Как оценить миллион изображений с помощью краудсорсинга
Я хотел бы оценить коллекцию пейзажных изображений, создав игру, в которой посетители сайта могут оценивать их, чтобы выяснить, какие изображения люди находят наиболее привлекательными.
Что было бы хорошим способом сделать это?
- Горячий или нет стиль? Т.е. показать одно изображение, попросить пользователя оценить его от 1 до 10. На мой взгляд, это позволяет мне усреднять баллы, и мне просто нужно обеспечить равномерное распределение голосов по всем изображениям. Довольно прост в реализации.
- Выберите А-или-Б? Т.е. показать два изображения, попросить пользователя выбрать лучшее. Это привлекательно, так как нет числового ранжирования, это просто сравнение. Но как бы я это реализовал? Моей первой мыслью было сделать это как быструю сортировку, с операциями сравнения, выполняемыми людьми, и после завершения просто повторить сортировку до бесконечности.
Как бы вы это сделали?
Если вам нужны цифры, я говорю о миллионе изображений на сайте с 20000 ежедневных посещений. Я полагаю, что небольшая часть может сыграть в игру ради аргумента, скажем, я могу производить 2000 операций сортировки людей в день! Это некоммерческий сайт, и любопытные найдут его в моем профиле:)
12 ответов
Как уже говорили другие, рейтинг 1-10 не работает так хорошо, потому что люди имеют разные уровни.
Проблема метода Pick A-or-B состоит в том, что для системы не гарантируется транзитивность системы (A может бить B, но B бьет C, а C бьет A). Наличие нетранзитивных операторов сравнения нарушает алгоритмы сортировки. При использовании быстрой сортировки в этом примере буквы, не выбранные в качестве точки разворота, будут неправильно ранжироваться друг против друга.
В любой момент вы хотите получить абсолютный рейтинг всех картинок (даже если некоторые / все они связаны). Вы также хотите, чтобы ваш рейтинг не изменился, если кто-то не проголосует.
Я бы использовал метод Pick A-or-B (или ничью), но определил бы рейтинг, аналогичный системе рейтингов Elo, которая используется для рейтингов в играх с двумя игроками (изначально шахматы):
Система рейтинга игроков Эло сравнивает записи матчей игроков с записями матчей их противников и определяет вероятность того, что игрок выиграет матч. Этот коэффициент вероятности определяет, сколько очков рейтинг игроков повышается или понижается на основе результатов каждого матча. Когда игрок побеждает противника с более высоким рейтингом, рейтинг игрока возрастает больше, чем если бы он побеждал игрока с более низким рейтингом (поскольку игроки должны победить противников с более низким рейтингом).
Система Эло:
- Все новые игроки начинают с базовым рейтингом 1600
- WinProbability = 1 / (10 ^ ((Текущий рейтинг оппонента - Текущий рейтинг игрока) / 400) + 1)
- ScoringPt = 1 очко, если они выигрывают матч, 0, если они проигрывают, и 0,5 за ничью.
- Новый рейтинг игрока = старый рейтинг игрока + (значение K * (ScoringPt - вероятность выигрыша игрока))
Замените "игроков" на картинки, и у вас есть простой способ настроить рейтинг обеих картинок на основе формулы. Затем вы можете выполнить ранжирование, используя эти числовые оценки. (K-Value здесь - это "уровень" турнира. Это 8-16 для небольших локальных турниров и 24-32 для более крупных приглашений / регионалов. Вы можете просто использовать константу, например, 20).
При использовании этого метода вам нужно сохранить только один номер для каждого изображения, который требует значительно меньше памяти, чем сохранение отдельных рангов каждого изображения для каждого другого изображения.
РЕДАКТИРОВАТЬ: Добавлено немного больше мяса на основе комментариев.
У большинства наивных подходов к проблеме есть серьезные проблемы. Хуже всего то, как bash.org и qdb.us отображают котировки - пользователи могут голосовать за котировки вверх (+1) или вниз (-1), а список лучших котировок сортируется по общему количеству баллов. Это страдает от ужасного временного смещения - старые цитаты набрали огромное количество положительных голосов за счет простого долголетия, даже если они лишь незначительно смешны. Этот алгоритм может иметь смысл, если шутки становятся смешнее, когда они становятся старше, но, поверьте мне, они этого не делают.
Существуют различные попытки исправить это - посмотреть на количество положительных голосов за определенный период времени, взвесить более свежие голоса, внедрить систему распада для более старых голосов, рассчитать соотношение положительных и отрицательных голосов и т. Д. Большинство страдают от других недостатков.
На мой взгляд, лучшее решение - это то, что используют веб-сайты The Funniest The Cutest, The Fairest и Best Thing - модифицированная система голосования Condorcet:
Система присваивает каждому номер, исходя из того, с чем он сталкивался, какой процент из них он обычно бьет. Таким образом, каждый получает процентный балл NumberOfThingsIBeat / (NumberOfThingsIBeat + NumberOfThingsThatBeatMe). Кроме того, вещи запрещены в верхнем списке, пока они не были сравнены с разумным процентом набора.
Если в наборе есть победитель Кондорсе, этот метод найдет его. Поскольку это маловероятно, учитывая статистическую природу, он находит тот, который "наиболее близок" к тому, чтобы стать победителем Кондорсе.
Для получения дополнительной информации о внедрении таких систем должна быть полезна страница Википедии по ранжированным парам.
Алгоритм требует, чтобы люди сравнивали два объекта (ваш выбор Pick-A-or-B), но, честно говоря, это хорошо. Я считаю, что в теории принятия решений очень хорошо принято, что люди гораздо лучше сравнивают два объекта, чем в абстрактном рейтинге. Миллионы лет эволюции делают нас хорошими в выборе лучшего яблока с дерева, но ужасны в принятии решения, насколько близко мы собрали яблоко, к истинной платонической форме яблочности. (Это, кстати, то, почему Процесс Аналитической Иерархии такой изящный... но это становится немного не по теме.)
И последнее замечание: SO использует алгоритм для поиска лучших ответов, который очень похож на алгоритм http://bash.org/ для поиска лучших предложений. Это хорошо работает здесь, но ужасно терпит неудачу там - в значительной степени потому, что старый, высоко оцененный, но теперь устаревший ответ здесь, вероятно, будет отредактирован. bash.org не позволяет редактировать, и неясно, как вы вообще отредактируете десятилетние анекдоты об устаревших интернет-мемах, даже если бы вы могли... В любом случае, я считаю, что правильный алгоритм обычно зависит от деталей вашей проблемы.:-)
Я знаю, что этот вопрос довольно старый, но я решил внести свой вклад
Я бы посмотрел на систему TrueSkill, разработанную в Microsoft Research. Это похоже на ELO, но имеет гораздо более быстрое время сходимости (выглядит экспоненциально по сравнению с линейным), поэтому вы получаете больше от каждого голоса. Это, однако, более сложно математически.
Мне не нравится стиль Hot-or-Not. Разные люди выбирают разные цифры, даже если им все одинаково нравится изображение. Также я ненавижу оценивать вещи из 10, я никогда не знаю, какое число выбрать.
Выбрать А-или-Б намного проще и веселее. Вы видите два изображения, и сравниваются изображения на сайте.
Эти уравнения из Википедии упрощают / делают более эффективным вычисление оценок Эло, алгоритм для изображений A и B будет простым:
- Получить Ne, мА, мБ и рейтинги RA,RB из вашей базы данных.
- Рассчитайте KA,KB, QA, QB, используя количество выполненных сравнений (Ne) и количество сравнений изображения (м) и текущие оценки:


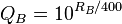
- Рассчитать EA и EB.


- Оценка S победителя: победитель 1, проигравший 0, а если у вас ничья 0,5,
Рассчитайте новые рейтинги для обоих, используя:
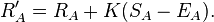
Обновите новые рейтинги RA,RB и отсчеты мА, мБ в базе данных.
Рейтинг 1-10 не сработает, у всех разные уровни. Кто-то, кто всегда дает 3-7 оценок, затмевает свой рейтинг людьми, которые всегда дают 1 или 10.
а-или-б более работоспособен.
Вы можете пойти с комбинацией.
Первый этап: стиль "горячий" или "нет" (хотя я бы выбрал вариант с 3 вариантами голосования: отстой, Мех / ОК. Круто!)
После того, как вы отсортировали набор в 3 сегмента, я бы выбрал два изображения из одного блока и выбрал "Что лучше"
Затем вы могли бы использовать систему продвижения и понижения английского футбола, чтобы переместить несколько лучших "Отстой" в регион Meh/OK, чтобы уточнить крайние случаи.
Вау, я опаздываю в игре.
Мне очень нравится система ELO, но, как говорит Оуэн, мне кажется, что вы не спешите получать какие-либо существенные результаты.
Я считаю, что у людей гораздо больше возможностей, чем просто сравнивать два изображения, но вы хотите, чтобы взаимодействие было минимальным.
Итак, как насчет того, чтобы показать n изображений (n - это любое число, которое вы можете визуально отобразить на экране, это может быть 10, 20, 30, в зависимости от предпочтений пользователя, может быть) и заставить их выбрать то, что, по их мнению, лучше всего в этой партии. Теперь вернемся к ЭЛО. Вам нужно изменить свою рейтинговую систему, но придерживаться того же духа. Вы фактически сравнили одно изображение с n-1 другими. Таким образом, вы делаете свой рейтинг ELO n-1 раз, но вы должны разделить изменение рейтинга на n-1, чтобы соответствовать (чтобы результаты с различными значениями n были согласованы друг с другом).
Вы сделали Теперь у вас есть лучшее из всех миров. Простая рейтинговая система, работающая со многими изображениями в один клик.
Если вы предпочитаете использовать стратегию Pick A или B, я бы порекомендовал этот документ: http://research.microsoft.com/en-us/um/people/horvitz/crowd_pairwise.pdf
Chen, X., Bennett, PN, Collins-Thompson, K. & Horvitz, E. (2013, февраль). Парное ранжирование агрегации в краудсорсинге. В материалах шестой международной конференции ACM по веб-поиску и интеллектуальному анализу данных (стр. 193-202). ACM.
В статье рассказывается о модели Crowd-BT, которая расширяет известную модель парного сравнения Брэдли-Терри в условиях краудсорсинга. Это также дает адаптивный алгоритм обучения для повышения эффективности модели во времени и пространстве. Вы можете найти реализацию алгоритма в Matlab на Github (но я не уверен, работает ли он).
На несуществующем веб-сайте whatsbetter.com использовался метод стиля Эло. Вы можете прочитать о методе в их FAQ в интернет-архиве.
Мне нравится опция быстрой сортировки, но я бы сделал несколько твиков:
- Сохраните результаты "сравнения" в БД, а затем усредните их.
- Получите более одного сравнения для каждого просмотра, предоставив пользователю 4-6 изображений и попросив их отсортировать их.
- Выберите, какие изображения отображать, запустив qsort, записав и обрезав все, что вам не хватает данных. Затем, когда у вас будет достаточно записей, выкладывайте страницу.
Другой забавный вариант - использовать толпу для обучения нейронной сети.
Выберите A-or-B - это самый простой и менее подверженный предвзятости, однако при каждом взаимодействии с человеком он дает вам значительно меньше информации. Я думаю, что из-за уменьшения предвзятости, Пик превосходит и в пределе он предоставляет вам ту же информацию.
Очень простая схема подсчета очков состоит в том, чтобы иметь счет для каждого изображения. Когда кто-то дает положительное сравнение, увеличивайте счет, когда кто-то дает отрицательное сравнение, уменьшайте счет.
Сортировка списка из 1 миллиона целочисленных значений выполняется очень быстро и занимает меньше секунды на современном компьютере.
Тем не менее, проблема довольно некорректна - вам понадобится 50 дней, чтобы показать каждое изображение только один раз.
Бьюсь об заклад, хотя вы больше заинтересованы в изображениях с самым высоким рейтингом? Таким образом, вы, вероятно, хотите сместить поиск изображений по прогнозируемому рейтингу - так что вы с большей вероятностью покажете изображения, которые уже достигли нескольких положительных сравнений. Таким образом, вы быстрее начнете показывать "интересные" изображения.