HANA: xsodata: огромный разрыв в производительности между выполнением первого и второго запросов
Если я выставлю ВИД
CREATE VIEW myView AS
SELECT ...
FROM ...
через xsodata
service namespace "oData" {
entity "mySchema"."myView" as "myView";
}
и GET /myView в первый раз после создания VIEW производительность очень низкая:
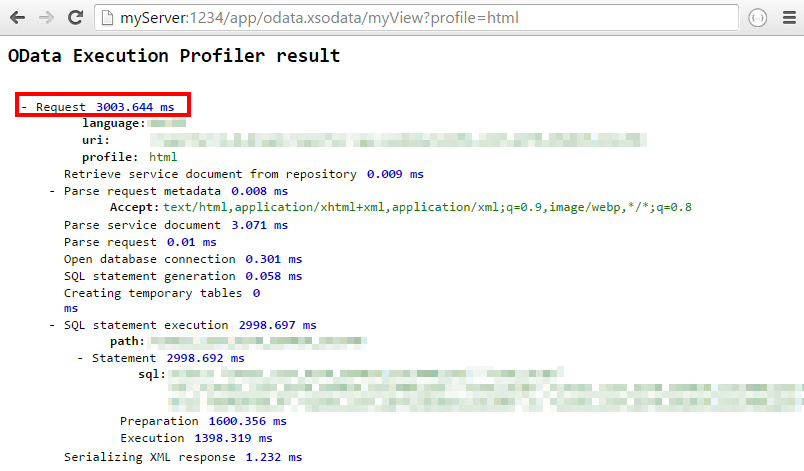
Однако: после выполнения одного и того же запроса (и каждый раз после этого) производительность должна быть такой, какой я хочу:
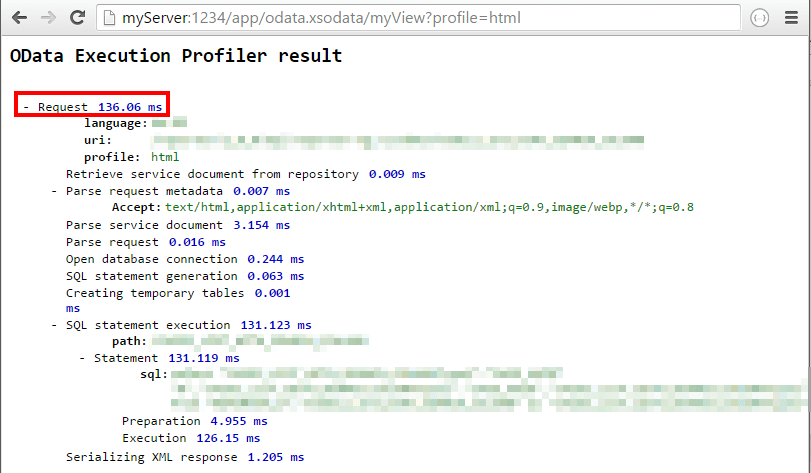
Вопросы:
Зачем?
Как избежать первого длительного запроса?
Уже попробовал:
Выполнение вывода профилировщика sql (без подготовки оператора) в SQL-консоли HANA Studios всегда дает хорошую производительность
Таблица горячей загрузки (
LOAD myTable ALL;) не имел никакого эффекта
Обновить
Мы выяснили причину "почему": xs-engine выполняет запрос как подготовленный оператор, даже если в запросе нет параметров. При первом выполнении (в контексте пользователя) запрос выполняется, что приводит к записи в M_SQL_PLAN_CACHE (SELECT * FROM M_SQL_PLAN_CACHE WHERE USER_NAME = 'myUser'). Очистка кэша плана (ALTER SYSTEM CLEAR SQL PLAN CACHE) снова делает запрос oData медленным, что приводит к предположению, что разрыв в производительности заключается в повторной подготовке запроса.
Теперь мы застряли со вторым вопросом: как этого избежать? Наш подход, чтобы пометить определенные записи плана кэша для перекомпиляции (ALTER SYSTEM RECOMPILE SQL PLAN CACHE ENTRY 123) просто аннулировал запись и не обновлял ее автоматически...
1 ответ
Я не уверен, что вы можете УДАЛИТЬ первое выполнение долгое время, но вы можете попробовать изменить представление на представление вычисления, выполненное в SQL Engine,
HANA Он был оптимизирован для использования его видов вычислений, и кэш-память плана должна работать с ними быстрее, возможно, значительно сократив время первого выполнения. Также планируем кеш калькуляции. Представления должны быть разделены между пользователями (так как _SYS_REPO это тот, кто их генерирует).
Если вы используете версию скрипта, я полагаю, что вы можете использовать большую часть вашего текущего SQL, но вы также можете попробовать использовать графический подход.
Дайте нам знать, если вам повезло. Моделирование с помощью больших данных - это всегда сюрприз.