Http Performance - много маленьких запросов или один большой
Сценарий:
- На моем сайте я показываю книги.
- Пользователь может добавить каждую книгу в список "Читать позже".
Поведение:
Когда пользователь заходит на сайт, ему предоставляется список книг. Некоторые из них уже есть в списке "Читать позже", некоторые нет.
Пользователь имеет указание рядом с каждой книгой, указывающее, была ли книга добавлена в список или нет.
Моя проблема
Я обсуждаю, какой вариант является идеальным для моей ситуации.
Опция 1:
- Для каждой книги запросите сервер, существует ли он уже в списке пользователей.
- Обновите индикатор для каждой книги.
Pro: Очень маленький запрос к серверу и очень легкий ответ (true или false).
Против: На странице с 30 книгами я отправлю 30 отдельных http-запросов, которые могут блокировать сокеты, и это довольно медленно, учитывая, что браузер и сервер должны выполнять полное рукопожатие для каждой транзакции.
Вариант 2:
- Я запрашиваю сервер один раз и получаю ответ с полным списком книг в списке "Читать позже" в виде массива.
- В браузере я просматриваю массив и обновляю показания для каждой книги в зависимости от того, существует она в массиве или нет.
Pro: Я делаю только один запрос и обновляю индикатор сразу для всех книг.
Против: в списке "Читать позже" могут быть сотни книг, и передача большого массива может оказаться медленной и чрезмерной. Особенно в сценариях, когда на экране появляется не 30 книг, а только 2-3. (То есть я хочу проверить, есть ли определенная книга в списке, и для этого у меня есть сервер, который отправляет клиенту весь список книг из списка).
Так,
Каким путем вы бы пошли, чтобы максимизировать производительность: 1 или 2?
Есть ли какая-то альтернатива, которую мне не хватает
4 ответа
Вариант 1 звучит хорошо, но имеет большие проблемы с точки зрения масштабируемости.
Вариант 2 смягчает эту проблему масштабируемости, и мы можем улучшить его дизайн:
Клиентская сторона, используя javascript, собирает только отображаемые идентификаторы книг и запрашивает один раз, через ajax, массив информации для чтения позже, только для этих 30 книг. Таким образом, вы по-прежнему быстро обслуживаете страницу и запрашиваете небольшой набор дополнительной информации, один раз с помощью одного http-запроса.
На стороне сервера вы можете улучшить кэширование массива в памяти идентификаторов для чтения для каждого пользователя.
Я думаю, что в 2017 году решение заключается не столько в общей производительности, сколько в пользовательском опыте и ожиданиях пользователей.
И в настоящее время пользователь не терпит задержек. В этом смысле сложные пользовательские интерфейсы стараются реагировать как можно быстрее. Таким образом: если вы можете использовать эти небольшие запросы, чтобы позволить пользователю что-то сделать (вместо ожидания двух секунд для возврата этого большого запроса), вы должны предпочесть это решение.
Насколько мне известно, существует много сайтов с "высокой точностью", если бы одна страница могла послать 50, 100 запросов... Так что я бы рассмотрел эту обычную практику.
И, может быть, это будет полезно здесь: в подкасте 277 se-radio.net эта тема интенсивно обсуждается в контексте задержки в хвосте.
Живое тестирование, решения и реальные данные
Этот ответ написан на JavaScript и включает простые для понимания примеры кода.
Введение
ОП спросил, каков наиболее эффективный способ отправки запросов к API «Читать позже», каждый запрос требует ожидания некоторого времени, пока серверная часть сохраняет книгу.
Для этого ответа я создал демонстрацию конечной точки API «Читать позже» , каждый запрос ожидает случайным образом от 70 до 130 миллисекунд для сохранения каждой книги.
Я тестирую во всех сценариях 30 книг каждый раз.
Наконец, мы увидим наилучшие результаты для каждого метода, измеряя профессионально реальное время выполнения каждого действия, которое мы предпримем.
Синхронные запросы (вариант 1 OP)
Здесь мы будем запускать каждый вызов через JS, один за другим, синхронно.
Код:
async function saveBooksSync() {
console.time('save-books-sync');
// creates 30 book IDs
const booksIds = Array.from({length: 30}, (_, i) => i + 1);
// creates 30 API links for each request
const urls = booksIds.map(bookId => `http://localhost:7777/books/read-later?bookId=${bookId}`);
for(let url of urls) {
const response = await fetch(url);
const json = await response.json();
console.log(json);
}
console.timeEnd('save-books-sync');
}
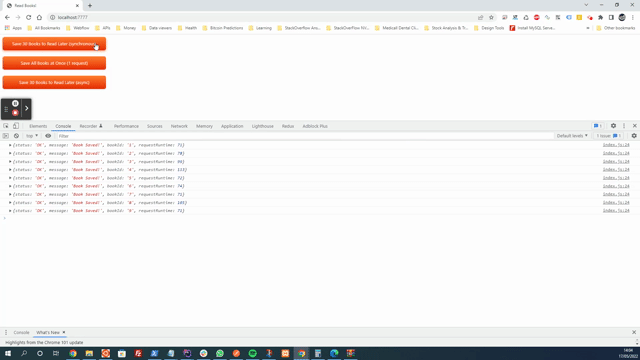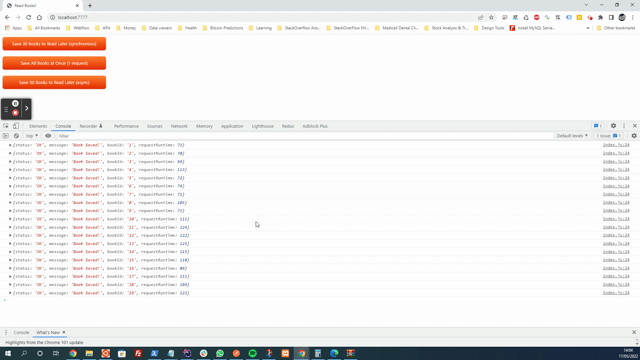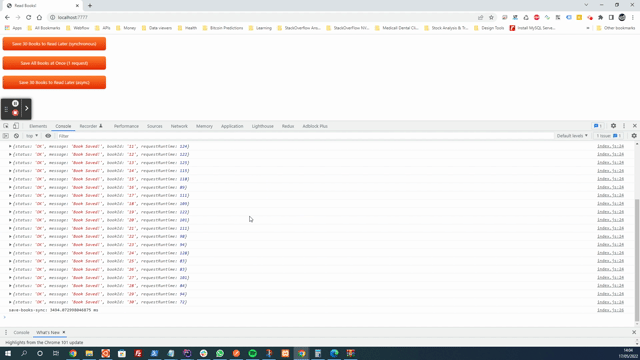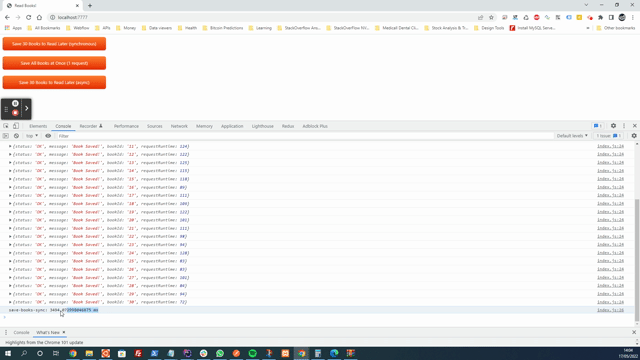
Время выполнения: 3712,40087890625 мс
Одна большая просьба
Хотя мы не будем создавать многозапросное соединение с сервером, среда выполнения говорит сама за себя.
Код:
async function saveAllBooksAtOnce() {
console.time('save-all-books')
const booksIds = Array.from({length: 30}, (_, i) => i + 1);
const url = `http://localhost:7777/books/read-later?all=1`;
const response = await fetch(url);
const json = await response.json();
console.timeEnd('save-all-books');
}
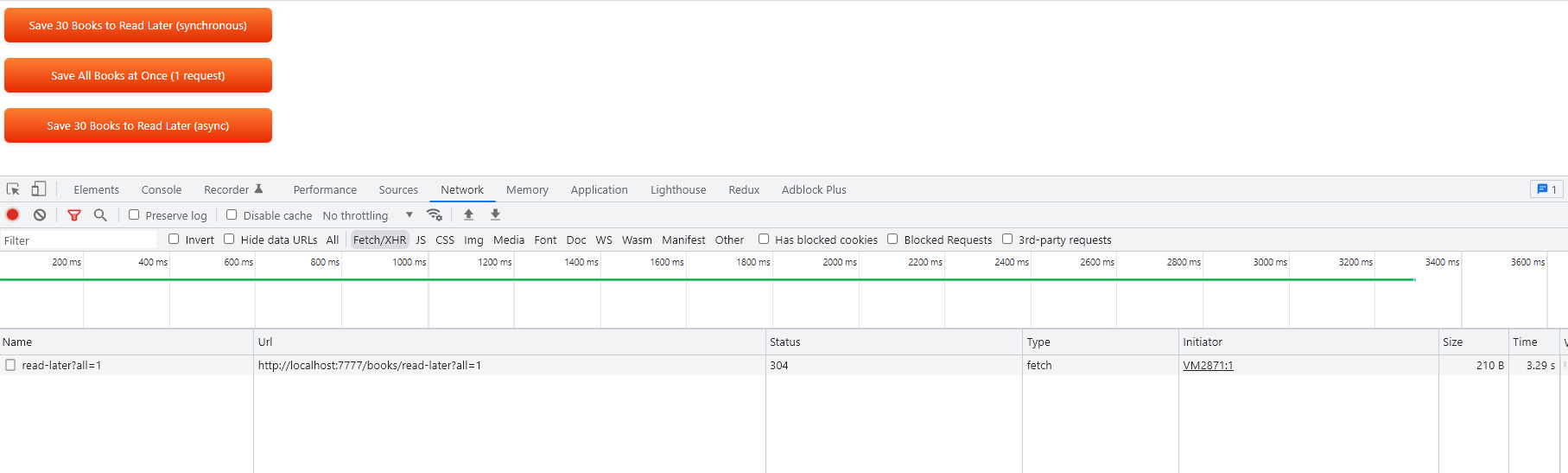
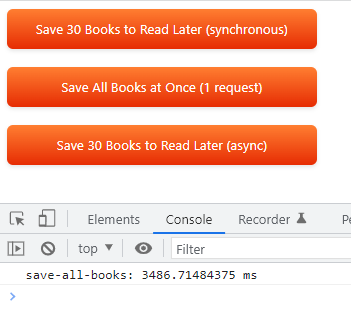
Время выполнения: 3486,71484375 мс
Параллельные асинхронные запросы (решение)
Здесь происходит волшебство, решение вопроса, какой самый эффективный метод запроса.
Здесь мы делаем 30 параллельных небольших запросов с потрясающими результатами.
Код:
async function saveBooksParallel() {
console.time('save-books')
const booksIds = Array.from({length: 30}, (_, i) => i + 1);
const urls = booksIds.map(bookId => `http://localhost:7777/books/read-later?bookId=${bookId}`);
const promises = urls.map((url) =>
fetch(url).then((response) => response.json())
);
const data = await Promise.all(promises);
console.log(data);
console.timeEnd('save-books');
}
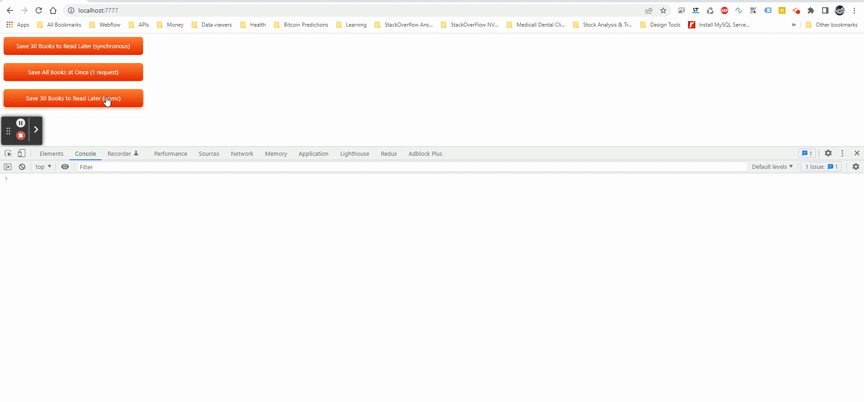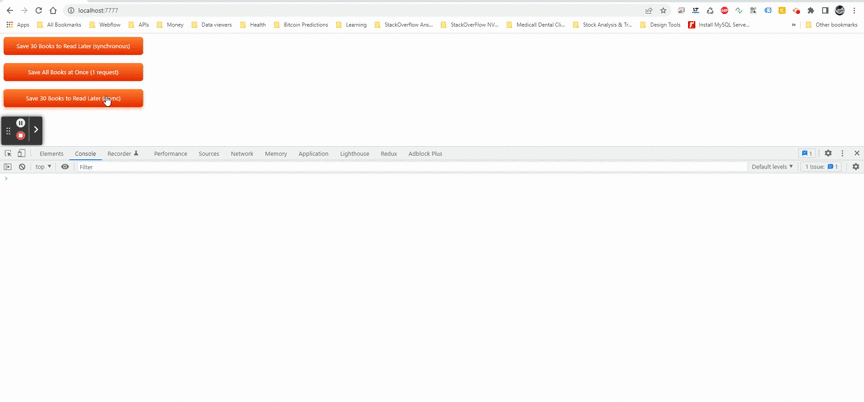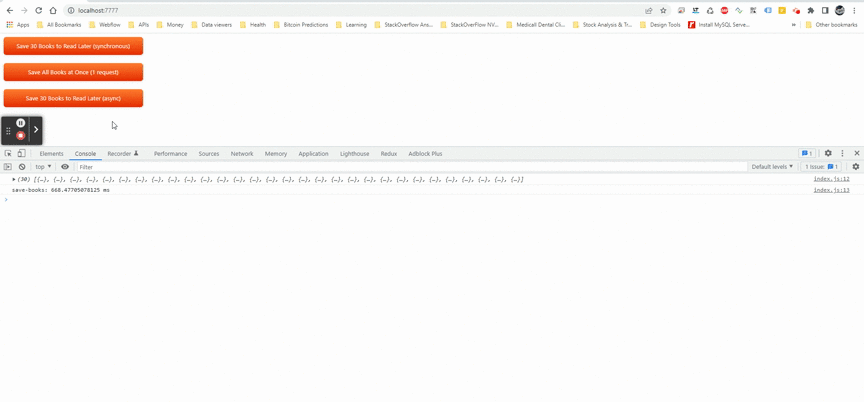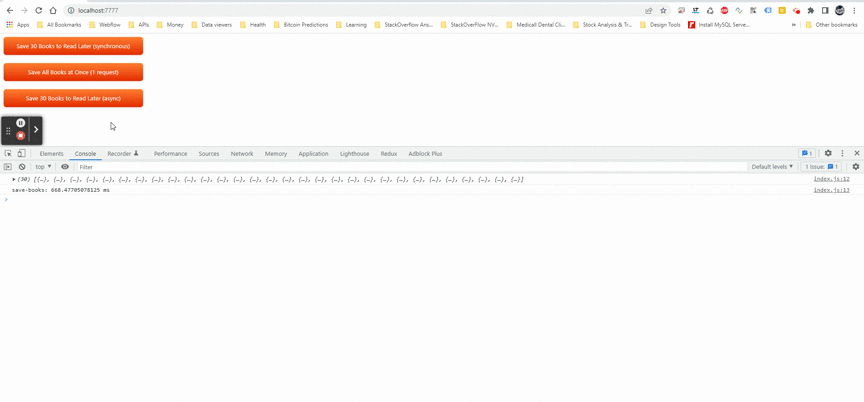
Здесь, в этом асинхронном параллельном примере, я использовалPromise.allметод.
Метод Promise.all() принимает итерацию обещаний в качестве входных данных и возвращает одно обещание, которое разрешается в массив результатов входных обещаний.
Время выполнения: 668,47705078125 мс
Вывод
Результаты говорят сами за себя, самый эффективный способ сделать несколько запросов — сделать это параллельно.
На мой взгляд, это зависит от того, как хранятся данные. Если используется реляционная база данных, вы можете легко добавить логический флаг в список книг, просто выполнив объединение соответствующих таблиц. Скорее всего, это даст вам лучшие результаты, и вам не придется писать какие-либо алгоритмы во внешнем интерфейсе.