Как работает кэш с прямым отображением?
Я прохожу курс "Архитектура системы" и не могу понять, как работает кэш с прямым отображением.
Я посмотрел в нескольких местах, и они объясняют это по-другому, что еще больше запутывает меня.
Я не могу понять, что такое тег и индекс, и как они выбраны?
Объяснение из моей лекции: "Адрес разделен на две части (например, 15 бит), которые используются для адресации (32 КБ) ОЗУ напрямую. Остальная часть адреса, тег сохраняется и сравнивается с входящим тегом".
Откуда этот тег? Это не может быть полный адрес ячейки памяти в ОЗУ, поскольку он делает бесполезным кэш с прямым отображением (по сравнению с полностью ассоциативным кешем).
Большое спасибо.
4 ответа
Хорошо. Итак, давайте сначала разберемся, как процессор взаимодействует с кешем.
Есть три слоя памяти (в широком смысле) - cache (как правило, из SRAM чипы), main memory (как правило, из DRAM чипсы) и storage (как правило, магнитные, как жесткие диски). Всякий раз, когда ЦП требуются какие-либо данные из какого-то определенного места, он сначала просматривает кеш, чтобы определить, есть ли он там. Кэш-память находится ближе всего к ЦП с точки зрения иерархии памяти, следовательно, ее время доступа является наименьшим (а стоимость наибольшей), поэтому, если ЦП данных там можно найти, это представляет собой "попадание", и данные оттуда получается для использования процессором. Если его там нет, то данные должны быть перемещены из основной памяти в кеш, прежде чем они будут доступны для ЦП (ЦП обычно взаимодействует только с кешем), что приводит к потере времени.
Таким образом, чтобы выяснить, есть ли данные в кэше или нет, применяются различные алгоритмы. Одним из них является метод прямого сопоставления кеша. Для простоты, давайте предположим систему памяти, в которой доступно 10 ячеек кэш-памяти (от 0 до 9) и 40 ячеек основной памяти (от 0 до 39). Эта картина подводит итог:
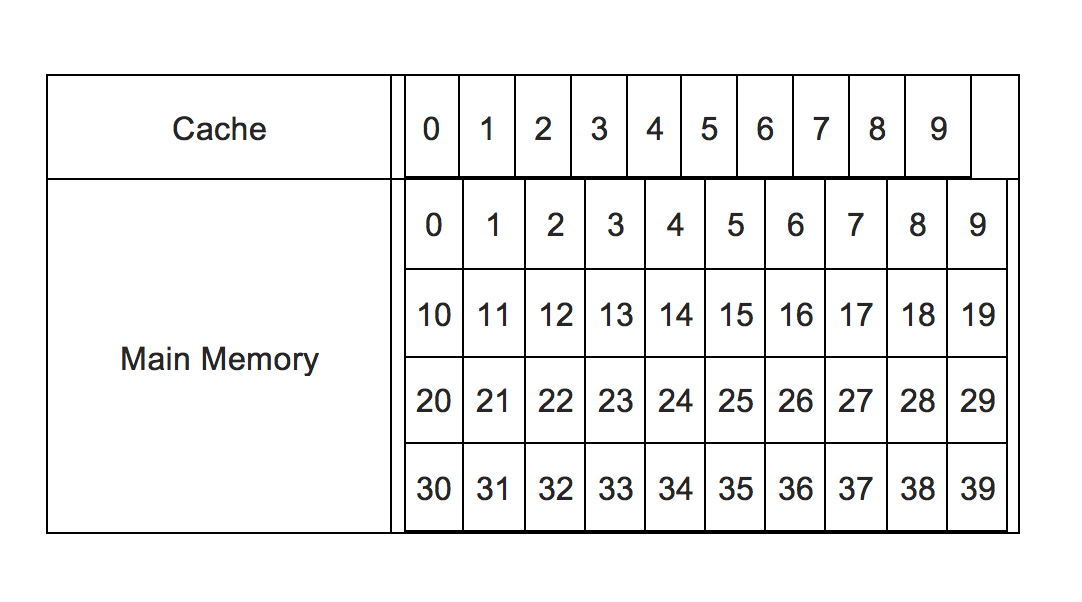
Доступно 40 основных областей памяти, но в кеше можно разместить только до 10. Так что теперь, каким-то образом, входящий запрос от ЦП должен быть перенаправлен в местоположение кеша. Это имеет две проблемы:
Как перенаправить? В частности, как это сделать предсказуемым образом, который не изменится со временем?
Если место в кеше уже заполнено некоторыми данными, входящий запрос от ЦП должен определить, совпадает ли адрес, с которого ему требуются данные, с адресом, данные которого хранятся в этом месте.
В нашем простом примере мы можем перенаправить с помощью простой логики. Учитывая, что мы должны отобразить 40 основных областей памяти, пронумерованных последовательно от 0 до 39 до 10 областей кэша, пронумерованных от 0 до 9, местоположение кэша для области памяти n может быть n%10, Таким образом, 21 соответствует 1, 37 соответствует 7 и т. Д. Это становится индексом.
Но 37, 17, 7 все соответствуют 7. Таким образом, чтобы различать между ними, следует тег. Так же, как индекс n%10тег есть int(n/10), Таким образом, теперь 37, 17, 7 будут иметь одинаковый индекс 7, но разные теги, такие как 3, 1, 0 и т. Д. То есть отображение может быть полностью задано двумя данными - тегом и индексом.
Так что теперь, если приходит запрос для адреса местоположения 29, это преобразуется в тег 2 и индекс 9. Индекс соответствует номеру ячейки кеша, поэтому ячейка кеша нет. 9 будет запрошен, чтобы увидеть, содержит ли он какие-либо данные, и если да, если связанный тег равен 2. Если да, это попадание ЦП, и данные будут немедленно получены из этого места. Если он пуст или тег не равен 2, это означает, что он содержит данные, соответствующие некоторому другому адресу памяти, а не 29 (хотя он будет иметь такой же индекс, что означает, что он содержит данные с адреса, такого как 9, 19, 39 и т. Д.). Так что это промах ЦП, а данных из локации нет. 29 в основной памяти должен быть загружен в кэш в местоположении 29 (и тег был изменен на 2, и удаляются все данные, которые были там прежде), после чего он будет выбираться ЦП.
Давайте использовать пример. Кэш-память объемом 64 килобайта с 16-байтовыми строками кэша содержит 4096 различных строк кэша.
Вам нужно разбить адрес на три части.
- Младшие биты используются, чтобы сообщать вам байт в строке кэша, когда вы его возвращаете, эта часть напрямую не используется при поиске в кэше. (биты 0-3 в этом примере)
- Следующие биты используются для индексации кэша. Если вы думаете о кеше как о большом столбце строк кэша, биты индекса сообщают вам, в какой строке вы должны искать свои данные. (биты 4-15 в этом примере)
- Все остальные биты являются битами TAG. Эти биты хранятся в хранилище тегов для данных, которые вы сохранили в кеше, и мы сравниваем соответствующие биты запроса кеша с тем, что мы сохранили, чтобы выяснить, являются ли данные, которые мы кэшируем, данными, которые запрашиваются.
Число битов, которые вы используете для индекса, составляет log_base_2(number_of_cache_lines) [это действительно количество наборов, но в кеше с прямым отображением имеется такое же количество строк и наборов]
Кэш прямого отображения подобен таблице, в которой есть строки, также называемые строкой кэша, и по крайней мере 2 столбца, один для данных, а другой - для тегов.
Вот как это работает: доступ для чтения в кэш занимает среднюю часть адреса, которая называется индексом, и использует его в качестве номера строки. Данные и тег ищутся одновременно. Затем необходимо сравнить тег с верхней частью адреса, чтобы определить, является ли строка из того же диапазона адресов в памяти и является ли она действительной. В то же время нижняя часть адреса может использоваться для выбора запрошенных данных из строки кэша (я предполагаю, что строка кэша может содержать данные для нескольких слов).
Я сделал небольшой акцент на доступ к данным и доступ к тегам + сравнение происходит одновременно, потому что это является ключом к уменьшению задержки (назначение кэша). Для доступа к оперативной памяти не требуется двух шагов.
Преимущество заключается в том, что чтение - это простой поиск в таблице и сравнение.
Но это прямое сопоставление означает, что для каждого адреса чтения в кеше есть только одно место, где эти данные могут быть кэшированы. Таким образом, недостатком является то, что многие другие адреса будут отображаться в одно и то же место и могут конкурировать за эту строку кэша.
Я нашел хорошую книгу в библиотеке, которая дала мне четкое объяснение, в котором я нуждался, и сейчас я поделюсь им здесь на случай, если какой-нибудь другой студент наткнется на эту ветку при поиске кешей.
Книга "Компьютерная архитектура - количественный подход", 3-е издание, Хеннеси и Паттерсон, страница 390.
Во-первых, имейте в виду, что основная память делится на блоки для кеша. Если у нас кэш-память объемом 64 байта и 1 ГБ ОЗУ, ОЗУ будет разделено на блоки размером 128 КБ (1 ГБ ОЗУ / 64 КБ кэш-памяти = размер блока 128 КБ).
Из книги:
Где можно поместить блок в кеш?
- Если у каждого блока есть только одно место, он может появиться в кеше, кеш называется прямым отображением. Блок назначения рассчитывается по следующей формуле:
<RAM Block Address> MOD <Number of Blocks in the Cache>
Итак, давайте предположим, что у нас 32 блока оперативной памяти и 8 блоков кеш-памяти.
Если мы хотим сохранить блок 12 из ОЗУ в кэш, блок 12 ОЗУ будет сохранен в блоке 4 кэша. Почему? Потому что 12 / 8 = 1 остаток 4. Остаток является целевым блоком.
Если блок может быть размещен где-нибудь в кеше, кеш считается полностью ассоциативным.
Если блок может быть размещен где-либо в ограниченном наборе мест в кеше, кеш устанавливается ассоциативно.
По сути, набор - это группа блоков в кеше. Блок сначала отображается на набор, а затем блок может быть размещен в любом месте внутри набора.
Формула: <RAM Block Address> MOD <Number of Sets in the Cache>
Итак, давайте предположим, что у нас есть 32 блока оперативной памяти и кэш, разделенный на 4 набора (каждый набор имеет два блока, то есть всего 8 блоков). Таким образом, набор 0 будет иметь блоки 0 и 1, набор 1 будет иметь блоки 2 и 3 и так далее...
Если мы хотим сохранить блок 12 ОЗУ в кеше, блок ОЗУ будет храниться в блоках кеша 0 или 1. Почему? Потому что 12 / 4 = 3 остатка 0. Поэтому набор 0 выбран, и блок может быть размещен в любом месте внутри набора 0 (имеется в виду блок 0 и 1).
Теперь я вернусь к своей первоначальной проблеме с адресами.
Как найти блок, если он находится в кеше?
Каждый кадр кадра в кеше имеет адрес. Просто чтобы прояснить, блок имеет как адрес, так и данные.
Адрес блока делится на несколько частей: тег, индекс и смещение.
Тег используется для поиска блока внутри кэша, индекс показывает только набор, в котором находится блок (что делает его довольно избыточным), а смещение используется для выбора данных.
Под "выбором данных" я подразумеваю, что в блоке кэша, очевидно, будет более одной ячейки памяти, смещение используется для выбора между ними.
Итак, если вы хотите представить таблицу, это будут столбцы:
TAG | INDEX | OFFSET | DATA 1 | DATA 2 | ... | DATA N
Тег будет использоваться для поиска блока, индекс будет показывать, в каком наборе находится блок, смещение выберет одно из полей справа.
Я надеюсь, что мое понимание этого правильно, если это не так, пожалуйста, дайте мне знать.