Добавление среднего значения для geom_density_ridges
Я пытаюсь добавить средства, используя geom_segment к geom_density_ridges Сюжет сделан в ggplot2.
library(dplyr)
library(ggplot2)
library(ggridges)
Fig1 <- ggplot(Figure3Data, aes(x = `hairchange`, y = `EffortGroup`)) +
geom_density_ridges_gradient(aes(fill = ..x..), scale = 0.9, size = 1)
ingredients <- ggplot_build(Fig1) %>% purrr::pluck("data", 1)
density_lines <- ingredients %>%
group_by(group) %>% filter(density == mean(density)) %>% ungroup()
p <- ggplot(Figure3Data, aes(x = `hairchange`, y = `EffortGroup`)) +
geom_density_ridges_gradient(aes(fill = ..x..), scale = 0.9, size = 1) +
scale_fill_gradientn( colours = c("#0000FF", "#FFFFFF", "#FF0000"),name =
NULL, limits=c(-2,2))+ coord_flip() +
theme_ridges(font_size = 20, grid=TRUE, line_size=1,
center_axis_labels=TRUE) +
scale_x_continuous(name='Average Self-Perceived Hair Change', limits=c(-2,2))+
ylab('Total SSM Effort (hours)')+
geom_segment(data =density_lines,
aes(x = x, y = ymin, xend = x, yend = ymin+density*scale*iscale))
print(p)
Тем не менее, я получаю сообщение об ошибке: data должен иметь уникальное имя, но иметь повторяющиеся элементы ". Ниже приведен график без средств для набора данных, который у меня есть. Есть предложения о том, как исправить код?

Первые 35 строк данных находятся ниже:
structure(list(MonthsMassage = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2,
2, 2, 1, 1), MinutesPerDayMassage = c("0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "11-20 minutes daily",
"11-20 minutes daily", "11-20 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "11-20 minutes daily", "11-20 minutes daily"
), Minutes = c(5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 15, 15, 15, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 15, 15),
hairchange = c(-1, -1, 0, -1, 0, -1, -1, 0, 0, -1, 0, -1,
-1, 0, 0, -1, 0, -1, 0, -1, -1, -1, -1, -1, 0, -1, -1, -1,
0, 1, -1, 0, 0, -1, 0), HairType1 = c("Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "Templefrontal",
"Templefrontal", "other", "Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "other",
"other", "other", "Templefrontal", "Templefrontal", "other",
"Templefrontal", "other", "Templefrontal", "Templefrontal"
), HairType2 = c("other", "other", "other", "other", "other",
"other", "other", "other", "other", "Vertexthinning", "Vertexthinning",
"other", "Vertexthinning", "other", "other", "Vertexthinning",
"other", "Vertexthinning", "Vertexthinning", "other", "other",
"other", "Vertexthinning", "other", "Vertexthinning", "other",
"other", "other", "other", "other", "other", "Vertexthinning",
"other", "other", "other"), HairType3 = c("other", "Diffusethinning",
"other", "Diffusethinning", "other", "other", "Diffusethinning",
"Diffusethinning", "Diffusethinning", "other", "Diffusethinning",
"Diffusethinning", "other", "other", "Diffusethinning", "Diffusethinning",
"other", "Diffusethinning", "Diffusethinning", "Diffusethinning",
"other", "other", "other", "other", "other", "other", "other",
"other", "other", "Diffusethinning", "other", "other", "other",
"other", "other"), Effort = c(0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5,
2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 5, 5, 5, 5, 5, 7.5, 7.5), EffortGroup = c("<5",
"<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5",
"<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5",
"<5", "<5", "<5", "<5", "<5", "<5", "<5", "12.5", "12.5",
"12.5", "12.5", "12.5", "12.5", "12.5")), row.names = c(NA,
-35L), class = c("tbl_df", "tbl", "data.frame"))
1 ответ
Построение горизонтальных линий
Если я правильно понимаю, ОП хочет построить горизонтальную линию в положении, где плотность равна средней плотности для каждой из линий гребня.
Выражение
density_lines <- ingredients %>%
group_by(group) %>% filter(density == mean(density)) %>% ungroup()
возвращает пустой набор данных, так как нет записи, где density значение точно соответствует mean(density),
Однако он работает для общего максимума (но не для всех локальных максимумов)
density_lines <- ingredients %>%
group_by(group) %>% filter(density == max(density)) %>% ungroup()
который дает
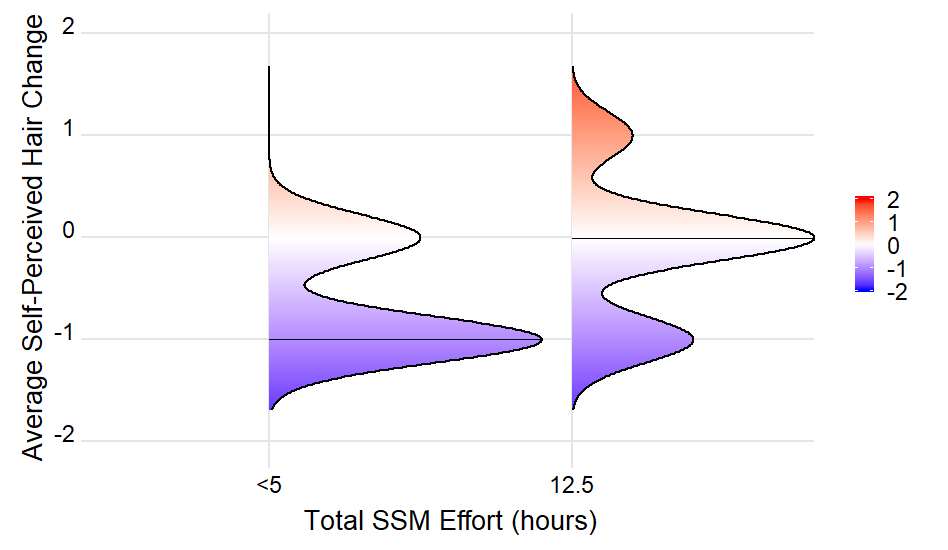
Найти ближайшее значение
Поскольку нет точного совпадения, самое близкое значение может быть выбрано
density_lines <- ingredients %>%
group_by(group) %>%
top_n(1, -abs(density - mean(density)))
какие участки как
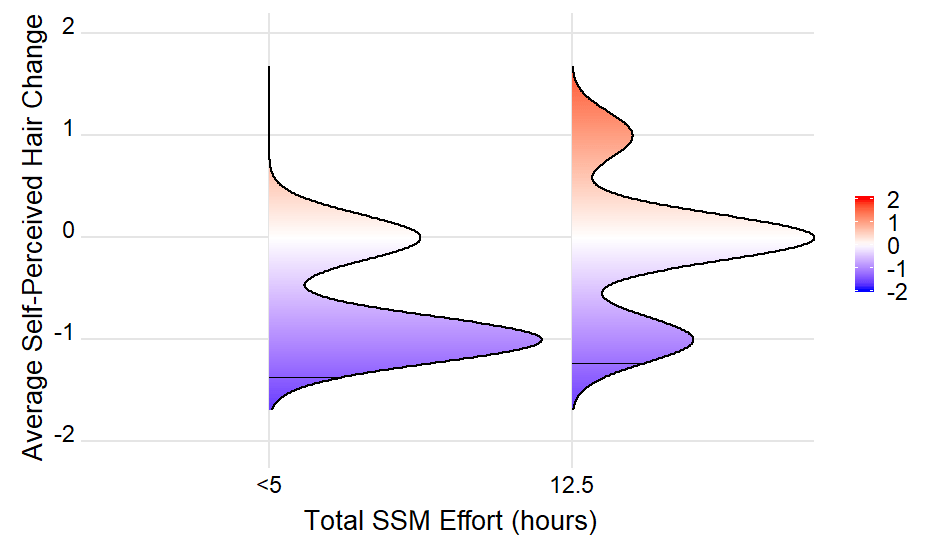
Это строит один сегмент на линии гребня, но мы ожидаем увидеть 4 сегмента в каждой из ветвей кривой (те, где максимум соседнего пика больше среднего). С
density_lines <- ingredients %>%
group_by(group) %>%
top_n(4, -abs(density - mean(density)))
мы получаем
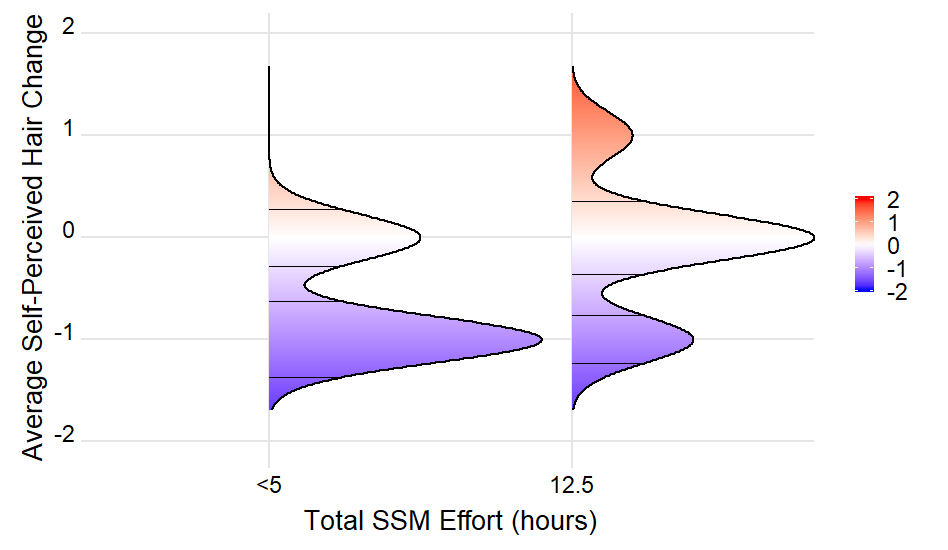
Вы можете поиграть с n параметр для top_n() но ИМХО правильным способом было бы сгруппировать каждую грядовую линию от вершины до долины и от долины до вершины, чтобы получить один сегмент для каждой ветви кривой.
Найти значение поблизости
Кроме того, мы можем отфильтровать, используя near() функция. Эта функция требует указать допуск tol который мы должны вычислить из набора данных:
density_lines <- ingredients %>%
group_by(group) %>%
filter(near(
density, mean(density),
tol = ingredients %>% summarise(0.25 * max(abs(diff(density)))) %>% pull()
))
Для тщательно подобранного фактора 0.25 (попробуйте и ошибка) мы получаем
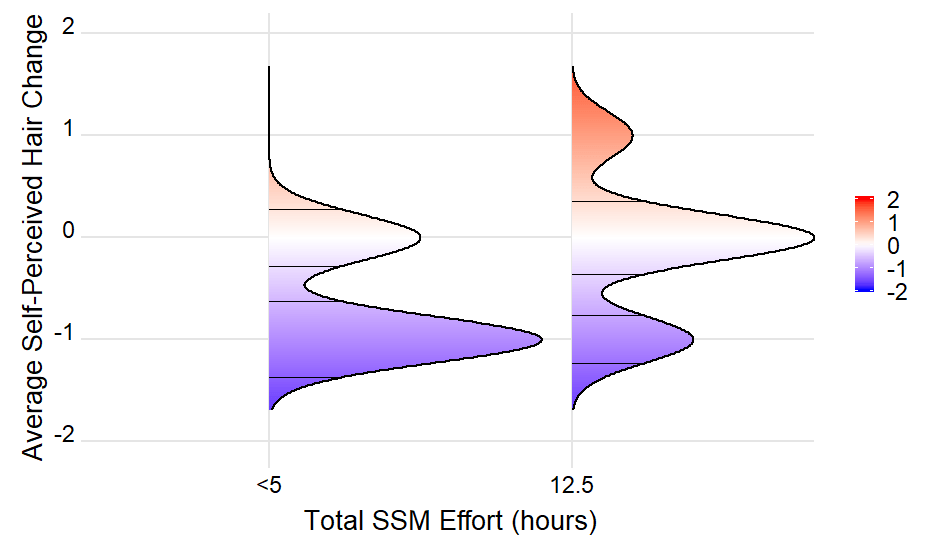
РЕДАКТИРОВАТЬ: построение вертикальных линий
Кажется, я неправильно истолковал намерения ОП. Теперь мы попробуем построить вертикальную линию в mean(density) с помощью geom_hline (с coord_flip(), geom_hline() создает вертикальную линию).
Опять же, мы следуем умному подходу OP для извлечения плотностей и масштабных коэффициентов из созданного графика.
# create plot object
Fig1 <- ggplot(Figure3Data, aes(x = hairchange, y = EffortGroup)) +
geom_density_ridges_gradient(aes(fill = ..x..), scale = 0.9, size = 1) +
scale_fill_gradientn(
colours = c("#0000FF", "#FFFFFF", "#FF0000"),
name =
NULL,
limits = c(-2, 2)
) + coord_flip() +
theme_ridges(
font_size = 20,
grid = TRUE,
line_size = 1,
center_axis_labels = TRUE
) +
scale_x_continuous(name = 'Average Self-Perceived Hair Change', limits =
c(-2, 2)) +
ylab('Total SSM Effort (hours)')
# extract plot data and summarise
mean_density <-
ggplot_build(Fig1) %>%
purrr::pluck("data", 1) %>%
group_by(group) %>%
summarise(density = mean(density), scale = first(scale), iscale = first(iscale))
# add hline and plot
Fig1 +
geom_hline(aes(yintercept = group + density * scale * iscale),
data = mean_density)
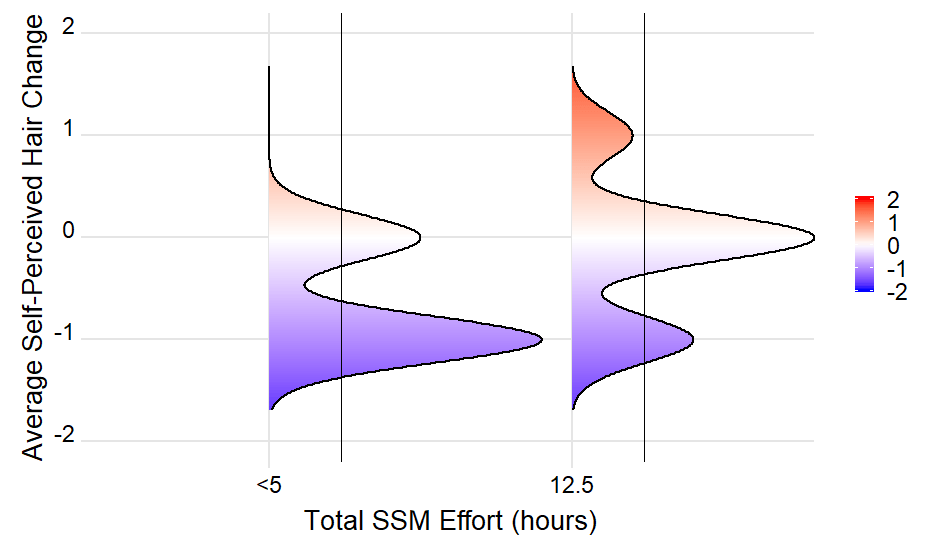
РЕДАКТИРОВАТЬ 2: Нарисуйте горизонтальные линии в положении среднего восприятия изменения волос
ФП уточнил, что
Я хочу, чтобы среднее значение восприятия волос менялось (данные оси Y) для каждой из 10 линий ребер.
Это может быть достигнуто в следующие шаги:
- Создать объект риджплота.
- Вычислите среднее воспринимаемое изменение волос для каждого
EffortGroup, - Выберите значения созданных значений плотности из данных графика.
- Присоединитесь к обоим наборам данных.
- Вычислить значения плотности в местах расположения средств, используя
approx() - Нарисуйте отрезки линии.
Среднее самоочевидное изменение волос для каждого EffortGroup вычисляется
Figure3Data %>%
group_by(EffortGroup) %>%
summarise(x_mean = mean(hairchange))
который дает (для размещенного подмножества данных ОП):
EffortGroup x_mean <chr> <dbl> 1 <5 -0.643 2 12.5 -0.143
Все шаги вместе:
# create plot object
Fig1 <- ggplot(Figure3Data, aes(x = hairchange, y = EffortGroup)) +
geom_density_ridges_gradient(aes(fill = ..x..), scale = 0.9, size = 1) +
scale_fill_gradientn(
colours = c("#0000FF", "#FFFFFF", "#FF0000"),
name = NULL,
limits = c(-2, 2)) +
coord_flip() +
theme_ridges(
font_size = 20,
grid = TRUE,
line_size = 1,
center_axis_labels = TRUE) +
scale_x_continuous(name = 'Average Self-Perceived Hair Change',
limits = c(-2, 2)) +
ylab('Total SSM Effort (hours)')
density_lines <-
Figure3Data %>%
group_by(EffortGroup) %>%
summarise(x_mean = mean(hairchange)) %>%
mutate(group = as.integer(factor(EffortGroup))) %>%
left_join(ggplot_build(Fig1) %>% purrr::pluck("data", 1),
on = "group") %>%
group_by(group) %>%
summarise(x_mean = first(x_mean),
density = approx(x, density, first(x_mean))$y,
scale = first(scale),
iscale = first(iscale))
# add segments and plot
Fig1 +
geom_segment(aes(x = x_mean,
y = group,
xend = x_mean,
yend = group + density * scale * iscale),
data = density_lines)
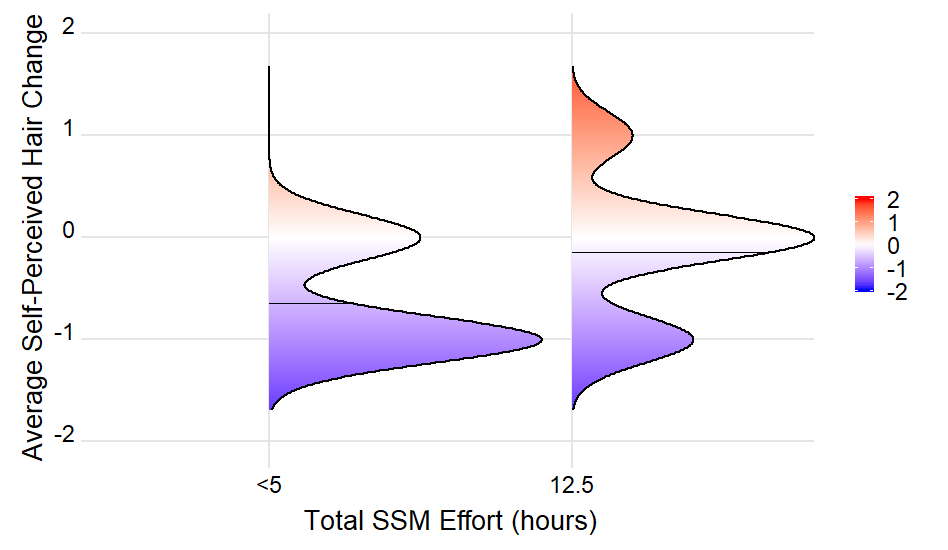
РЕДАКТИРОВАТЬ 3: Изменить порядок горизонтальной оси
ОП попросил изменить порядок горизонтальной оси соответствующим образом. Это может быть сделано путем принуждения EffortGroup от типа character в factor заранее, где уровни факторов явно указаны в ожидаемом порядке:
# turn EffortGroup into factor with levels in desired order
lvls <- c("<5", "12.5", "22.5", "35", "50", "75", "105", "152", "210", "210+")
Figure3Data <-
Figure3Data %>%
mutate(EffortGroup = factor(EffortGroup, levels = lvls))
С другой стороны, EffortGroup могут быть получены непосредственно из данного Effort значения по
# create Effort Group from scratch
lvls <- c("<5", "12.5", "22.5", "35", "50", "75", "105", "152", "210", "210+")
brks <- c(-Inf, 5, 12.5, 22.5, 35, 50, 75, 105, 152, 210, Inf)
Figure3Data <-
Figure3Data %>%
mutate(EffortGroup = cut(Effort, brks, lvls, right = FALSE))
В любом случае вычисление density_lines должен быть изменен как EffortGroup это уже фактор:
density_lines <-
Figure3Data %>%
group_by(EffortGroup) %>%
summarise(x_mean = mean(hairchange)) %>%
mutate(group = as.integer(EffortGroup)) %>% # remove call to factor() here
left_join( ...
С полным набором данных, предоставленным OP (ссылка), график, наконец, становится
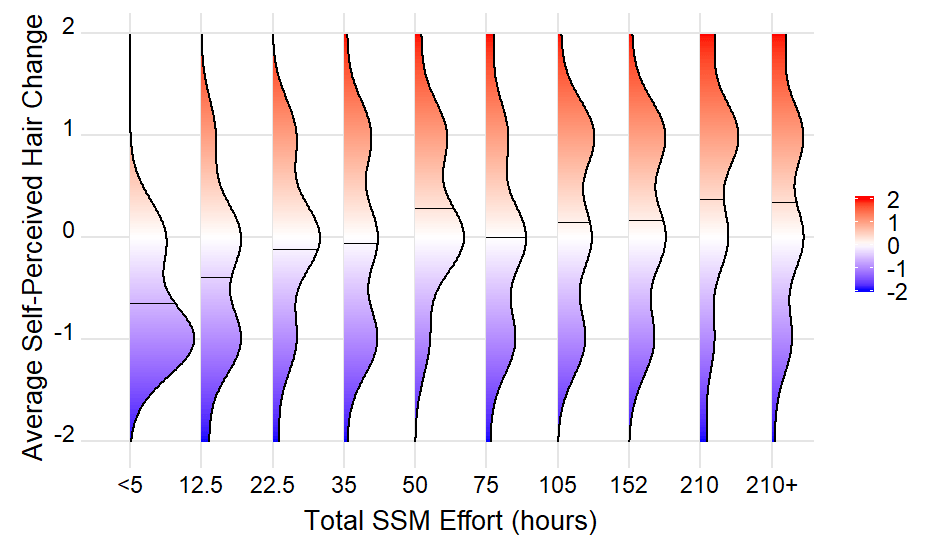
Места, в которых средние ощущаемые волосы меняются для каждого EffortGroup даны
Figure3Data %>%
group_by(EffortGroup) %>%
summarise(x_mean = mean(hairchange))
# A tibble: 10 x 2 EffortGroup x_mean <fct> <dbl> 1 <5 -0.643 2 12.5 -0.393 3 22.5 -0.118 4 35 -0.0606 5 50 0.286 6 75 0 7 105 0.152 8 152 0.167 9 210 0.379 10 210+ 0.343