Что происходит, когда мастер Kubernetes терпит неудачу?
Я пытался выяснить, что происходит, когда мастер Kubernetes терпит неудачу в кластере, который имеет только один мастер. Веб-запросы все еще направляются к модулям, если это происходит, или вся система просто закрывается?
Согласно документации OpenShift 3, которая построена поверх Kubernetes, ( https://docs.openshift.com/enterprise/3.2/architecture/infrastructure_components/kubernetes_infrastructure.html), если мастер не работает, узлы продолжают функционировать должным образом, но система теряет способность управлять модулями. Это то же самое для ванильных Kubernetes?
3 ответа
Насколько я понимаю, мастер запускает API, и теперь (начиная с версии 1.3?) Управляет базовой облачной инфраструктурой. Когда он находится в автономном режиме, API будет в автономном режиме, поэтому кластер перестает быть кластером и вместо этого является группой специальных узлов для этого периода. Кластер не сможет реагировать на сбои узлов, создавать новые ресурсы, перемещать модули на новые узлы и т. Д., Пока мастер не вернется в оперативный режим.
Однако, в любом случае, жизнь приложений будет продолжаться как обычно, если в течение этого времени не произойдет какого-либо существенного сбоя *, или узлы не будут перезагружены, потому что службы TCP/ UDP, балансировщики нагрузки, DNS, панель мониторинга и т. Д. Если все продолжать функционировать.
После некоторого чтения кажется, что DNS-запросы могут не разрешаться правильно, если узел перезагружается в течение этого времени. Я определенно рекомендую не перезагружать узлы в течение этого периода, если вы беспокоитесь о том, что ваши службы остаются доступными.
Если вы хотите проверить это самостоятельно, есть удобная утилита под названием minikube, которую вы можете использовать, чтобы "попробовать перед покупкой". Помните (если вы из будущего), что Kubernetes все еще быстро меняется, и этот ответ, возможно, больше не будет верным в то время, когда вы родом.
Кластер Kubernetes без мастера похож на компанию без менеджера.
Никто другой не может проинструктировать воркеров (компоненты k8s), кроме Менеджера (главного узла)
(даже вы, владелец кластера, можете проинструктировать только Менеджера)
Все работает как обычно. Пока работа не будет завершена или что-то их не остановит (потому что главный узел умер после назначения работ)
Поскольку нет Менеджера, который мог бы переназначить им какую-либо работу, рабочие будут ждать и ждать, пока Менеджер не вернется.
Лучше всего назначить вашему кластеру несколько менеджеров (главных).
Хотя ваша плоскость данных и работающие приложения не сразу начинают ломаться, но есть несколько сценариев, когда администраторы кластера захотят иметь настройку с несколькими мастерами. Ключом к пониманию влияния будет понимание того, какие все компоненты взаимодействуют с мастером, о чем и как и, что более важно, когда они перестанут работать, если мастер выйдет из строя.
Хотя модули ваших приложений, работающие в плоскости данных, не будут затронуты немедленно, но представьте себе очень возможный сценарий — ваш трафик внезапно вырос, и ваш горизонтальный автомасштабатор модуля сработал. Автомасштабирование не будет работать, поскольку сервер метрик собирает метрики ресурсов из Kubelets и предоставляет их в Kubernetes. apiserver через Metrics API для использования Horizontal Pod Autoscaler и вертикальным автомасштабированием pod (но ваш API-сервер уже не работает). Если память вашего pod'а увеличивается из-за высокой нагрузки, это в конечном итоге приведет к тому, что его убьет k8s OOM killer. Если какой-либо из модулей умрет, то, поскольку диспетчер контроллера и планировщик общаются с сервером API, чтобы следить за текущим состоянием модулей, они тоже потерпят неудачу. Короче говоря, новый модуль не будет запланирован, и ваше приложение может перестать отвечать.
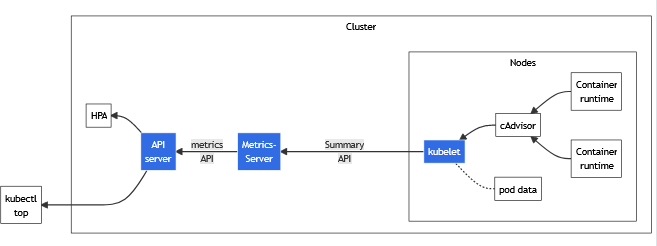
Следует подчеркнуть, что системные компоненты Kubernetes взаимодействуют только с сервером API. Они не разговаривают друг с другом напрямую, поэтому я думаю, что их функциональность может выйти из строя. Недоступность мастер-плоскости может означать несколько вещей: сбой любого или всех этих компонентов — сервера API и т. д., планировщика кубов, диспетчера контроллеров или, что еще хуже, сбой всего узла.
Если сервер API недоступен — никто не может использовать kubectl, так как обычно все команды общаются с сервером API (это означает, что вы не можете подключиться к кластеру, не можете войти ни в какие модули, чтобы проверить что-либо в файловой системе контейнера. Вы не сможете просматривать журналы приложений, если только у вас есть какая-либо дополнительная централизованная система управления журналами).
Если база данных etcd вышла из строя или была повреждена — все данные о состоянии вашего кластера исчезли, и администраторы захотят восстановить их из резервных копий как можно раньше.
Короче говоря, сбой одной основной плоскости управления, хотя и не может сразу повлиять на возможности обслуживания трафика, но на него нельзя полагаться при обслуживании вашего трафика.