Как выбрать столбцы данных в DataFrame
Я получаю результаты опроса из Lime Survey через его API (Remote Control):

И мне удается поместить его в DataFrame. Но это только 1 столбец на строку:
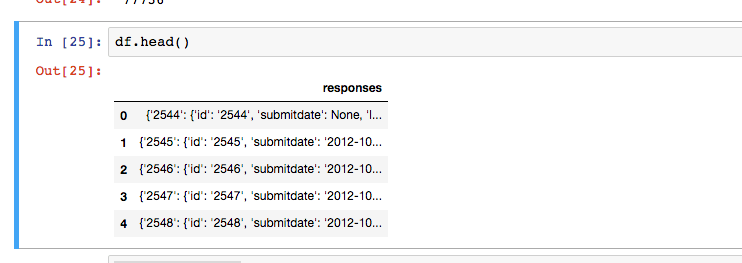
Данные выглядят так.
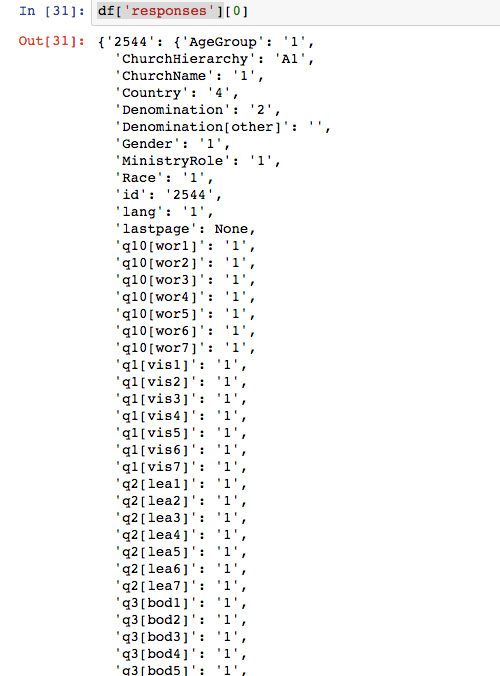
То, что я хочу сделать, это получить средние данные по вопросам и категориям. Из приведенного ниже примера: q10[wor1], q10[wor2], .,., Q10 [WOR7] дать 7 вопросов, которые являются частью категории Q10.
Как сначала выбрать все данные для wor1, wor2, ..., wor7, отдельно, чтобы я мог делать статистику по каждому из этих отдельных вопросов.
Тогда как мне выбрать все данные для q10*, чтобы я мог делать статистику для всей группы?
Даже не пытаясь отделить категорию от вопроса, я не смог выбрать только все данные "q10 [wor1]".
1 ответ
Проверьте jq - https://stedolan.github.io/jq/
Вы можете передать свой df ['response'] json в jq, извлечь необходимое поле и создать его в виде отдельного столбца df.
И тогда вы можете получить среднее значение столбцов из DF.