Как записать несколько фреймов данных на один лист, не дублируя метки столбцов
У меня есть два вопроса относительно записи данных фрейма в файл:
Моя программа генерирует сводную статистику по многим сгруппированным строкам кадра данных и сохраняет их в буфере StringIO, который записывает в мой файл output.csv по завершении. У меня такое чувство, что pd.concat будет лучше подходить, но я не могу заставить это работать. Я могу попытаться добавить фрагмент кода, когда у меня появится возможность, и, надеюсь, кто-то может объяснить, как правильно выполнить конкататацию, и я предполагаю, что это решит мою проблему.
При этом моя программа работает, и это больше, чем я могу просить. Что меня беспокоит, так это то, что файл CSV в конечном итоге повторяет одни и те же метки столбцов для каждого итогового статистического фрейма данных, который был записан в буфер, а также в мой CSV-файл. Есть ли способ написать метки столбцов только один раз и избежать нескольких повторяющихся строк меток?
Мой второй вопрос касается записи в Excel, чтобы пропустить ненужную копию и вставить. Как и в моем предыдущем выпуске, это всего лишь небольшое препятствие, но оно все еще вызывает у меня затруднения, так как я хотел бы сделать все правильно. Проблема в том, что я хочу, чтобы все кадры были записаны на одном листе. Во избежание перезаписи одних и тех же данных необходимо использовать буфер для хранения данных до конца. Ни один из документов не показался мне полезным в моей конкретной ситуации. Я разработал обходной путь: xlwt в буфер -> output.write(buffer.getvalue()) -> pd.to_csv(output), а затем повторно импортировал тот же файл через pd.read_csv и, наконец, добавил еще один модуль записи, записывающий кадр данных в Excel. После всей этой работы я закончил просто придерживаться простоты CSV, так как писатель Excel фактически увеличил уродливость дублирующих строк. Любые предложения о том, как лучше справиться с моей проблемой буфера, так как я бы предпочел упростить и контролировать Excel Writer, а не выводить CSV.
Извините за отсутствие кода для контекста. Я устал изо всех сил, чтобы объяснить без этого. При необходимости я могу добавить код, когда получу бесплатный шанс.
1 ответ
Я бы согласился с тем, что объединение фреймов данных, вероятно, является лучшим решением. Вы, вероятно, должны задать вопрос специально для этого с некоторыми примерами кодов / фреймов данных.
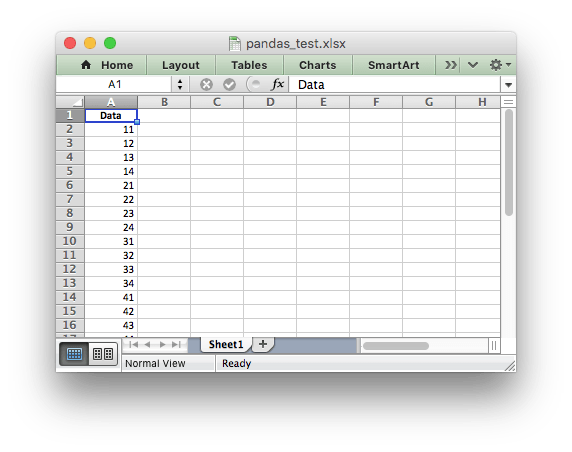
По второму вопросу вы можете поместить фрейм данных на лист Excel, используя startrow а также startcol параметры. Вы можете пропустить повторный заголовок, используя header логический параметр, и вы можете пропустить индекс, используя index логический параметр.
Например:
import pandas as pd
# Create some Pandas dataframes from some data.
df1 = pd.DataFrame({'Data': [11, 12, 13, 14]})
df2 = pd.DataFrame({'Data': [21, 22, 23, 24]})
df3 = pd.DataFrame({'Data': [31, 32, 33, 34]})
df4 = pd.DataFrame({'Data': [41, 42, 43, 44]})
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter('pandas_test.xlsx', engine='xlsxwriter')
# Add the first dataframe to the worksheet.
df1.to_excel(writer, sheet_name='Sheet1', index=False)
offset = len(df1) + 1 # Add extra row for column header.
# Add the other dataframes.
for df in (df2, df3, df4):
# Write the datafram without a column header or index.
df.to_excel(writer, sheet_name='Sheet1', startrow=offset,
header=False, index=False)
offset += len(df)
# Close the Pandas Excel writer and output the Excel file.
writer.save()
Выход: