Многоразовая библиотека, чтобы получить удобочитаемую версию размера файла?
В Интернете существуют различные фрагменты, которые дают вам функцию, позволяющую возвращать читаемый размер человека из размера в байтах:
>>> human_readable(2048)
'2 kilobytes'
>>>
Но есть ли библиотека Python, которая обеспечивает это?
30 ответов
Решение указанной выше проблемы "слишком маленькая задача, чтобы требовать библиотеки" с помощью простой реализации:
def sizeof_fmt(num, suffix='B'):
for unit in ['','Ki','Mi','Gi','Ti','Pi','Ei','Zi']:
if abs(num) < 1024.0:
return "%3.1f%s%s" % (num, unit, suffix)
num /= 1024.0
return "%.1f%s%s" % (num, 'Yi', suffix)
Поддержка:
- все известные на данный момент бинарные префиксы
- отрицательные и положительные числа
- числа больше 1000 йобибайт
- произвольные единицы (возможно, вам нравится считать в гибибитах!)
Пример:
>>> sizeof_fmt(168963795964)
'157.4GiB'
Библиотека, которая обладает всеми функциями, которые, как вам кажется, вы ищете, humanize, humanize.naturalsize() кажется, делает все, что вы ищете.
Отходя от решения Шридхара Ратнакумара, мне это нравится немного лучше. Работает в Python 3.6+
def human_readable_size(size, decimal_places):
for unit in ['','KB','MB','GB','TB']:
if size < 1024.0:
break
size /= 1024.0
return f"{size:.{decimal_places}f}{unit}"
Всегда должен быть один из тех парней. Ну, сегодня это я. Вот однострочное решение - или две строки, если вы посчитаете сигнатуру функции.
def human_size(bytes, units=[' bytes','KB','MB','GB','TB', 'PB', 'EB']):
""" Returns a human readable string reprentation of bytes"""
return str(bytes) + units[0] if bytes < 1024 else human_size(bytes>>10, units[1:])
>>> human_size(123)
123 bytes
>>> human_size(123456789)
117GB
Вот моя версия. Он не использует цикл for. Он имеет постоянную сложность, O (1), и в теории более эффективен, чем ответы здесь, которые используют цикл for.
from math import log
unit_list = zip(['bytes', 'kB', 'MB', 'GB', 'TB', 'PB'], [0, 0, 1, 2, 2, 2])
def sizeof_fmt(num):
"""Human friendly file size"""
if num > 1:
exponent = min(int(log(num, 1024)), len(unit_list) - 1)
quotient = float(num) / 1024**exponent
unit, num_decimals = unit_list[exponent]
format_string = '{:.%sf} {}' % (num_decimals)
return format_string.format(quotient, unit)
if num == 0:
return '0 bytes'
if num == 1:
return '1 byte'
Чтобы было более понятно, что происходит, мы можем опустить код для форматирования строки. Вот строки, которые на самом деле делают работу:
exponent = int(log(num, 1024))
quotient = num / 1024**exponent
unit_list[exponent]
Хотя я знаю, что этот вопрос древний, я недавно придумал версию, которая избегает циклов, используя log2 чтобы определить порядок размеров, который удваивается как сдвиг и индекс в списке суффиксов:
from math import log2
_suffixes = ['bytes', 'KiB', 'MiB', 'GiB', 'TiB', 'PiB', 'EiB', 'ZiB', 'YiB']
def file_size(size):
# determine binary order in steps of size 10
# (coerce to int, // still returns a float)
order = int(log2(size) / 10) if size else 0
# format file size
# (.4g results in rounded numbers for exact matches and max 3 decimals,
# should never resort to exponent values)
return '{:.4g} {}'.format(size / (1 << (order * 10)), _suffixes[order])
Впрочем, вполне может считаться непифоническим из-за его читабельности:)
Если вы используете Django, вы также можете попробовать формат файла:
from django.template.defaultfilters import filesizeformat
filesizeformat(1073741824)
=>
"1.0 GB"
Вы должны использовать "гуманизировать".
>>> humanize.naturalsize(1000000)
'1.0 MB'
>>> humanize.naturalsize(1000000, binary=True)
'976.6 KiB'
>>> humanize.naturalsize(1000000, gnu=True)
'976.6K'
Ссылка:
Одна такая библиотека - спешите.
>>> from hurry.filesize import alternative
>>> size(1, system=alternative)
'1 byte'
>>> size(10, system=alternative)
'10 bytes'
>>> size(1024, system=alternative)
'1 KB'
Использование степеней 1000 или кибибайт было бы более стандартным:
def sizeof_fmt(num, use_kibibyte=True):
base, suffix = [(1000.,'B'),(1024.,'iB')][use_kibibyte]
for x in ['B'] + map(lambda x: x+suffix, list('kMGTP')):
if -base < num < base:
return "%3.1f %s" % (num, x)
num /= base
return "%3.1f %s" % (num, x)
PS Никогда не доверяйте библиотеке, которая печатает тысячи с суффиксом K (заглавными буквами):)
Это будет делать то, что вам нужно практически в любой ситуации, настраивается с помощью необязательных аргументов и, как вы можете видеть, в значительной степени самодокументируется:
from math import log
def pretty_size(n,pow=0,b=1024,u='B',pre=['']+[p+'i'for p in'KMGTPEZY']):
pow,n=min(int(log(max(n*b**pow,1),b)),len(pre)-1),n*b**pow
return "%%.%if %%s%%s"%abs(pow%(-pow-1))%(n/b**float(pow),pre[pow],u)
Пример вывода:
>>> pretty_size(42)
'42 B'
>>> pretty_size(2015)
'2.0 KiB'
>>> pretty_size(987654321)
'941.9 MiB'
>>> pretty_size(9876543210)
'9.2 GiB'
>>> pretty_size(0.5,pow=1)
'512 B'
>>> pretty_size(0)
'0 B'
Расширенные настройки:
>>> pretty_size(987654321,b=1000,u='bytes',pre=['','kilo','mega','giga'])
'987.7 megabytes'
>>> pretty_size(9876543210,b=1000,u='bytes',pre=['','kilo','mega','giga'])
'9.9 gigabytes'
Этот код совместим с Python 2 и Python 3. Соответствие PEP8 - упражнение для читателя. Помните, что это красивый вывод.
Обновить:
Если вам нужны тысячи запятых, просто примените очевидное расширение:
def prettier_size(n,pow=0,b=1024,u='B',pre=['']+[p+'i'for p in'KMGTPEZY']):
r,f=min(int(log(max(n*b**pow,1),b)),len(pre)-1),'{:,.%if} %s%s'
return (f%(abs(r%(-r-1)),pre[r],u)).format(n*b**pow/b**float(r))
Например:
>>> pretty_units(987654321098765432109876543210)
'816,968.5 YiB'
Проект HumanFriendly помогает в этом.
import humanfriendly
humanfriendly.format_size(1024)
Приведенный выше код даст 1 КБ в качестве ответа.
Примеры можно найти здесь.
Перейдя к фрагменту, предоставленному в качестве альтернативы hurry.filesize(), здесь приведен фрагмент, который дает числа с различной точностью в зависимости от используемого префикса. Это не так кратко, как некоторые фрагменты, но мне нравятся результаты.
def human_size(size_bytes):
"""
format a size in bytes into a 'human' file size, e.g. bytes, KB, MB, GB, TB, PB
Note that bytes/KB will be reported in whole numbers but MB and above will have greater precision
e.g. 1 byte, 43 bytes, 443 KB, 4.3 MB, 4.43 GB, etc
"""
if size_bytes == 1:
# because I really hate unnecessary plurals
return "1 byte"
suffixes_table = [('bytes',0),('KB',0),('MB',1),('GB',2),('TB',2), ('PB',2)]
num = float(size_bytes)
for suffix, precision in suffixes_table:
if num < 1024.0:
break
num /= 1024.0
if precision == 0:
formatted_size = "%d" % num
else:
formatted_size = str(round(num, ndigits=precision))
return "%s %s" % (formatted_size, suffix)
Опираясь на все предыдущие ответы, вот мой взгляд на это. Это объект, который будет хранить размер файла в байтах как целое число. Но когда вы пытаетесь напечатать объект, вы автоматически получаете читаемую человеком версию.
class Filesize(object):
"""
Container for a size in bytes with a human readable representation
Use it like this::
>>> size = Filesize(123123123)
>>> print size
'117.4 MB'
"""
chunk = 1024
units = ['bytes', 'KB', 'MB', 'GB', 'TB', 'PB']
precisions = [0, 0, 1, 2, 2, 2]
def __init__(self, size):
self.size = size
def __int__(self):
return self.size
def __str__(self):
if self.size == 0: return '0 bytes'
from math import log
unit = self.units[min(int(log(self.size, self.chunk)), len(self.units) - 1)]
return self.format(unit)
def format(self, unit):
if unit not in self.units: raise Exception("Not a valid file size unit: %s" % unit)
if self.size == 1 and unit == 'bytes': return '1 byte'
exponent = self.units.index(unit)
quotient = float(self.size) / self.chunk**exponent
precision = self.precisions[exponent]
format_string = '{:.%sf} {}' % (precision)
return format_string.format(quotient, unit)
У современного Django есть собственный шаблон filesizeformat:
Форматирует значение как human-readable размер файла (т.е. "13 КБ", "4,1 МБ", "102 байта" и т. д.).
Например:
{{ value|filesizeformat }}
Если значение равно 123456789, вывод будет 117,7 МБ.
Дополнительная информация: https://docs.djangoproject.com/en/1.10/ref/templates/builtins/.
Мне нравится фиксированная точность десятичной версии senderle, так что это своего рода гибрид этого с ответом joctee выше (знаете ли вы, что вы можете взять журналы с нецелыми основаниями?):
from math import log
def human_readable_bytes(x):
# hybrid of https://stackru.com/a/10171475/2595465
# with https://stackru.com/a/5414105/2595465
if x == 0: return '0'
magnitude = int(log(abs(x),10.24))
if magnitude > 16:
format_str = '%iP'
denominator_mag = 15
else:
float_fmt = '%2.1f' if magnitude % 3 == 1 else '%1.2f'
illion = (magnitude + 1) // 3
format_str = float_fmt + ['', 'K', 'M', 'G', 'T', 'P'][illion]
return (format_str % (x * 1.0 / (1024 ** illion))).lstrip('0')
Чтобы получить размер файла в удобочитаемой форме, я создал эту функцию:
import os
def get_size(path):
size = os.path.getsize(path)
if size < 1024:
return f"{size} bytes"
elif size < 1024*1024:
return f"{round(size/1024, 2)} KB"
elif size < 1024*1024*1024:
return f"{round(size/(1024*1024), 2)} MB"
elif size < 1024*1024*1024*1024:
return f"{round(size/(1024*1024*1024), 2)} GB"
>>> get_size("a.txt")
1.4KB
Как насчет простого 2 лайнера:
def humanizeFileSize(filesize):
p = int(math.floor(math.log(filesize, 2)/10))
return "%.3f%s" % (filesize/math.pow(1024,p), ['B','KiB','MiB','GiB','TiB','PiB','EiB','ZiB','YiB'][p])
Вот как это работает под капотом:
- Вычисляет журнал2(размер файла)
- Делит его на 10, чтобы получить ближайшую единицу. (например, если размер 5000 байт, ближайший блок
Kbпоэтому ответ должен быть X КиБ) - Возвращает
file_size/value_of_closest_unitвместе с юнитом.
Это, однако, не работает, если размер файла равен 0 или отрицателен (поскольку журнал не определен для 0 и -ve чисел). Вы можете добавить дополнительные проверки для них:
def humanizeFileSize(filesize):
filesize = abs(filesize)
if (filesize==0):
return "0 Bytes"
p = int(math.floor(math.log(filesize, 2)/10))
return "%0.2f %s" % (filesize/math.pow(1024,p), ['Bytes','KiB','MiB','GiB','TiB','PiB','EiB','ZiB','YiB'][p])
Примеры:
>>> humanizeFileSize(538244835492574234)
'478.06 PiB'
>>> humanizeFileSize(-924372537)
'881.55 MiB'
>>> humanizeFileSize(0)
'0 Bytes'
ПРИМЕЧАНИЕ. - Существует разница между килобайтами и килобайтами. KB означает 1000 байтов, тогда как KiB означает 1024 байта. KB,MB,GB - это кратные 1000, тогда как KiB, MiB, GiB и т. Д. Кратны 1024. Подробнее об этом здесь
Вот лямбда oneliner без импорта для преобразования в удобочитаемый размер файла. Передайте значение в байтах.
to_human = lambda v : str(v >> ((max(v.bit_length()-1, 0)//10)*10)) +["", "K", "M", "G", "T", "P", "E"][max(v.bit_length()-1, 0)//10]
>>> to_human(1024)
'1K'
>>> to_human(1024*1024*3)
'3M'
def human_readable_data_quantity(quantity, multiple=1024):
if quantity == 0:
quantity = +0
SUFFIXES = ["B"] + [i + {1000: "B", 1024: "iB"}[multiple] for i in "KMGTPEZY"]
for suffix in SUFFIXES:
if quantity < multiple or suffix == SUFFIXES[-1]:
if suffix == SUFFIXES[0]:
return "%d%s" % (quantity, suffix)
else:
return "%.1f%s" % (quantity, suffix)
else:
quantity /= multiple
То, что вы собираетесь найти ниже, ни в коем случае не является самым эффективным или самым коротким решением среди уже опубликованных. Вместо этого он фокусируется на одной конкретной проблеме, которую пропускают многие другие ответы.
А именно тот случай, когда ввод нравится 999_995 дано:
Python 3.6.1 ...
...
>>> value = 999_995
>>> base = 1000
>>> math.log(value, base)
1.999999276174054
который, будучи усеченным до ближайшего целого числа и примененным обратно к входу, дает
>>> order = int(math.log(value, base))
>>> value/base**order
999.995
Похоже, это именно то, что мы ожидали, пока нам не нужно контролировать точность вывода. И это когда вещи начинают становиться немного сложнее.
С точностью до 2 цифр получаем:
>>> round(value/base**order, 2)
1000 # K
вместо 1M,
Как мы можем противостоять этому?
Конечно, мы можем проверить это явно:
if round(value/base**order, 2) == base:
order += 1
Но можем ли мы сделать лучше? Можем ли мы узнать, каким образом order должны быть сокращены, прежде чем мы сделаем последний шаг?
Оказывается, мы можем.
Предполагая правило округления 0,5 десятичного числа, выше if условие переводится в:
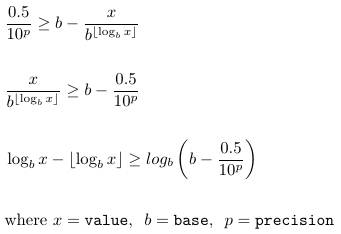
в результате чего
def abbreviate(value, base=1000, precision=2, suffixes=None):
if suffixes is None:
suffixes = ['', 'K', 'M', 'B', 'T']
if value == 0:
return f'{0}{suffixes[0]}'
order_max = len(suffixes) - 1
order = log(abs(value), base)
order_corr = order - int(order) >= log(base - 0.5/10**precision, base)
order = min(int(order) + order_corr, order_max)
factored = round(value/base**order, precision)
return f'{factored:,g}{suffixes[order]}'
дающий
>>> abbreviate(999_994)
'999.99K'
>>> abbreviate(999_995)
'1M'
>>> abbreviate(999_995, precision=3)
'999.995K'
>>> abbreviate(2042, base=1024)
'1.99K'
>>> abbreviate(2043, base=1024)
'2K'
Вот что я написал по другому вопросу ...
Как и xApple user287297 этот объект всегда будет печататься в удобочитаемом формате. Разница в том, что это также правильный ответ
class ByteSize(int):
_KB = 1024
_suffixes = 'B', 'KB', 'MB', 'GB', 'PB'
def __new__(cls, *args, **kwargs):
return super().__new__(cls, *args, **kwargs)
def __init__(self, *args, **kwargs):
self.bytes = self.B = int(self)
self.kilobytes = self.KB = self / self._KB**1
self.megabytes = self.MB = self / self._KB**2
self.gigabytes = self.GB = self / self._KB**3
self.petabytes = self.PB = self / self._KB**4
*suffixes, last = self._suffixes
suffix = next((
suffix
for suffix in suffixes
if 1 < getattr(self, suffix) < self._KB
), last)
self.readable = suffix, getattr(self, suffix)
super().__init__()
def __str__(self):
return self.__format__('.2f')
def __repr__(self):
return '{}({})'.format(self.__class__.__name__, super().__repr__())
def __format__(self, format_spec):
suffix, val = self.readable
return '{val:{fmt}} {suf}'.format(val=val, fmt=format_spec, suf=suffix)
def __sub__(self, other):
return self.__class__(super().__sub__(other))
def __add__(self, other):
return self.__class__(super().__add__(other))
def __mul__(self, other):
return self.__class__(super().__mul__(other))
def __rsub__(self, other):
return self.__class__(super().__sub__(other))
def __radd__(self, other):
return self.__class__(super().__add__(other))
def __rmul__(self, other):
return self.__class__(super().__rmul__(other))
Использование:
>>> size = 6239397620
>>> print(size)
5.81 GB
>>> size.GB
5.810891855508089
>>> size.gigabytes
5.810891855508089
>>> size.PB
0.005674699077644618
>>> size.MB
5950.353260040283
>>> size
ByteSize(6239397620)
Вот оно:
def humanSize(value, decimals=2, scale=1024, units=("B", "kiB", "MiB", "GiB", "TiB", "PiB", "EiB", "ZiB", "YiB", "RiB", "QiB")):
for unit in units:
if value < scale:
break
value /= scale
if int(value) == value:
# do not return decimals, if the value is already round
return int(value), unit
return round(value * 10**decimals) / 10**decimals, unit
Самый правильный формат:
f"{humanSize(os.path.getsize(path))[0]}\u202f{humanSize(os.path.getsize(path))[1]}"
Примеры:
>>> humanSize(42)
(42, 'B')
>>> humanSize(9137017301)
(8.51, 'GiB')
>>> humanSize(4096)
(4, 'kiB')
>>> humanSize(1267650600228229401496703205376)
(1, 'QiB')
>>> humanSize(543864)
(531.12, 'kiB')
>>> humanSize(500000000000)
(465.66, 'GiB')
Если кому-то интересно, чтобы преобразовать ответ @Sridhar Ratnakumar обратно в байты, вы можете сделать следующее:
import math
def format_back_to_bytes(value):
for power, unit in enumerate(["", "Ki", "Mi", "Gi", "Ti", "Pi", "Ei", "Zi"]):
if value[-3:-1] == unit:
return round(float(value[:-3])*math.pow(2, 10*power))
Использование:
>>> format_back_to_bytes('212.4GiB')
228062763418
Использовать
from naturalsize import *
nsize(500)
из модуля naturalsize.
Вот вариант использования
while:
def number_format(n):
n2, n3 = n, 0
while n2 >= 1e3:
n2 /= 1e3
n3 += 1
return '%.3f' % n2 + ('', ' k', ' M', ' G')[n3]
s = number_format(9012345678)
print(s == '9.012 G')
Эта функция, если она доступна в Boltons, является очень удобной библиотекой для большинства проектов.
>>> bytes2human(128991)
'126K'
>>> bytes2human(100001221)
'95M'
>>> bytes2human(0, 2)
'0.00B'
Обращаться Sridhar Ratnakumarответ, обновленный до:
def formatSize(sizeInBytes, decimalNum=1, isUnitWithI=False, sizeUnitSeperator=""):
"""format size to human readable string"""
# https://en.wikipedia.org/wiki/Binary_prefix#Specific_units_of_IEC_60027-2_A.2_and_ISO.2FIEC_80000
# K=kilo, M=mega, G=giga, T=tera, P=peta, E=exa, Z=zetta, Y=yotta
sizeUnitList = ['','K','M','G','T','P','E','Z']
largestUnit = 'Y'
if isUnitWithI:
sizeUnitListWithI = []
for curIdx, eachUnit in enumerate(sizeUnitList):
unitWithI = eachUnit
if curIdx >= 1:
unitWithI += 'i'
sizeUnitListWithI.append(unitWithI)
# sizeUnitListWithI = ['','Ki','Mi','Gi','Ti','Pi','Ei','Zi']
sizeUnitList = sizeUnitListWithI
largestUnit += 'i'
suffix = "B"
decimalFormat = "." + str(decimalNum) + "f" # ".1f"
finalFormat = "%" + decimalFormat + sizeUnitSeperator + "%s%s" # "%.1f%s%s"
sizeNum = sizeInBytes
for sizeUnit in sizeUnitList:
if abs(sizeNum) < 1024.0:
return finalFormat % (sizeNum, sizeUnit, suffix)
sizeNum /= 1024.0
return finalFormat % (sizeNum, largestUnit, suffix)
и пример вывода:
def testKb():
kbSize = 3746
kbStr = formatSize(kbSize)
print("%s -> %s" % (kbSize, kbStr))
def testI():
iSize = 87533
iStr = formatSize(iSize, isUnitWithI=True)
print("%s -> %s" % (iSize, iStr))
def testSeparator():
seperatorSize = 98654
seperatorStr = formatSize(seperatorSize, sizeUnitSeperator=" ")
print("%s -> %s" % (seperatorSize, seperatorStr))
def testBytes():
bytesSize = 352
bytesStr = formatSize(bytesSize)
print("%s -> %s" % (bytesSize, bytesStr))
def testMb():
mbSize = 76383285
mbStr = formatSize(mbSize, decimalNum=2)
print("%s -> %s" % (mbSize, mbStr))
def testTb():
tbSize = 763832854988542
tbStr = formatSize(tbSize, decimalNum=2)
print("%s -> %s" % (tbSize, tbStr))
def testPb():
pbSize = 763832854988542665
pbStr = formatSize(pbSize, decimalNum=4)
print("%s -> %s" % (pbSize, pbStr))
def demoFormatSize():
testKb()
testI()
testSeparator()
testBytes()
testMb()
testTb()
testPb()
# 3746 -> 3.7KB
# 87533 -> 85.5KiB
# 98654 -> 96.3 KB
# 352 -> 352.0B
# 76383285 -> 72.84MB
# 763832854988542 -> 694.70TB
# 763832854988542665 -> 678.4199PB
Это решение может также обратиться к вам, в зависимости от того, как работает ваш разум:
from pathlib import Path
def get_size(path = Path('.')):
""" Gets file size, or total directory size """
if path.is_file():
size = path.stat().st_size
elif path.is_dir():
size = sum(file.stat().st_size for file in path.glob('*.*'))
return size
def format_size(path, unit="MB"):
""" Converts integers to common size units used in computing """
bit_shift = {"B": 0,
"kb": 7,
"KB": 10,
"mb": 17,
"MB": 20,
"gb": 27,
"GB": 30,
"TB": 40,}
return "{:,.0f}".format(get_size(path) / float(1 << bit_shift[unit])) + " " + unit
# Tests and test results
>>> get_size("d:\\media\\bags of fun.avi")
'38 MB'
>>> get_size("d:\\media\\bags of fun.avi","KB")
'38,763 KB'
>>> get_size("d:\\media\\bags of fun.avi","kb")
'310,104 kb'