки), для этого потребуется, чтобы пользователь предоставил хеш-функцию для любого типа, который он хочет хранить (см . запись в Википедии о хэш-таблицах для хорошего объяснения того, как они работают). Что касается реализации бинарного дерева поиска, вы не захотите использовать массив - как упоминал Рауль, вы бы хотели что-то вроде Node структура данных.
Я понимаю, что наборы STL основаны на абстрактной структуре данных двоичного дерева поиска. Итак, какова основная структура данных? Массив?
Как уже отмечали другие, это меняется. Набор обычно реализуется как дерево (красно-черное дерево, сбалансированное дерево и т. Д.), Но могут существовать и другие реализации.
Кроме того, как insert() работает для набора?
Это зависит от базовой реализации вашего набора. Если оно реализовано в виде двоичного дерева, в Википедии есть образец рекурсивной реализации для функции insert(). Вы можете проверить это.
Как набор проверяет, существует ли в нем элемент?
Если он реализован в виде дерева, то он обходит дерево и проверяет каждый элемент. Однако наборы не позволяют хранить повторяющиеся элементы. Если вы хотите набор, который позволяет дублировать элементы, то вам нужен мультимножество.
Я прочитал в википедии, что еще один способ реализовать набор с помощью хэш-таблицы. Как это будет работать?
Вы можете ссылаться на hash_set, где набор реализован с использованием хеш-таблиц. Вам нужно будет предоставить хеш-функцию, чтобы узнать, в каком месте хранить ваш элемент. Эта реализация идеальна, когда вы хотите быстро найти элемент. Однако, если важно, чтобы ваши элементы хранились в определенном порядке, тогда более подходящей является реализация дерева, так как вы можете пройти по ней предзаказ, порядок или порядок.
То, как конкретный контейнер реализован в C++, полностью зависит от реализации. Все, что требуется, - это чтобы результат соответствовал требованиям, изложенным в стандарте, таким как требования к сложности для различных методов, требования к итераторам и т. Д.
Наборы обычно реализуются как красно-черные деревья.
Я проверил, и оба libc++ а также libstdc++ действительно использовать красно-черные деревья для std::set,
std::unordered_set был реализован с помощью хеш-таблицы в libc++ и я предполагаю, что то же самое для libstdc++ но не проверял.
Изменить: видимо мое слово недостаточно хорошо.
Подключаюсь к этому, потому что я не видел, чтобы кто-то явно упоминал об этом... Стандарт C++ не определяет структуру данных для использования для std::set и std::map. Однако он указывает на сложность выполнения различных операций. Требования к вычислительной сложности для операций вставки, удаления и поиска более или менее вынуждают реализацию использовать алгоритм сбалансированного дерева.
Существует два распространенных алгоритма реализации сбалансированных бинарных деревьев: красно-черный и AVL. Из этих двух Red-Black немного проще в реализации, требуя на 1 бит памяти меньше на каждый узел дерева (что вряд ли имеет значение, поскольку вы в любом случае собираетесь записать на нем байт в простой реализации) и является немного быстрее, чем AVL при удалении узлов (это связано с более мягкими требованиями к балансировке дерева).
Все это в сочетании с требованием std::map о том, что ключ и данные хранятся в std::pair, навязывают вам все это без явного указания структуры данных, которую вы должны использовать для контейнера.
Все это, в свою очередь, дополняется дополнительными функциями С ++14/17 для контейнера, которые позволяют соединять узлы из одного дерева в другое.