Условное агрегирование
Давайте иметь следующие данные
IF OBJECT_ID('dbo.LogTable', 'U') IS NOT NULL DROP TABLE dbo.LogTable
SELECT TOP 100000 DATEADD(day, ( ABS(CHECKSUM(NEWID())) % 65530 ), 0) datesent
INTO [LogTable]
FROM sys.sysobjects
CROSS JOIN sys.all_columns
Я хочу посчитать количество строк, количество строк за прошлый год и количество строк за последние десять лет. Это может быть достигнуто с помощью запроса условного агрегирования или использования подзапросов следующим образом
-- conditional aggregation query
SELECT
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
-- subqueries
SELECT
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
Если вы выполняете запросы и смотрите планы запросов, то вы видите что-то вроде
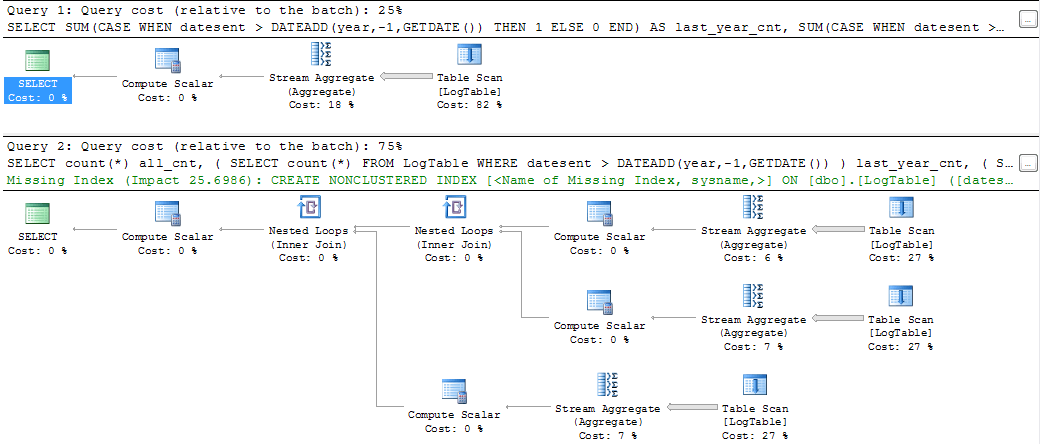
Очевидно, что первое решение имеет гораздо более приятный план запросов, оценку затрат, и даже команда SQL выглядит более лаконично и причудливо. Однако, если вы измеряете процессорное время запроса с помощью SET STATISTICS TIME ON Я получаю следующие результаты (я измерял несколько раз с примерно одинаковыми результатами)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 41 ms.
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 26 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Поэтому второе решение имеет чуть лучшую (или такую же) производительность, чем решение, использующее условное агрегирование. Разница становится более очевидной, если мы создадим индекс на datesent приписывать.
CREATE INDEX ix_logtable_datesent ON dbo.LogTable(DateSent)
Тогда второе решение начинает использовать Index Seek вместо Table Scan и его производительность ЦП запросов падает на моем компьютере до 16 мс.
У меня два вопроса: (1) почему решение с условной агрегацией не превосходит решение подзапроса, по крайней мере, в случае без индекса, (2) возможно ли создать "индекс" для решения с условной агрегацией (или переписать запрос условной агрегации) во избежание сканирования или условное агрегирование вообще не подходит, если мы обеспокоены производительностью?
Примечание: могу сказать, что этот сценарий достаточно оптимистичен для условной агрегации, поскольку мы выбираем количество всех строк, что всегда приводит к решению с использованием сканирования. Если количество всех строк не требуется, то индексированное решение с подзапросами не сканирует, тогда как решение с условной агрегацией должно выполнить сканирование в любом случае.
РЕДАКТИРОВАТЬ
Владимир Баранов в основном ответил на первый вопрос (большое спасибо). Однако второй вопрос остается. Я могу видеть ответы Stackru, использующие решения для условного агрегирования, довольно обременительные, и они привлекают большое внимание, будучи принятыми в качестве наиболее элегантного и понятного решения (а иногда и предлагаемого в качестве наиболее эффективного решения). Поэтому я немного обобщу вопрос:
Не могли бы вы привести пример, когда условное агрегирование заметно превосходит решение подзапроса?
Для простоты предположим, что физического доступа нет (данные находятся в кеше буфера), поскольку современные серверы баз данных в любом случае сохраняют большую часть своих данных в памяти.
1 ответ
Краткое содержание
- Производительность метода подзапросов зависит от распределения данных.
- Производительность условного агрегирования не зависит от распределения данных.
Метод подзапросов может быть быстрее или медленнее, чем условное агрегирование, это зависит от распределения данных.
Естественно, если таблица имеет подходящий индекс, то подзапросы, вероятно, выиграют от этого, потому что индекс позволит сканировать только соответствующую часть таблицы вместо полного сканирования. Наличие подходящего индекса вряд ли значительно выиграет от метода условной агрегации, поскольку в любом случае он будет сканировать полный индекс. Единственным преимуществом было бы, если индекс уже таблицы и движок должен будет читать меньше страниц в памяти.
Зная это, вы можете решить, какой метод выбрать.
Первый тест
Я сделал большую тестовую таблицу, с 5M строк. На столе не было индексов. Я измерил статистику ввода-вывода и процессора с помощью SQL Sentry Plan Explorer. Я использовал SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64-bit для этих тестов.
Действительно, ваши исходные запросы вели себя так, как вы описали, то есть подзапросы выполнялись быстрее, хотя чтение было в 3 раза выше.
После нескольких попыток таблицы без индекса я переписал ваш условный агрегат и добавил переменные для хранения значения DATEADD выражения.
Общее время стало значительно быстрее.
Потом я заменил SUM с COUNT и это стало немного быстрее снова.
В конце концов, условное агрегирование стало почти таким же быстрым, как и подзапросы.
Нагреть кеш (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Подзапросы (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Исходная условная агрегация (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Условное агрегирование с переменными (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Условное агрегирование с переменными и COUNT вместо SUM (CPU = 1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Основываясь на этих результатах, я предполагаю, что CASE вызывается DATEADD для каждого ряда, в то время как WHERE был достаточно умен, чтобы рассчитать это один раз. плюс COUNT чуть-чуть эффективнее, чем SUM,
В конце концов, условная агрегация только немного медленнее, чем подзапросы (1062 против 1031), возможно, потому что WHERE немного эффективнее, чем CASE сам по себе, и кроме того, WHERE отфильтровывает довольно много строк, так COUNT должен обрабатывать меньше строк.
На практике я бы использовал условную агрегацию, потому что я думаю, что число операций чтения более важно. Если ваша таблица невелика по размеру и остается в пуле буферов, тогда любой запрос будет быстрым для конечного пользователя. Но если таблица больше доступной памяти, то я ожидаю, что чтение с диска значительно замедлит подзапросы.
Второй тест
С другой стороны, фильтрация строк как можно раньше также важна.
Вот небольшая вариация теста, которая это демонстрирует. Здесь я установил порог GETDATE() + 100 лет, чтобы убедиться, что ни одна строка не удовлетворяет критериям фильтра.
Нагреть кеш (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Подзапросы (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Исходная условная агрегация (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Условное агрегирование с переменными (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Условное агрегирование с переменными и COUNT вместо SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Ниже приведен план с подзапросами. Вы можете видеть, что во втором подзапросе в Строковый агрегат вошло 0 строк, все они были отфильтрованы на этапе сканирования таблицы.

В результате, подзапросы снова быстрее.
Третий тест
Здесь я изменил критерии фильтрации предыдущего теста: все > были заменены на <, В результате условно COUNT посчитал все строки вместо ни одного. Сюрприз Сюрприз! Условный запрос агрегации занял те же 750 мс, а подзапросов стало 813 вместо 500.

Вот план для подзапросов:

Не могли бы вы привести пример, когда условное агрегирование заметно превосходит решение подзапроса?
Вот. Производительность метода подзапросов зависит от распределения данных. Производительность условного агрегирования не зависит от распределения данных.
Метод подзапросов может быть быстрее или медленнее, чем условное агрегирование, это зависит от распределения данных.
Зная это, вы можете решить, какой метод выбрать.
Детали бонуса
Если навести курсор мыши на Table Scan Оператор вы можете увидеть Actual Data Size в разных вариантах.
- просто
COUNT(*):

- Условная агрегация:

- Подзапрос в тесте 2:

- Подзапрос в тесте 3:

Теперь становится ясно, что разница в производительности, вероятно, вызвана разницей в количестве данных, которые проходят через план.
В случае простого COUNT(*) здесь нет Output list (значения столбцов не требуются), а размер данных наименьший (43 МБ).
В случае условной агрегации эта сумма не меняется между тестами 2 и 3, она всегда составляет 72 МБ. Output list имеет один столбец datesent,
В случае подзапросов эта сумма изменяется в зависимости от распределения данных.
Вот мой пример, когда подзапросы в больших таблицах выполнялись очень медленно (около 40-50 секунд), и мне посоветовали переписать запрос с помощью FILTER(Условное агрегирование), которое ускорило его до 1 секунды. Я был удивлен.
Теперь я всегда использую FILTERУсловный Aggregation, потому что вы присоединитесь только на больших столах только один раз, и все поиск осуществляется с помощьюFILTER. На больших таблицах делать подвыборку - плохая идея.
Тема: Проблемы производительности SQL с внутренними выборками в Postgres для табличного отчета
Мне нужен был табличный отчет, а именно:
Пример (сначала простой плоский материал, затем сложный табулированный материал):
RecallID | RecallDate | Event |..| WalkAlone | WalkWithPartner |..| ExerciseAtGym
256 | 10-01-19 | Exrcs |..| NULL | NULL |..| yes
256 | 10-01-19 | Walk |..| yes | NULL |..| NULL
256 | 10-01-19 | Eat |..| NULL | NULL |..| NULL
257 | 10-01-19 | Exrcs |..| NULL | NULL |..| yes
В моем SQL были внутренние выборки для табличных столбцов, основанных на ответах, и они выглядели так:
select
-- Easy flat stuff first
r.id as recallid, r.recall_date as recalldate, ... ,
-- Example of Tabulated Columns:
(select l.description from answers_t ans, activity_questions_t aq, lookup_t l
where l.id=aq.answer_choice_id and aq.question_id=13
and aq.id=ans.activity_question_id and aq.activity_id=27 and ans.event_id=e.id)
as transportationotherintensity,
(select l.description from answers_t ans, activity_questions_t aq, lookup_t l
where l.id=66 and l.id=aq.answer_choice_id and aq.question_id=14
and aq.id=ans.activity_question_id and ans.event_id=e.id)
as commutework,
(select l.description from answers_t ans, activity_questions_t aq, lookup_t l
where l.id=67 and l.id=aq.answer_choice_id and aq.question_id=14 and aq.id=ans.activity_question_id and ans.event_id=e.id)
as commuteschool,
(select l.description from answers_t ans, activity_questions_t aq, lookup_t l
where l.id=95 and l.id=aq.answer_choice_id and aq.question_id=14 and aq.id=ans.activity_question_id and ans.event_id=e.id)
as dropoffpickup,
Спектакль был ужасен. Гордон Линофф рекомендовал одноразовое присоединение к большой таблице ANSWERS_T сFILTERпо мере необходимости для всех выбранных в таблице. Это ускорило его до 1 секунды.
select ans.event_id,
max(l.description) filter (where aq.question_id = 13 and aq.activity_id = 27) as transportationotherintensity
max(l.description) filter (where l.id = 66 and aq.question_id = 14 and aq.activity_id = 67) as commutework,
. . .
from activity_questions_t aq join
lookup_t l
on l.id = aq.answer_choice_id join
answers_t ans
on aq.id = ans.activity_question_id
group by ans.event_id