Получение индекса возвращенного элемента max или min с использованием max()/min() в списке
Я использую питон max а также min функции в списках для минимаксного алгоритма, и мне нужен индекс значения, возвращаемого max() или же min(), Другими словами, мне нужно знать, какой ход дал максимальное (на ход первого игрока) или минимальное (второй игрок) значение.
for i in range(9):
newBoard = currentBoard.newBoardWithMove([i / 3, i % 3], player)
if newBoard:
temp = minMax(newBoard, depth + 1, not isMinLevel)
values.append(temp)
if isMinLevel:
return min(values)
else:
return max(values)
Мне нужно иметь возможность возвращать фактический индекс минимального или максимального значения, а не только значение.
27 ответов
если isMinLevel:
возвращаемые значения. Индекс (мин (значения))
еще:
возвращаемые значения. индекс (max(значения))
Скажи, что у тебя есть список values = [3,6,1,5]и нужен индекс наименьшего элемента, т.е. index_min = 2 в этом случае.
Избегайте решения с itemgetter() представлены в других ответах, и используйте вместо
index_min = min(xrange(len(values)), key=values.__getitem__)
потому что это не требует import operator ни использовать enumerateи это всегда быстрее (тест ниже), чем решение, использующее itemgetter(),
Если вы имеете дело с массивами NumPy или можете позволить себе numpy в качестве зависимости, рассмотрите также использование
import numpy as np
index_min = np.argmin(values)
Это будет быстрее, чем первое решение, даже если вы примените его к чистому списку Python, если:
- это больше, чем несколько элементов (около 2**4 элементов на моей машине)
- Вы можете позволить себе копию памяти из чистого списка в
numpyмассив
как показывает этот тест: 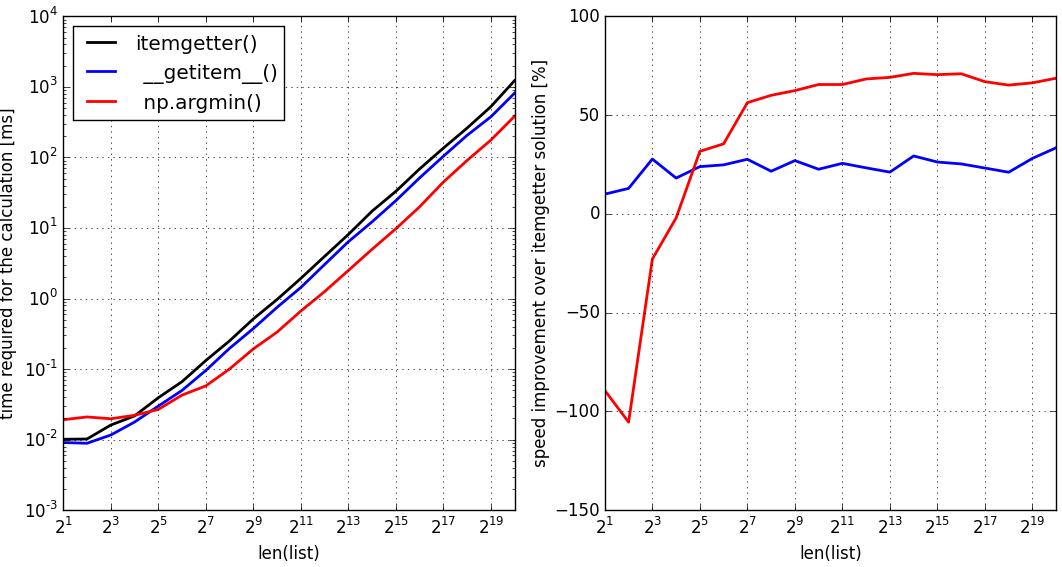
Я запустил бенчмарк на моей машине с python 2.7 для двух вышеупомянутых решений (синий: чистый питон, первое решение) (красный, пустое решение) и для стандартного решения на основе itemgetter() (черный, эталонный раствор). Тот же тест с python 3.5 показал, что методы сравнивают точно так же, как и в случае с Python 2.7, представленным выше.
Вы можете найти мин / макс индекс и значение одновременно, если вы перечисляете элементы в списке, но выполняете мин / макс для исходных значений списка. Вот так:
import operator
min_index, min_value = min(enumerate(values), key=operator.itemgetter(1))
max_index, max_value = max(enumerate(values), key=operator.itemgetter(1))
Таким образом, список будет проходиться только один раз за мин (или макс).
Если вы хотите найти индекс max в списке чисел (что кажется вашим случаем), то я предлагаю вам использовать numpy:
import numpy as np
ind = np.argmax(mylist)
Возможно, более простое решение состояло бы в том, чтобы превратить массив значений в массив значений, индексные пары и взять максимум / мин этого. Это дало бы наибольший / наименьший индекс, который имеет максимум / мин (т.е. пары сравниваются, сначала сравнивая первый элемент, а затем сравнивая второй элемент, если первые совпадают). Обратите внимание, что на самом деле не нужно создавать массив, потому что min / max разрешают генераторы в качестве входных данных.
values = [3,4,5]
(m,i) = max((v,i) for i,v in enumerate(values))
print (m,i) #(5, 2)
list=[1.1412, 4.3453, 5.8709, 0.1314]
list.index(min(list))
Даст вам первый индекс минимума.
Я также заинтересовался этим и сравнил некоторые из предложенных решений, используя perfplot ( мой любимый проект).
Оказывается, аргмин этого numpy,
numpy.argmin(x)
самый быстрый метод для достаточно больших списков, даже с неявным преобразованием из входных данных list к numpy.array,
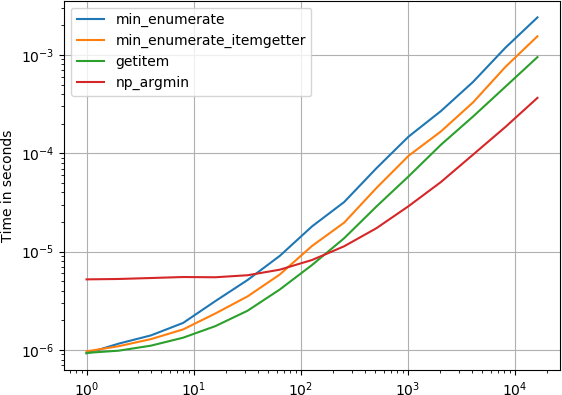
Код для генерации сюжета:
import numpy
import operator
import perfplot
def min_enumerate(a):
return min(enumerate(a), key=lambda x: x[1])[0]
def min_enumerate_itemgetter(a):
min_index, min_value = min(enumerate(a), key=operator.itemgetter(1))
return min_index
def getitem(a):
return min(range(len(a)), key=a.__getitem__)
def np_argmin(a):
return numpy.argmin(a)
perfplot.show(
setup=lambda n: numpy.random.rand(n).tolist(),
kernels=[
min_enumerate,
min_enumerate_itemgetter,
getitem,
np_argmin,
],
n_range=[2**k for k in range(15)],
logx=True,
logy=True,
)
Я думаю, что лучшее, что нужно сделать, это преобразовать список в numpy array и используйте эту функцию:
a = np.array(list)
idx = np.argmax(a)
Я думаю, что ответ выше решает вашу проблему, но я подумал, что поделюсь методом, который дает вам минимум и все показатели, в которых появляется минимум.
minval = min(mylist)
ind = [i for i, v in enumerate(mylist) if v == minval]
Это проходит список дважды, но все еще довольно быстро. Это, однако, немного медленнее, чем нахождение индекса первого столкновения минимума. Так что если вам нужен только один из минимумов, используйте решение Matt Anderson, если вам нужны все, используйте это.
После того, как вы получите максимальные значения, попробуйте это:
max_val = max(list)
index_max = list.index(max_val)
Гораздо проще, чем много вариантов.
Есть два ответа ( , ), которые включают тест, но по какой-то причине ни один из них не включен в тест, хотя это было предложено в принятом ответе, который был опубликован как минимум за 2 года до этих ответов.
list.index()это самый быстрый вариант, представленный на этой странице, включая (все версии, которые его включают),__getitem__и .
Более того, если список имеет неуникальное минимальное значение и вы хотите получить все индексы, в которых встречается минимальное значение, цикл while превосходит другие параметры, такие как numpy и также. Обратите внимание, что вы можете ограничить поиск, начиная с определенного индекса, передав начальную точку (которая является вторым аргументом ), что имеет решающее значение для производительности, поскольку мы не хотим выполнять поиск с начала на каждой итерации while- петля.
# get the index of the minimum value
my_list = [1, 2, 0, 1]
idxmin = my_list.index(min(my_list))
print(idxmin) # 2
# get all indices where the min value occurs
my_list = [1, 2, 3, 1]
idxmins = []
min_val = min(my_list)
pos = -1
while True:
try:
pos = my_list.index(min_val, pos+1)
# ^^^^^ <---- pick up where we left off in the previous iteration
idxmins.append(pos)
except ValueError:
break
print(idxmins) # [0, 3]
Следующие тесты (выполненные на Python 3.11.4 и numpy 1.25.2) показывают, что это почти в два раза быстрее, чем все остальные варианты, независимо от длины списка. Левый график также показывает, чтоgetitemвыполняет то же самое, что и (иnumpy.argmin) для длинных списков, что показывает, что тесты 1gg349 и 2Нико устарели.
Правый график показывает, что если минимальное значение не уникально и мы хотим найти все индексы минимального значения, тоlist.indexЦикл in a while, описанный выше, работает намного лучше, чем конкурирующие варианты, включающиеenumerateили numpy, особенно для длинных списков.
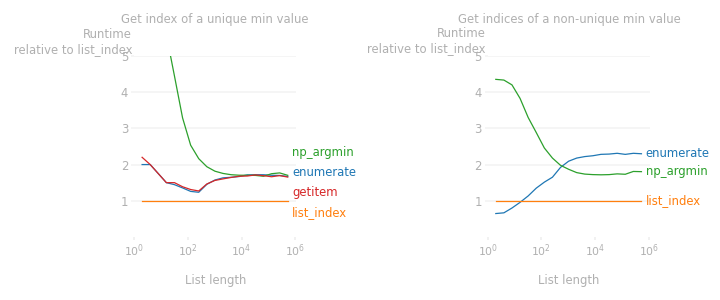
Код, использованный для создания рисунка выше:
from operator import itemgetter
import numpy as np
import matplotlib.pyplot as plt
import perfplot
def enumerate_1(a):
return min(enumerate(a), key=itemgetter(1))[0]
def np_argmin_1(a):
return np.argmin(a)
def getitem(a):
return min(range(len(a)), key=a.__getitem__)
def list_index_1(a):
return a.index(min(a))
def enumerate_2(a):
min_val = min(a)
return [i for i, v in enumerate(a) if v == min_val]
def np_argmin_2(a):
arr = np.array(a)
return np.arange(len(a))[arr==arr.min()]
def list_index_2(a):
result = []
min_val = min(a)
pos = -1
while True:
try:
pos = a.index(min_val, pos+1)
result.append(pos)
except ValueError:
break
return result
kernels_list = [[enumerate_1, list_index_1, np_argmin_1, getitem],
[enumerate_2, list_index_2, np_argmin_2]]
n_range = [2**k for k in range(1, 20)]
su = lambda n: list(range(n, 0, -1))
titles = ['Get index of a unique min value',
'Get indices of a non-unique min value']
labels = ['enumerate', 'list_index', 'np_argmin', 'getitem']
xlabel = 'List length'
fig, axs = plt.subplots(1, 2, figsize=(12, 5), facecolor='white', dpi=60)
for ax, ks, t in zip(axs, kernels_list, titles):
plt.sca(ax)
perfplot.plot(ks, n_range, su, None, labels, xlabel, t, relative_to=1)
ax.xaxis.set_tick_params(labelsize=13)
plt.setp(axs, ylim=(0, 5), yticks=range(1, 6),
xlim=(1, 1100000), xscale='log', xticks=[1, 100, 10000, 1000000]);
fig.tight_layout();
fig.savefig('benchmark.png', dpi=60);
Это просто возможно с помощью встроенного enumerate() а также max() функция и дополнительный key аргумент max() функция и простое лямбда-выражение:
theList = [1, 5, 10]
maxIndex, maxValue = max(enumerate(theList), key=lambda v: v[1])
# => (2, 10)
В документах для max() это говорит о том, что key Аргумент ожидает функцию, как в list.sort() функция. Также см. Сортировка Как.
Это работает так же для min(), Кстати, он возвращает первое максимальное / минимальное значение.
У Pandas теперь есть гораздо более щадящее решение, попробуйте:
df[column].idxmax()
Используйте массив numpy и функцию argmax()
a=np.array([1,2,3])
b=np.argmax(a)
print(b) #2
Используйте функцию numpy модуля numpy.where
import numpy as n
x = n.array((3,3,4,7,4,56,65,1))
Для индекса минимального значения:
idx = n.where(x==x.min())[0]
Для индекса максимального значения:
idx = n.where(x==x.max())[0]
На самом деле эта функция намного мощнее. Вы можете задавать все виды логических операций. Для индекса значения от 3 до 60:
idx = n.where((x>3)&(x<60))[0]
idx
array([2, 3, 4, 5])
x[idx]
array([ 4, 7, 4, 56])
Скажем, у вас есть список, такой как:
a = [9,8,7]
Следующие два метода являются довольно компактными способами получить кортеж с минимальным элементом и его индексом. Оба требуют одинакового времени для обработки. Мне больше нравится метод zip, но это мой вкус.
почтовый метод
element, index = min(list(zip(a, range(len(a)))))
min(list(zip(a, range(len(a)))))
(7, 2)
timeit min(list(zip(a, range(len(a)))))
1.36 µs ± 107 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
метод перечисления
index, element = min(list(enumerate(a)), key=lambda x:x[1])
min(list(enumerate(a)), key=lambda x:x[1])
(2, 7)
timeit min(list(enumerate(a)), key=lambda x:x[1])
1.45 µs ± 78.1 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
Пока вы знаете, как использовать лямбду и аргумент "ключ", простое решение:
max_index = max( range( len(my_list) ), key = lambda index : my_list[ index ] )
Просто как тот:
stuff = [2, 4, 8, 15, 11]
index = stuff.index(max(stuff))
Зачем сначала добавлять индексы, а потом наоборот? Функция enumerate() - это особый случай использования функции zip(). Давайте использовать его соответствующим образом:
my_indexed_list = zip(my_list, range(len(my_list)))
min_value, min_index = min(my_indexed_list)
max_value, max_index = max(my_indexed_list)
Простой способ найти индексы с минимальным значением в списке, если вы не хотите импортировать дополнительные модули:
min_value = min(values)
indexes_with_min_value = [i for i in range(0,len(values)) if values[i] == min_value]
Затем выберите, например, первый:
choosen = indexes_with_min_value[0]
Предполагая, что у вас есть следующий список
my_list = [1,2,3,4,5,6,7,8,9,10] и мы знаем, что если мы это сделаем
max(my_list) он вернется
10 и
min(my_list) вернется
1. Теперь мы хотим получить индекс максимального или минимального элемента, мы можем сделать следующее.
my_list = [1,2,3,4,5,6,7,8,9,10]
max_value = max(my_list) # returns 10
max_value_index = my_list.index(max_value) # retuns 9
#to get an index of minimum value
min_value = min(my_list) # returns 1
min_value_index = my_list.index(min_value) # retuns 0
https://docs.python.org/3/library/functions.html
Если несколько элементов максимальны, функция возвращает первый встреченный элемент. Это согласуется с другими инструментами сохранения стабильности сортировки, такими как sorted(iterable, key=keyfunc, reverse=True)[0]
Чтобы получить больше, чем просто первый, используйте метод сортировки.
import operator
x = [2, 5, 7, 4, 8, 2, 6, 1, 7, 1, 8, 3, 4, 9, 3, 6, 5, 0, 9, 0]
min = False
max = True
min_val_index = sorted( list(zip(x, range(len(x)))), key = operator.itemgetter(0), reverse = min )
max_val_index = sorted( list(zip(x, range(len(x)))), key = operator.itemgetter(0), reverse = max )
min_val_index[0]
>(0, 17)
max_val_index[0]
>(9, 13)
import ittertools
max_val = max_val_index[0][0]
maxes = [n for n in itertools.takewhile(lambda x: x[0] == max_val, max_val_index)]
Просто незначительное дополнение к тому, что уже было сказано.values.index(min(values)) кажется, возвращает наименьший индекс мин. Следующее получает самый большой индекс:
values.reverse()
(values.index(min(values)) + len(values) - 1) % len(values)
values.reverse()
Последняя строка может быть пропущена, если не имеет значения побочный эффект реверса на месте.
Перебирать все вхождения
indices = []
i = -1
for _ in range(values.count(min(values))):
i = values[i + 1:].index(min(values)) + i + 1
indices.append(i)
Ради краткости. Это, вероятно, лучшая идея для кэширования min(values), values.count(min) вне петли.
У вас недостаточно высокой репутации, чтобы прокомментировать существующий ответ.
Это работает для целых чисел, но не работает для массива с плавающей точкой (по крайней мере, в Python 3.6). TypeError: list indices must be integers or slices, not float
Как насчет этого:
a=[1,55,2,36,35,34,98,0]
max_index=dict(zip(a,range(len(a))))[max(a)]
Он создает словарь из элементов в a как ключи и их индексы как значения, таким образом dict(zip(a,range(len(a))))[max(a)] возвращает значение, соответствующее ключу max(a)который является индексом максимума в a. Я новичок в Python, поэтому не знаю о вычислительной сложности этого решения.
Использование индексов List Comprehension = [индекс для индекса в диапазоне (len(список)) if list[index] == min/maxVal]print(indices)
Чтобы получить индекс минимального значения в данном списке, ПРОСТО:
arr = [4, 0, -3]
indexOfMin = arr.index(min(arr))
print(indexOfMin) #prints 2
а для индекса максимального значения просто замените min с max во второй строке