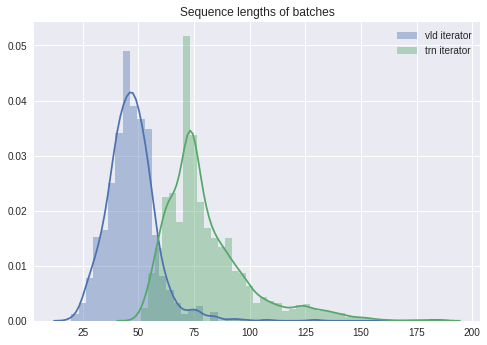
BucketIterator.splits выдает итераторы различной длины последовательности
Я использовал BucketIterator.splits создать итераторы для обучения и проверки набора. Я получил два итератора с очень разным распределением длин последовательностей. Я ожидаю, что расколы будут более симметричными. Я что-то пропустил?
Импорт и случайное разделение набора данных
TEXT = Field(sequential=True, lower=True)
dataset = TabularDataset(....with tree text fields BODY, TITLE)
TEXT.build_vocab(dataset)
trn, vld = dataset.split(split_ratio=0.5)
Создать итераторы
trn_iter, vld_iter = BucketIterator.splits(
(trn, vld), batch_sizes=(64, 64),
sort_key=lambda x: len(x.BODY) + len(x.TITLE),
repeat=False
)
Длина последовательности пакетов итераторов очень различна
vld_iter_seqlen = np.array([x.BODY.size(0) + x.TITLE.size(0) for x in vld_iter])
trn_iter_seqlen = np.array([x.BODY.size(0) + x.TITLE.size(0) for x in trn_iter])