Какие существуют методы / алгоритм приложения / состояния игры "дельта-сжатие"?
Я заинтересован в изучении многопользовательских игр в режиме реального времени с разработкой клиент-серверных игр и соответствующих алгоритмов Многие известные многопользовательские игры, такие как Quake 3 или Half-Life 2, используют методы дельта-сжатия для экономии пропускной способности.
Сервер должен постоянно посылать последний снимок состояния игры всем клиентам. Было бы очень дорого всегда отправлять полный снимок, поэтому сервер просто отправляет различия между последним снимком и текущим.
... легко, правда? Ну, часть, о которой мне очень трудно подумать, - это как на самом деле рассчитать разницу между двумя состояниями игры.
Состояния игры могут быть очень сложными и иметь объекты, размещенные в куче, ссылаясь друг на друга через указатели, могут иметь числовые значения, представление которых варьируется от архитектуры к другой, и многое другое.
Мне трудно поверить, что каждый тип игрового объекта имеет рукописную функцию сериализации / десериализации / вычисления различий.
Давайте вернемся к основам. Допустим, у меня есть два состояния, представленные битами, и я хочу вычислить их разницу:
state0: 00001000100 // state at time=0
state1: 10000000101 // state at time=1
-----------
added: 10000000001 // bits that were 0 in state0 and are 1 in state1
removed: 00001000000 // bits that were 1 in state0 and are 1 in state1
Отлично, теперь у меня есть added а также removed наборы различий - но...
... размер различий остается точно таким же, как и размер состояния. И мне действительно нужно отправить два различий по сети!
Действительная стратегия действительно строит какую-то разреженную структуру данных из этих наборов различий? Пример:
// (bit index, added/removed)
// added = 0
// removed 1
(0,0)(4,1)(10,0)
// ^
// bit 0 was added, bit 4 was removed, bit 10 was added
Это возможный действительный подход?
Допустим, мне удалось написать функции сериализации / десериализации для всех типов игровых объектов от / до JSON.
Могу ли я как-то, имея два значения JSON, автоматически вычислить разницу между ними в терминах битов?
Пример:
// state0
{
"hp": 10,
"atk": 5
}
// state1
{
"hp": 4,
"atk": 5
}
// diff
{
"hp": -6
}
// state0 as bits (example, random bits)
010001000110001
// state1 as bits (example, random bits)
000001011110000
// desired diff bits (example, random bits)
100101
Если бы что-то подобное было возможно, то было бы достаточно легко избежать архитектурно-зависимых проблем и функций вычисления различий в почерке.
Если две строки A и B похожи друг на друга, возможно ли рассчитать строку C, которая меньше по размеру, чем A и B, которая представляет разницу между A и B и которая может быть применена к A для получения B в результате?
3 ответа
Поскольку вы использовали Quake3 в качестве примера, я сосредоточусь на том, как там все делается. Первое, что вам нужно понять, это то, что "игровое состояние" по отношению к играм клиент-сервер не относится ко всему внутреннему состоянию объекта, включая текущее состояние ИИ, функции столкновения, таймеры и т. Д. Сервер игры на самом деле дает клиенту намного меньше. Только положение объектов, ориентация, модель, кадр в анимации модели, скорость и физический тип. Последние два используются, чтобы сделать движение более плавным, позволяя клиенту имитировать баллистическое движение, но это все.
Каждый игровой кадр, который происходит примерно 10 раз в секунду, сервер запускает физику, логику и таймеры для всех объектов в игре. Каждый объект затем вызывает функцию API, чтобы обновить свою новую позицию, фрейм и т. Д., А также обновить, был ли он добавлен или удален в этом фрейме (например, удаляемый выстрел, потому что он попал в стену). На самом деле, в Quake 3 есть интересная ошибка в этом отношении - если выстрел перемещается во время фазы физики и попадает в стену, он удаляется, и удаляется только то обновление, которое получает клиент, а не предыдущий полет к стене, таким образом, клиент видит, как выстрел исчезает в воздухе за 1/10 секунды, прежде чем он действительно ударит в стену.
С этой небольшой информацией для каждого объекта довольно легко отличить новую информацию от старой информации. Кроме того, только объекты, которые действительно изменяются, вызывают API обновления, поэтому объектам, которые остаются неизменными (например, стены или неактивные платформы), даже не нужно выполнять такую разность. Кроме того, сервер может дополнительно сэкономить на отправленной информации, не отправляя клиенту объекты, которые не видны клиенту, пока они не появятся в поле зрения. Например, в Quake2 уровень делится на области просмотра, и одна область (и все объекты внутри нее) считается "вне поля зрения" от другой, если все двери между ними закрыты.
Помните, что серверу не нужно, чтобы у клиента было полное игровое состояние, только граф сцены, а для этого требуется гораздо более простая сериализация и абсолютно никаких указателей (в Quake он фактически содержится в одном массиве статического размера, который также ограничивает максимальное количество объектов в игре).
Кроме того, есть также данные пользовательского интерфейса для таких вещей, как здоровье игрока, боеприпасы и т. Д. Опять же, каждому игроку отправляется только его собственное здоровье и боеприпасы, а не все на сервере. У сервера нет причин для обмена этими данными.
Обновление: чтобы убедиться, что я получаю наиболее точную информацию, я дважды проверил код. Это основано на Quake3, а не на Quake Live, поэтому некоторые вещи могут отличаться. Информация, отправляемая клиенту, по существу заключена в единую структуру, называемую snapshot_t, Это содержит один playerState_t для текущего игрока, и массив 256 entityState_t для видимых игровых объектов, а также нескольких дополнительных целых чисел и байтового массива, представляющего битовую маску "видимых областей".
entityState_t В свою очередь, состоит из 22 целых чисел, 4 векторов и 2 траекторий. "Траектория" - это структура данных, используемая для представления движения объекта в пространстве, когда с ним ничего не происходит, например, баллистическое движение или полет по прямой. Это 2 целых числа, 2 вектора и одно перечисление, которые могут быть концептуально сохранены как небольшое целое число.
playerState_t немного больше, содержит примерно 34 целых числа, примерно 8 целочисленных массивов размеров от 2 до 16 каждый и 4 вектора. Он содержит все, начиная с текущего кадра анимации оружия, через инвентарь игрока и заканчивая звуком, который издает игрок.
Поскольку используемые структуры имеют заданные размеры и, ну, в общем, структуру, сделать простую ручную функцию "diff", сравнивая каждый из членов, для каждого довольно просто. Однако, насколько я могу судить, entityState_t а также playerState_t отправляются только целиком, а не частями. Единственное, что называется "delta", это то, какие сущности отправляются как часть массива сущностей в snapshot_t,
Хотя снимок может содержать до 256 объектов, сама игра может содержать до 1024 объектов. Это означает, что только 25% объектов могут быть обновлены, с точки зрения клиента, в одном кадре (если это приведет к печально известной ошибке "переполнение пакета"). Сервер просто отслеживает, какие объекты имели значимое движение, и отправляет их. Это намного быстрее, чем выполнение реального сравнения - просто отправка любого объекта, который называется "update", и находится внутри битовой маски видимой области игрока. Но в теории, рукописный дифференциал для каждой структуры будет не намного сложнее сделать.
Что касается здоровья команды, тогда как Quake3, похоже, этого не делает, поэтому я могу только предполагать, как это делается в Quake Live. Есть два варианта: либо отправить все playerState_t структуры, так как их максимум 64, или добавьте другой массив в playerState_t для сохранения команды HP, так как это будет только 64 целых чисел. Последнее намного вероятнее.
Чтобы синхронизировать массив объектов между клиентом и сервером, каждый объект имеет индекс объекта от 0 до 1023, и он отправляется как часть сообщения с сервера клиенту. Когда клиент получает массив из 256 объектов, он проходит через массив, считывает поле индекса из каждого и обновляет объект по индексу чтения в своем локально сохраненном массиве объектов.
Я бы предложил сделать шаг назад и оглянуться вокруг, чтобы найти потенциально лучшее решение.
Как вы уже упоминали, игровое состояние может быть действительно очень сложным и огромным. Так что вряд ли умное сжатие (разности, компактные сериализованные формы и т. Д.) Поможет. В конце концов, возникнет необходимость в переносе действительно больших различий, поэтому игровой опыт пострадает.
Вкратце, я бы предложил рассмотреть две цифры (будет предоставлена ссылка на источник).
Вы можете перевести действие пользователя в вызов функции, который изменит состояние игры:
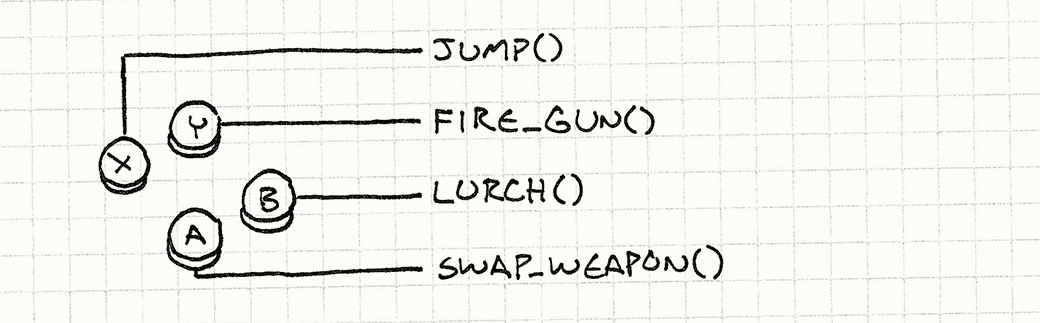
Или вы можете создать соответствующую команду / действие и позволить вашему исполнителю команды обрабатывать его, изменяя состояние асинхронно:
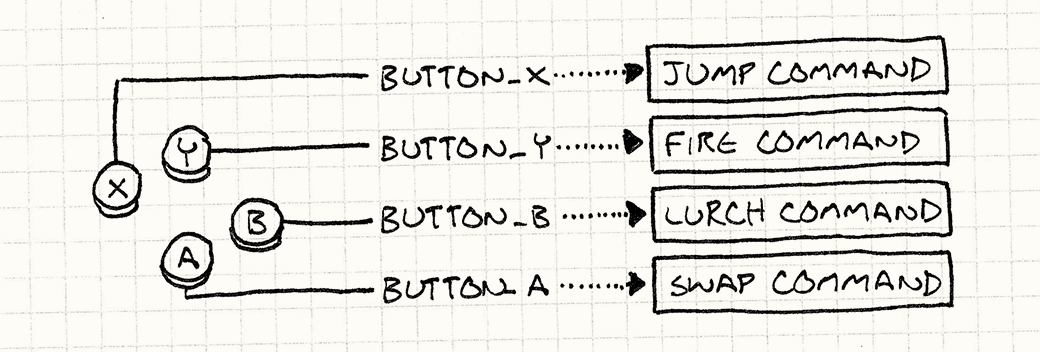
Может показаться, что разница довольно мала, но второй подход позволяет вам:
- чтобы избежать какого-либо состояния гонки и безопасно обновить состояние, введя очередь для действий пользователя
- обрабатывать действия из нескольких источников (вам просто нужно правильно их отсортировать)
Я только что описал шаблон команд, который может быть очень полезным. Это подводит нас к идее computed state, Если поведение команд является детерминированным (как и должно быть), чтобы получить новое состояние, вам просто нужны предыдущая и команда.
Таким образом, имея начальное состояние (одинаковое для каждого игрока или перенесенное в самом начале игры), для увеличения состояния потребуются только другие команды.
Я буду использовать запись с опережением и ведение журнала команд в качестве примера (давайте представим, что ваше состояние игры находится в базе данных), потому что в значительной степени решается та же проблема, и я уже пытался дать подробное объяснение:
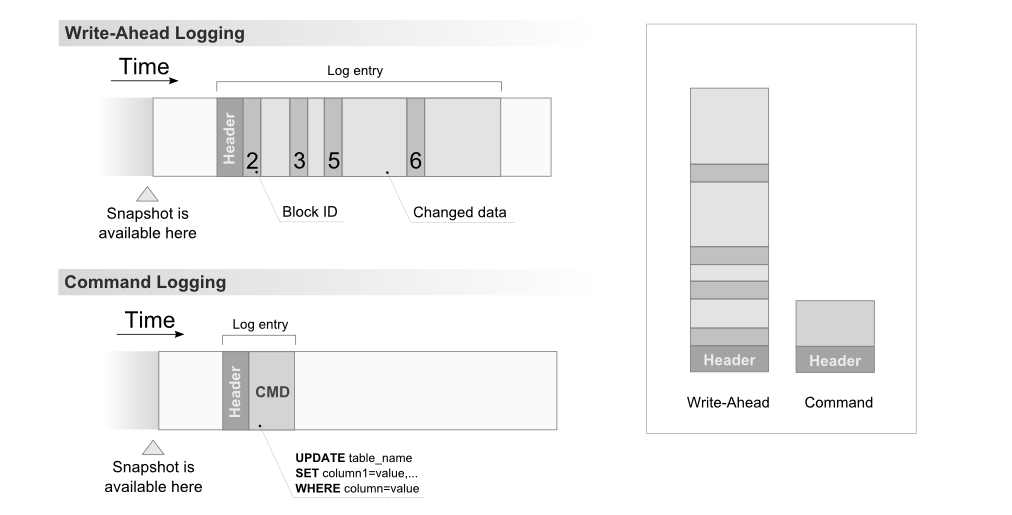
Такой подход также позволяет упростить восстановление состояния и т. Д., Поскольку выполнение действия может быть действительно более быстрым по сравнению с generate new state, compare to the previous one, generate diff, compress diff, send diff, apply diff последовательность.
В любом случае, если вы все еще думаете, что лучше отправлять diff, просто постарайтесь, чтобы ваше состояние было достаточно маленьким (потому что у вас будет как минимум два снимка) с небольшим и легко читаемым объемом памяти.
В этом случае процедура diff будет генерировать разреженные данные, поэтому любой алгоритм сжатия потока легко даст хороший коэффициент сжатия. Кстати, убедитесь, что ваш алгоритм сжатия не потребует еще больше памяти. Лучше не использовать какое-либо словарное решение.
Арифметическое кодирование, дерево Radix, скорее всего, поможет. Вот и идея и реализация, с которой вы можете начать:
public static void encode(int[] buffer, int length, BinaryOut output) {
short size = (short)(length & 0x7FFF);
output.write(size);
output.write(buffer[0]);
for(int i=1; i< size; i++) {
int next = buffer[i] - buffer[i-1];
int bits = getBinarySize(next);
int len = bits;
if(bits > 24) {
output.write(3, 2);
len = bits - 24;
}else if(bits > 16) {
output.write(2, 2);
len = bits-16;
}else if(bits > 8) {
output.write(1, 2);
len = bits - 8;
}else{
output.write(0, 2);
}
if (len > 0) {
if ((len % 2) > 0) {
len = len / 2;
output.write(len, 2);
output.write(false);
} else {
len = len / 2 - 1;
output.write(len, 2);
}
output.write(next, bits);
}
}
}
public static short decode(BinaryIn input, int[] buffer, int offset) {
short length = input.readShort();
int value = input.readInt();
buffer[offset] = value;
for (int i = 1; i < length; i++) {
int flag = input.readInt(2);
int bits;
int next = 0;
switch (flag) {
case 0:
bits = 2 * input.readInt(2) + 2;
next = input.readInt(bits);
break;
case 1:
bits = 8 + 2 * input.readInt(2) +2;
next = input.readInt(bits);
break;
case 2:
bits = 16 + 2 * input.readInt(2) +2;
next = input.readInt(bits);
break;
case 3:
bits = 24 + 2 * input.readInt(2) +2;
next = input.readInt(bits);
break;
}
buffer[offset + i] = buffer[offset + i - 1] + next;
}
return length;
}
Последнее слово: не выставляйте состояние, не передавайте его, вместо этого вычисляйте. Такой подход будет быстрее, проще в реализации и отладке.
При сравнении битов эффективность хранения местоположения каждого измененного бита зависит от того, сколько битов изменено. В 32-битной системе каждое местоположение занимает 32 бита, поэтому оно эффективно только при изменении менее 1 на 32 бита. Однако, поскольку измененные биты обычно являются смежными, было бы более эффективно, если бы вы сравнивали в больших единицах (например, байтах или словах).
Обратите внимание, что ваш подход к сравнению битов работает только в том случае, если абсолютные местоположения бит не меняются. Однако, если некоторые биты будут вставлены или удалены в середине, ваш алгоритм будет видеть почти каждый бит после вставленной / удаленной позиции как измененный. Чтобы смягчить это, вы должны вычислить самую длинную общую подпоследовательность, поэтому биты только в A или B являются теми, которые вставлены / удалены.
Но сравнение объектов JSON не должно происходить побитно. (Если необходимо, это то же самое, что сравнивать две битовые строки.) Сравнение может происходить на более высоком уровне. Одним из способов вычисления разницы двух абрирированных объектов JSON было бы написание функции, которая принимает A и B и:
- Если аргументы имеют разные типы, верните "A изменяется на B".
- Если аргументы имеют один и тот же примитивный тип, ничего не возвращать, если они одинаковы, в противном случае вернуть "A изменено на B".
- Если оба аргумента являются словарями, то элементы, ключи которых находятся только в A, удаляются, а ключи, которые находятся только в B, добавляются. Для элементов с одинаковым ключом сравнивайте рекурсивно.
- Если оба аргумента являются массивами, вычислите самую длинную общую подпоследовательность A и B(равны ли два элемента, можно также проверить с помощью рекурсивной функции), и найдите элементы только в A или B. Таким образом, элементы только в A являются теми, которые удалены добавлены только элементы в B. Или, может быть, элементы, которые не равны, также можно сравнивать рекурсивно, но единственный эффективный способ, который я могу придумать, требует наличия способа (такого как идентификаторы записи), чтобы определить, какой элемент в A соответствует какому элементу в B, и сравнить элемент с соответствующим элементом.
Разница между двумя строками также может быть вычислена с использованием самой длинной общей подпоследовательности.