Wget/ Curl большой файл с Google Drive
Я пытаюсь загрузить файл с Google Drive в сценарии, и у меня возникли небольшие проблемы с этим. Файлы, которые я пытаюсь загрузить, находятся здесь.
Я много смотрел в Интернете, и мне, наконец, удалось загрузить одну из них. Я получил UID файлов, и меньший (1,6 МБ) загружается нормально, однако файл большего размера (3,7 ГБ) всегда перенаправляет на страницу, которая спрашивает меня, хочу ли я продолжить загрузку без проверки на вирусы. Может ли кто-нибудь помочь мне пройти этот экран?
Вот как у меня работает первый файл -
curl -L "https://docs.google.com/uc?export=download&id=0Bz-w5tutuZIYeDU0VDRFWG9IVUE" > phlat-1.0.tar.gz
Когда я запускаю то же самое в другом файле,
curl -L "https://docs.google.com/uc?export=download&id=0Bz-w5tutuZIYY3h5YlMzTjhnbGM" > index4phlat.tar.gz
Я получаю следующий вывод - 
Я заметил на третьей до последней строки в ссылке, там &confirm=JwkK которая является случайной 4-х символьной строкой, но предполагает, что есть способ добавить подтверждение в мой URL. Одна из ссылок, которые я посетил, предложила &confirm=no_antivirus но это не работает
Я надеюсь, что кто-то здесь может помочь с этим!
Заранее спасибо.
47 ответов
Посмотрите на этот вопрос: прямая загрузка с Google Drive с помощью Google Drive API
По сути, вы должны создать публичный каталог и обращаться к своим файлам по относительной ссылке с чем-то вроде
wget https://googledrive.com/host/LARGEPUBLICFOLDERID/index4phlat.tar.gz
ВНИМАНИЕ: эта функциональность устарела. Смотрите предупреждение ниже в комментариях.
Кроме того, вы можете использовать этот скрипт: https://github.com/circulosmeos/gdown.pl
Июнь 2018 года Самый простой способ, который работает для меня
pip install gdown- gdown https://drive.google.com/uc?id=file_id
file_id должен выглядеть примерно так: 0Bz8a_Dbh9QhbNU3SGlFaDg
Вы можете получить его, щелкнув правой кнопкой мыши на файле, а затем получить ссылку для совместного использования. Проверено на файлы с открытым доступом. Я не уверен, работает ли он для каталога.
Я написал фрагмент Python, который загружает файл с Google Диска, предоставляя ссылку для совместного использования. Работает с августа 2017 года.
Отрезанный не использует ни gdrive, ни Google Drive API. Он использует модуль запросов.
При загрузке больших файлов с Google Диска одного запроса GET недостаточно. Необходим второй, и у него есть дополнительный параметр URL, называемый подтверждающим, значение которого должно равняться значению определенного cookie.
import requests
def download_file_from_google_drive(id, destination):
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination):
CHUNK_SIZE = 32768
with open(destination, "wb") as f:
for chunk in response.iter_content(CHUNK_SIZE):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params = { 'id' : id }, stream = True)
token = get_confirm_token(response)
if token:
params = { 'id' : id, 'confirm' : token }
response = session.get(URL, params = params, stream = True)
save_response_content(response, destination)
if __name__ == "__main__":
import sys
if len(sys.argv) is not 3:
print("Usage: python google_drive.py drive_file_id destination_file_path")
else:
# TAKE ID FROM SHAREABLE LINK
file_id = sys.argv[1]
# DESTINATION FILE ON YOUR DISK
destination = sys.argv[2]
download_file_from_google_drive(file_id, destination)
Сен 2020
Сначала извлеките идентификатор вашего файла желаний с диска Google:
В браузере перейдите на drive.google.com.
Щелкните файл правой кнопкой мыши и выберите "Получить ссылку для общего доступа".
Затем извлеките идентификатор файла из URL-адреса:

Далее устанавливаем
gdownМодуль PyPI с использованиемpip:pip install gdownНаконец, загрузите файл, используя
gdownи предполагаемый идентификатор:gdown --id <put-the-ID>
[ПРИМЕЧАНИЕ]:
- В google-colab вы должны использовать
!доbashкоманды.
(т.е.!gdown --id 1-1wAx7b-USG0eQwIBVwVDUl3K1_1ReCt)
Вы можете использовать инструмент командной строки Linux / Unix с открытым исходным кодом gdrive,
Чтобы установить его:
Загрузите бинарный файл. Выберите тот, который подходит вашей архитектуре, например
gdrive-linux-x64,Скопируйте его на свой путь.
sudo cp gdrive-linux-x64 /usr/local/bin/gdrive; sudo chmod a+x /usr/local/bin/gdrive;
Чтобы использовать это:
Определите идентификатор файла Google Диска. Для этого щелкните правой кнопкой мыши нужный файл на веб-сайте Google Диска и выберите "Получить ссылку…". Это вернет что-то вроде
https://drive.google.com/open?id=0B7_OwkDsUIgFWXA1B2FPQfV5S8H, Получить строку за?id=и скопируйте его в буфер обмена. Это идентификатор файла.Загрузите файл. Конечно, вместо этого используйте идентификатор вашего файла в следующей команде.
gdrive download 0B7_OwkDsUIgFWXA1B2FPQfV5S8H
При первом использовании инструменту необходимо получить разрешения на доступ к API Google Диска. Для этого он покажет вам ссылку, которую вы должны посетить в браузере, а затем вы получите проверочный код для копирования и вставки обратно в инструмент. Загрузка начнется автоматически. Нет индикатора прогресса, но вы можете наблюдать за прогрессом в файловом менеджере или втором терминале.
Источник: комментарий Тоби к другому ответу здесь.
Дополнительный трюк: ограничение скорости. Скачать с gdrive с ограниченной максимальной скоростью (чтобы не перегружать сеть…), вы можете использовать такую команду (используя PipeViewer):
gdrive download --stdout 0B7_OwkDsUIgFWXA1B2FPQfV5S8H | \
pv -br -L 90k | \
cat > file.ext
Это покажет количество загруженных данных (-b) и скорость загрузки (-r) и ограничить эту скорость до 90 КБ / с (-L 90k).
Вот быстрый способ сделать это.
Убедитесь, что ссылка является общей, и она будет выглядеть примерно так:
https://drive.google.com/open?id=FILEID&authuser=0
Затем скопируйте этот FILEID и используйте его следующим образом
wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILEID' -O FILENAME
Простой способ:
(если вам это нужно для разовой загрузки)
- Перейдите на веб-страницу Google Drive, на которой есть ссылка для скачивания.
- Откройте консоль браузера и перейдите на вкладку "сеть"
- Нажмите на ссылку для скачивания
- Дождитесь начала загрузки файла и найдите соответствующий запрос (должен быть последним в списке), затем вы можете отменить загрузку
- Щелкните правой кнопкой мыши запрос и выберите "Копировать как cURL" (или аналогичный)
Вы должны получить что-то вроде:
curl 'https://doc-0s-80-docs.googleusercontent.com/docs/securesc/aa51s66fhf9273i....................blah blah blah...............gEIqZ3KAQ==' --compressed
Вставьте это в свою консоль, добавьте > my-file-name.extension до конца (иначе он запишет файл в вашу консоль), затем нажмите enter:)
Дополнение от марта 2018.
Я пробовал различные методы, приведенные в других ответах, чтобы загрузить мой файл (6 ГБ) непосредственно с диска Google в мой экземпляр AWS ec2, но ни один из них не работает (возможно, потому, что он старый).
Итак, для информации других, вот как я сделал это успешно:
- Щелкните правой кнопкой мыши по файлу, который вы хотите загрузить, щелкните "Поделиться", в разделе "Обмен ссылками" выберите "любой пользователь, имеющий эту ссылку, может редактировать".
- Скопируйте ссылку. Он должен быть в следующем формате: https://drive.google.com/file/d/FILEIDENTIFIER/view?usp=sharing
- Скопируйте часть FILEIDENTIFIER из ссылки (это похоже на некоторые случайные символы).
Скопируйте приведенный ниже скрипт в файл. Он использует curl и обрабатывает cookie для автоматизации загрузки файла.
#!/bin/bash fileid="FILEIDENTIFIER" filename="FILENAME" curl -c ./cookie -s -L "https://drive.google.com/uc?export=download&id=${fileid}" > /dev/null curl -Lb ./cookie "https://drive.google.com/uc?export=download&confirm=`awk '/download/ {print $NF}' ./cookie`&id=${fileid}" -o ${filename}Как показано выше, вставьте ФАЙЛИДЕНТИФИКАТОР в скрипт. Не забудьте сохранить двойные кавычки.
- Дайте имя вашему выходному файлу вместо FILENAME. Не забудьте сохранить двойные кавычки, а также включить расширение в FILENAME (например, "myfile.zip").
- Теперь сохраните файл и сделайте его исполняемым, выполнив эту команду в терминале "sudo chmod +x download-script.sh". Замените "download-script.sh" именем вашего скрипта.
- Запустите скрипт, используя "./download-script.sh". Снова замените "download-script.sh" именем вашего скрипта.
PS: Вот суть Github для приведенного выше сценария: https://gist.github.com/amit-chahar/db49ce64f46367325293e4cce13d2424
ggID='put_googleID_here'
ggURL='https://drive.google.com/uc?export=download'
filename="$(curl -sc /tmp/gcokie "${ggURL}&id=${ggID}" | grep -o '="uc-name.*</span>' | sed 's/.*">//;s/<.a> .*//')"
getcode="$(awk '/_warning_/ {print $NF}' /tmp/gcokie)"
curl -Lb /tmp/gcokie "${ggURL}&confirm=${getcode}&id=${ggID}" -o "${filename}"
Как это работает?
Получить файл cookie и HTML-код с помощью curl.
Передайте html в grep и sed и найдите имя файла.
Получить код подтверждения из файла cookie с помощью awk.
Наконец загрузите файл с включенным файлом cookie, подтвердите код и имя файла.
curl -Lb /tmp/gcokie "https://drive.google.com/uc?export=download&confirm=Uq6r&id=0B5IRsLTwEO6CVXFURmpQZ1Jxc0U" -o "SomeBigFile.zip"
Если вам не нужна переменная имени файла, curl может угадать это
-L Следить за редиректом
-O Remote-имя
-J Remote-header-name
curl -sc /tmp/gcokie "${ggURL}&id=${ggID}" >/dev/null
getcode="$(awk '/_warning_/ {print $NF}' /tmp/gcokie)"
curl -LOJb /tmp/gcokie "${ggURL}&confirm=${getcode}&id=${ggID}"
Чтобы извлечь идентификатор файла Google из URL, вы можете использовать:
echo "gURL" | egrep -o '(\w|-){26,}'
# match more than 26 word characters
ИЛИ ЖЕ
echo "gURL" | sed 's/[^A-Za-z0-9_-]/\n/g' | sed -rn '/.{26}/p'
# replace non-word characters with new line,
# print only line with more than 26 word characters
Поведение Google Drive по умолчанию - сканировать файлы на наличие вирусов. Если размер файла слишком велик, он побуждает пользователя и уведомляет его о невозможности сканирования файла.
На данный момент единственный обходной путь, который я нашел, - это поделиться файлом с Интернетом и создать веб-ресурс.
Цитата со страницы справки Google Drive:
С помощью Drive вы можете сделать веб-ресурсы - такие как файлы HTML, CSS и Javascript - видимыми как веб-сайт.
Чтобы разместить веб-страницу с помощью Drive:
- Откройте диск на drive.google.com и выберите файл.
- Нажмите кнопку " Поделиться" в верхней части страницы.
- Нажмите " Дополнительно" в правом нижнем углу окна обмена.
- Нажмите Изменить....
- Выберите On - Public в Интернете и нажмите Save.
- Перед закрытием поля для обмена скопируйте идентификатор документа с URL-адреса в поле ниже "Ссылка для обмена". Идентификатор документа представляет собой строку прописных и строчных букв и цифр между косыми чертами в URL.
- Поделитесь URL-адресом, который выглядит как "www.googledrive.com/host/[doc id], где [doc id] заменяется идентификатором документа, который вы скопировали на шаге 6.
Любой может теперь просматривать вашу веб-страницу.
Найдено здесь: https://support.google.com/drive/answer/2881970?hl=en
Так, например, когда вы публикуете файл на диске Google публично, sharelink выглядит так:
https://drive.google.com/file/d/0B5IRsLTwEO6CVXFURmpQZ1Jxc0U/view?usp=sharing
Затем вы копируете идентификатор файла и создаете линк googledrive.com, который выглядит следующим образом:
https://www.googledrive.com/host/0B5IRsLTwEO6CVXFURmpQZ1Jxc0U
На основании ответа от Рошана Сетия
Май 2018
Использование WGET:
Создайте скрипт оболочки с именем wgetgdrive.sh, как показано ниже:
#!/bin/bash # Get files from Google Drive # $1 = file ID # $2 = file name URL="https://docs.google.com/uc?export=download&id=$1" wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate $URL -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$1" -O $2 && rm -rf /tmp/cookies.txtДайте права доступа для выполнения скрипта
В терминале запустите:
./wgetgdrive.sh <file ID> <filename>например:
./wgetgdrive.sh 1lsDPURlTNzS62xEOAIG98gsaW6x2PYd2 images.zip
С 2022 года вы можете использовать это решение:
https://drive.google.com/uc?export=download&amp;id=FILE_ID&amp;confirm=t
Источник «страницы с предупреждением о сканировании на вирусы»:
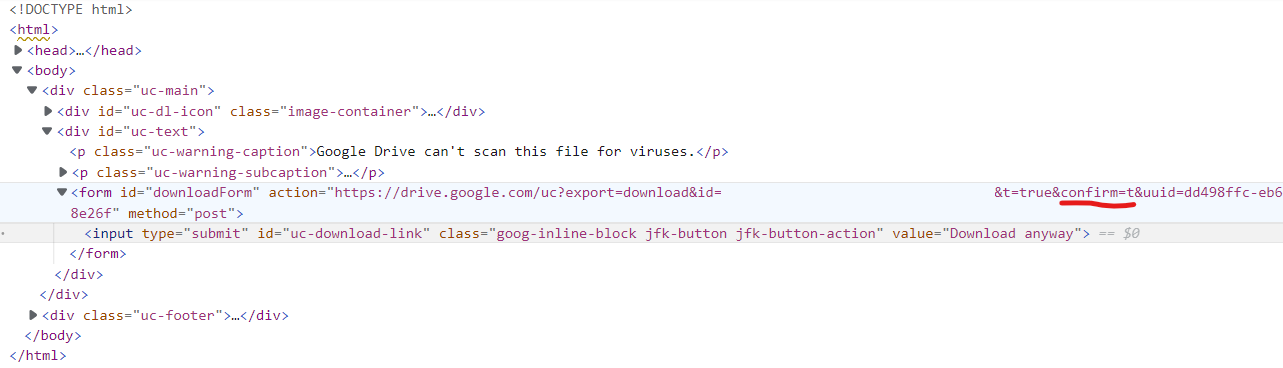
форма «Все равно скачать» отправляет сообщение на тот же URL-адрес, но с тремя дополнительными параметрами:
-
t -
confirm -
uuid
Если вы измените исходный URL-адрес и добавите один из них: , он загрузит файл без страницы с предупреждением.
Так что просто измените свой URL на
https://drive.google.com/uc?export=download&id=FILE_ID&confirm=t
Например:
$ curl -L 'https://drive.google.com/uc?export=download&id=FILE_ID' > large_video.mp4
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2263 0 2263 0 0 5426 0 --:--:-- --:--:-- --:--:-- 5453
После добавленияconfirm=t, результат:
$ curl -L 'https://drive.google.com/uc?export=download&id=FILE_ID&confirm=t' > large_video.mp4
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 128M 100 128M 0 0 10.2M 0 0:00:12 0:00:12 --:--:-- 10.9M
Получить пакет.
youtube-dl: https://rg3.github.io/youtube-dl/download.html
или же
sudo python2.7 -m pip install --upgrade youtube_dl /// sudo python3.6 -m pip install --upgrade youtube_dl
Создайте общую ссылку, как указано выше
Link sharing on
Anyone with the link can access
Скопируйте ссылку в окно в режиме инкогнито: https://drive.google.com/a/hostname_here.com/file/d/kfjsdlkfjskljfkjskfjsskljfsjfklsjdf/view?usp=sharing
Будет изменена ссылка на: https://drive.google.com/file/d/yuituyituiyuityuiutiuyituitiyuituiyuituyit/view
Нажмите на Загрузить
Новая страница появится
Щелкните правой кнопкой мыши на имени файла и скопируйте его адрес
Перейти к терминалу
Тип:
youtube-dl https://drive.google.com/open?id=opopopopoppopop_nmnmnmnmnmnmnmn
[GoogleDrive] opopopopoppopop_nmnmnmnmnmnmnmn: Downloading webpage
[GoogleDrive] opopopopoppopop_nmnmnmnmnmnmnmn: Requesting source file
[download] Destination: your_file_name_here.zip-opopopopoppopop_nmnmnmnmnmnmnmn.zip
[download] 100% of 61.51MiB in 01:10
Надеюсь, поможет
Я использовал curl-фрагмент @ Amit Chahar, который опубликовал хороший ответ в этой теме. Я счел полезным поместить его в функцию bash, а не в отдельный.sh файл
function curl_gdrive {
GDRIVE_FILE_ID=$1
DEST_PATH=$2
curl -c ./cookie -s -L "https://drive.google.com/uc?export=download&id=${GDRIVE_FILE_ID}" > /dev/null
curl -Lb ./cookie "https://drive.google.com/uc?export=download&confirm=`awk '/download/ {print $NF}' ./cookie`&id=${GDRIVE_FILE_ID}" -o ${DEST_PATH}
rm -fr cookie
}
которые могут быть включены, например, в ~/.bashrc (разумеется, после получения, если не получен автоматически) и используется следующим образом
$ curl_gdrive 153bpzybhfqDspyO_gdbcG5CMlI19ASba imagenet.tar
Все приведенные выше ответы, кажется, затемняют простоту ответа или имеют некоторые нюансы, которые не объясняются.
Если файл является общедоступным, вы можете создать прямую ссылку для скачивания, просто зная идентификатор файла. URL-адрес должен иметь вид " https://drive.google.com/uc?id=[FILEID]&export=download visible&export=download". Это работает с 22.11.2019. Это не требует от получателя входа в систему Google, но требует, чтобы файл был общедоступным.
В браузере перейдите на drive.google.com.
Щелкните файл правой кнопкой мыши и выберите "Получить ссылку для общего доступа".
- Откройте новую вкладку, выберите адресную строку и вставьте содержимое буфера обмена, который будет общей ссылкой. Вы увидите файл, отображаемый программой просмотра Google. Идентификатор - это номер прямо перед компонентом "Просмотр" URL:
Измените URL-адрес, чтобы он имел следующий формат, заменив "[FILEID]" идентификатором вашего общего файла:
Это ваша прямая ссылка для скачивания. Если вы щелкнете по нему в своем браузере, файл теперь будет "отправлен" в ваш браузер, откроется диалоговое окно загрузки, позволяющее сохранить или открыть файл. Вы также можете использовать эту ссылку в своих сценариях загрузки.
Таким образом, эквивалентная команда curl будет такой:
curl -L "https://drive.google.com/uc?id=AgOATNfjpovfFrft9QYa-P1IeF9e7GWcH&export=download" > phlat-1.0.tar.gz
Самый простой способ это:
- Создать ссылку для скачивания и скопировать fileID
- Скачать с WGET:
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILEID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=FILEID" -O FILENAME && rm -rf /tmp/cookies.txt
Приведенные выше ответы устарели на апрель 2020 года, так как Google Drive теперь использует перенаправление на фактическое местоположение файла.
Работающие с апреля 2020 г. на macOS 10.15.4 для общедоступных документов:
# this is used for drive directly downloads
function download-google(){
echo "https://drive.google.com/uc?export=download&id=$1"
mkdir -p .tmp
curl -c .tmp/$1cookies "https://drive.google.com/uc?export=download&id=$1" > .tmp/$1intermezzo.html;
curl -L -b .tmp/$1cookies "$(egrep -o "https.+download" .tmp/$1intermezzo.html)" > $2;
}
# some files are shared using an indirect download
function download-google-2(){
echo "https://drive.google.com/uc?export=download&id=$1"
mkdir -p .tmp
curl -c .tmp/$1cookies "https://drive.google.com/uc?export=download&id=$1" > .tmp/$1intermezzo.html;
code=$(egrep -o "confirm=(.+)&id=" .tmp/$1intermezzo.html | cut -d"=" -f2 | cut -d"&" -f1)
curl -L -b .tmp/$1cookies "https://drive.google.com/uc?export=download&confirm=$code&id=$1" > $2;
}
# used like this
download-google <id> <name of item.extension>
Нет ответа предлагает то, что работает для меня по состоянию на декабрь 2016 года ( источник):
curl -L https://drive.google.com/uc?id={FileID}
при условии, что файл Google Диска был передан тем, у кого есть ссылка и {FileID} это строка позади ?id= в общем URL.
Хотя я не проверял с большими файлами, я думаю, что это может быть полезно знать.
У меня была такая же проблема с Google Drive.
Вот как я решил проблему, используя Ссылки 2.
Откройте браузер на вашем ПК, перейдите к файлу на Google Диске. Дайте вашему файлу публичную ссылку.
Скопируйте общедоступную ссылку в буфер обмена (например, щелкните правой кнопкой мыши, скопируйте адрес ссылки)
Откройте Терминал. Если вы загружаете на другой компьютер / сервер / компьютер, вы должны использовать SSH, как показано ниже.
Установите ссылки 2 (метод debian/ubuntu, используйте ваш дистрибутив или аналог ОС)
sudo apt-get install links2Вставьте ссылку в свой терминал и откройте ее с помощью ссылок следующим образом:
links2 "paste url here"Перейдите к ссылке на скачивание в ссылках, используя клавиши со стрелками, и нажмите Enter
Выберите имя файла, и он загрузит ваш файл
Используйте YouTube-DL!
youtube-dl https://drive.google.com/open?id=ABCDEFG1234567890
Вы также можете пройти --get-url чтобы получить URL для прямой загрузки.
Вот так в 2023 году:
FILEID="unique_google_drive_id"
FILENAME="output_filename"
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=${FILEID}' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=${FILEID}" -O ${FILENAME} && rm -rf /tmp/cookies.txt
Простой способ скачать файл с диска Google, вы также можете скачать файл на colab
pip install gdown
import gdown
потом
url = 'https://drive.google.com/uc?id=0B9P1L--7Wd2vU3VUVlFnbTgtS2c'
output = 'spam.txt'
gdown.download(url, output, quiet=False)
или
fileid='0B9P1L7Wd2vU3VUVlFnbTgtS2c'
gdown https://drive.google.com/uc?id=+fileid
Документ https://pypi.org/project/gdown/
Мне не удалось заставить работать perl-скрипт Nanoix или другие примеры curl, которые я видел, поэтому я сам начал изучать API в python. Это работало хорошо для маленьких файлов, но большие файлы заполняли доступный оперативный памяти, поэтому я нашел другой хороший код, который использует API для частичной загрузки. Гист здесь: https://gist.github.com/csik/c4c90987224150e4a0b2
Обратите внимание на загрузку json-файла client_secret из интерфейса API в локальный каталог.
Источник$ cat gdrive_dl.py
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
"""API calls to download a very large google drive file. The drive API only allows downloading to ram
(unlike, say, the Requests library's streaming option) so the files has to be partially downloaded
and chunked. Authentication requires a google api key, and a local download of client_secrets.json
Thanks to Radek for the key functions: http://stackru.com/questions/27617258/memoryerror-how-to-download-large-file-via-google-drive-sdk-using-python
"""
def partial(total_byte_len, part_size_limit):
s = []
for p in range(0, total_byte_len, part_size_limit):
last = min(total_byte_len - 1, p + part_size_limit - 1)
s.append([p, last])
return s
def GD_download_file(service, file_id):
drive_file = service.files().get(fileId=file_id).execute()
download_url = drive_file.get('downloadUrl')
total_size = int(drive_file.get('fileSize'))
s = partial(total_size, 100000000) # I'm downloading BIG files, so 100M chunk size is fine for me
title = drive_file.get('title')
originalFilename = drive_file.get('originalFilename')
filename = './' + originalFilename
if download_url:
with open(filename, 'wb') as file:
print "Bytes downloaded: "
for bytes in s:
headers = {"Range" : 'bytes=%s-%s' % (bytes[0], bytes[1])}
resp, content = service._http.request(download_url, headers=headers)
if resp.status == 206 :
file.write(content)
file.flush()
else:
print 'An error occurred: %s' % resp
return None
print str(bytes[1])+"..."
return title, filename
else:
return None
gauth = GoogleAuth()
gauth.CommandLineAuth() #requires cut and paste from a browser
FILE_ID = 'SOMEID' #FileID is the simple file hash, like 0B1NzlxZ5RpdKS0NOS0x0Ym9kR0U
drive = GoogleDrive(gauth)
service = gauth.service
#file = drive.CreateFile({'id':FILE_ID}) # Use this to get file metadata
GD_download_file(service, FILE_ID)
Я нашел рабочее решение для этого... Просто используйте следующее
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1HlzTR1-YVoBPlXo0gMFJ_xY4ogMnfzDi' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1HlzTR1-YVoBPlXo0gMFJ_xY4ogMnfzDi" -O besteyewear.zip && rm -rf /tmp/cookies.txt
Это работает с ноября 2017 года https://gist.github.com/ppetraki/258ea8240041e19ab258a736781f06db
#!/bin/bash
SOURCE="$1"
if [ "${SOURCE}" == "" ]; then
echo "Must specify a source url"
exit 1
fi
DEST="$2"
if [ "${DEST}" == "" ]; then
echo "Must specify a destination filename"
exit 1
fi
FILEID=$(echo $SOURCE | rev | cut -d= -f1 | rev)
COOKIES=$(mktemp)
CODE=$(wget --save-cookies $COOKIES --keep-session-cookies --no-check-certificate "https://docs.google.com/uc?export=download&id=${FILEID}" -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/Code: \1\n/p')
# cleanup the code, format is 'Code: XXXX'
CODE=$(echo $CODE | rev | cut -d: -f1 | rev | xargs)
wget --load-cookies $COOKIES "https://docs.google.com/uc?export=download&confirm=${CODE}&id=${FILEID}" -O $DEST
rm -f $COOKIES
После возни с этим мусором. Я нашел способ загрузить мой сладкий файл с помощью инструментов разработчика Chrome.
- На вкладке "Документы" Google Ctr+Shift+J (Настройка -> Инструменты разработчика)
- Переключиться на вкладки сети
- В файле документации нажмите "Загрузить" -> Загрузить как CSV, xlsx,....
Он покажет вам запрос в консоли "Сеть"

Щелкните правой кнопкой мыши -> Копировать -> Копировать как завиток
- Ваша команда Curl будет такой, и добавьте
-oсоздать экспортированный файл.curl 'https://docs.google.com/spreadsheets/d/1Cjsryejgn29BDiInOrGZWvg/export?format=xlsx&id=1Cjsryejgn29BDiInOrGZWvg' -H 'authority: docs.google.com' -H 'upgrade-insecure-requests: 1' -H 'user-agent: Mozilla/5.0 (X..... -o server.xlsx
Решено!
Есть мультиплатформенный клиент с открытым исходным кодом, написанный на Go: drive. Это довольно красиво и полнофункционально, а также находится в активной разработке.
$ drive help pull
Name
pull - pulls remote changes from Google Drive
Description
Downloads content from the remote drive or modifies
local content to match that on your Google Drive
Note: You can skip checksum verification by passing in flag `-ignore-checksum`
* For usage flags: `drive pull -h`
Есть более простой способ.
Установите cliget/CURLWGET из расширения Firefox/ Chrome.
Загрузите файл из браузера. Это создает ссылку curl/wget, которая запоминает файлы cookie и заголовки, используемые при загрузке файла. Используйте эту команду из любой оболочки для загрузки
Альтернативный метод, 2020
Хорошо работает для безголовых серверов. Я пытался загрузить частный файл размером ~200 ГБ, но не смог заставить работать ни один из других методов, упомянутых в этом потоке.
Решение
- (Пропустите этот шаг, если файл уже находится на вашем собственном диске Google). Сделайте копию файла, который вы хотите загрузить из общей / общей папки, в свою учетную запись Google Диска. Выберите Файл -> Щелкните правой кнопкой мыши -> Сделать копию
Установите и настройте Rclone, инструмент командной строки с открытым исходным кодом, для синхронизации файлов между вашим локальным хранилищем и Google Диском. Вот краткое руководство по установке и настройке rclone для Google Диска.
Скопируйте файл с Google Диска на свой компьютер с помощью Rclone
rclone copy mygoogledrive:path/to/file /path/to/file/on/local/machine -P
-P Аргумент помогает отслеживать прогресс загрузки и позволяет узнать, когда она завершена.
Вот небольшой скрипт bash, который я написал, который делает работу сегодня. Он работает с большими файлами и может восстанавливать частично извлеченные файлы. Он принимает два аргумента: первый - file_id, а второй - имя выходного файла. Основные улучшения по сравнению с предыдущими ответами здесь заключаются в том, что он работает с большими файлами и нуждается только в общедоступных инструментах: bash, curl, tr, grep, du, cut и mv.
#!/usr/bin/env bash
fileid="$1"
destination="$2"
# try to download the file
curl -c /tmp/cookie -L -o /tmp/probe.bin "https://drive.google.com/uc?export=download&id=${fileid}"
probeSize=`du -b /tmp/probe.bin | cut -f1`
# did we get a virus message?
# this will be the first line we get when trying to retrive a large file
bigFileSig='<!DOCTYPE html><html><head><title>Google Drive - Virus scan warning</title><meta http-equiv="content-type" content="text/html; charset=utf-8"/>'
sigSize=${#bigFileSig}
if (( probeSize <= sigSize )); then
virusMessage=false
else
firstBytes=$(head -c $sigSize /tmp/probe.bin)
if [ "$firstBytes" = "$bigFileSig" ]; then
virusMessage=true
else
virusMessage=false
fi
fi
if [ "$virusMessage" = true ] ; then
confirm=$(tr ';' '\n' </tmp/probe.bin | grep confirm)
confirm=${confirm:8:4}
curl -C - -b /tmp/cookie -L -o "$destination" "https://drive.google.com/uc?export=download&id=${fileid}&confirm=${confirm}"
else
mv /tmp/probe.bin "$destination"
fi