Как разобрать файл DOT в Python
У меня есть преобразователь, сохраненный в виде файла DOT. Я могу видеть графическое представление графиков с помощью gvedit, но что если я захочу преобразовать файл DOT в исполняемый преобразователь, чтобы я мог проверить преобразователь и посмотреть, какие строки он принимает, а какие нет.
В большинстве инструментов, которые я видел в Openfst, Graphviz и их расширениях Python, файлы DOT используются только для создания графического представления, но что, если я хочу проанализировать файл, чтобы получить интерактивную программу, в которой я могу проверить строки преобразователь?
Существуют ли какие-либо библиотеки, которые могли бы выполнить задачу, или мне просто написать это с нуля?
Как я уже сказал, файл DOT связан с разработанным мной датчиком, который имитирует морфологию английского языка. Это огромный файл, но просто чтобы дать вам представление о том, как он выглядит, я приведу образец. Допустим, я хочу создать преобразователь, который бы моделировал поведение английского языка по отношению к существительным и с точки зрения множественности. Мой лексикон состоит всего из трех слов (книга, мальчик, девочка). Мой преобразователь в этом случае будет выглядеть примерно так:
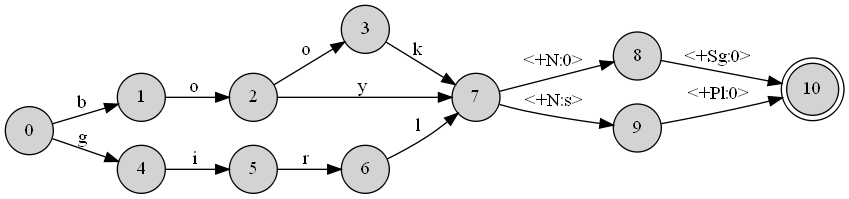
который непосредственно построен из этого файла DOT:
digraph A {
rankdir = LR;
node [shape=circle,style=filled] 0
node [shape=circle,style=filled] 1
node [shape=circle,style=filled] 2
node [shape=circle,style=filled] 3
node [shape=circle,style=filled] 4
node [shape=circle,style=filled] 5
node [shape=circle,style=filled] 6
node [shape=circle,style=filled] 7
node [shape=circle,style=filled] 8
node [shape=circle,style=filled] 9
node [shape=doublecircle,style=filled] 10
0 -> 4 [label="g "];
0 -> 1 [label="b "];
1 -> 2 [label="o "];
2 -> 7 [label="y "];
2 -> 3 [label="o "];
3 -> 7 [label="k "];
4 -> 5 [label="i "];
5 -> 6 [label="r "];
6 -> 7 [label="l "];
7 -> 9 [label="<+N:s> "];
7 -> 8 [label="<+N:0> "];
8 -> 10 [label="<+Sg:0> "];
9 -> 10 [label="<+Pl:0> "];
}
Теперь проверка этого преобразователя на слова означает, что если вы кормите его book+Pl это должно плевать books и наоборот. Я хотел бы увидеть, как можно превратить файл точек в формат, который позволил бы такой анализ и тестирование.
2 ответа
Прежде всего я установил библиотеку graphviz. Затем я написал следующий код:
import os
from graphviz import Source
file = open('graph4.dot', 'r')#READING DOT FILE
text=file.read()
Source(text)
Вы можете начать с загрузки файла, используя https://code.google.com/p/pydot/. Оттуда должно быть относительно просто написать код для обхода графа в памяти согласно входной строке.
Используйте это, чтобы загрузить файл.dot в python:
graph = pydot.graph_from_dot_file(apath)
# SHOW as an image
import tempfile, Image
fout = tempfile.NamedTemporaryFile(suffix=".png")
graph.write(fout.name,format="png")
Image.open(fout.name).show()
Другой путь и простой способ найти циклы в dot файл:
import pygraphviz as pgv
import networkx as nx
gv = pgv.AGraph('my.dot', strict=False, directed=True)
G = nx.DiGraph(gv)
cycles = nx.simple_cycles(G)
for cycle in cycles:
print(cycle)
Ответа Гийома достаточно, чтобы отобразить граф в Spyder (3.3.2), что может решить некоторые проблемы.
Если вам действительно нужно манипулировать графиком, как это требуется для ОП, это будет немного сложно. Частично проблема заключается в том, что Graphviz - это библиотека рендеринга графиков, когда вы пытаетесь проанализировать график. То, что вы пытаетесь сделать, аналогично обратному проектированию документа Word или LateX из файла PDF.
Если вы можете предположить хорошую структуру примера OP, то регулярные выражения работают. Мне нравится афоризм: если вы решаете проблему с помощью регулярных выражений, у вас есть две проблемы. Тем не менее, это может быть просто наиболее практичным решением для этих случаев.
Вот выражения для захвата:
- Информация о вашем узле:
r"node.*?=(\w+).*?\s(\d+)", Группы захвата - это вид и метка узла. - Ваша информация о крае:
r"(\d+).*?(\d+).*?\"(.+?)\s", Группами захвата являются источник, приемник и метка края.
Чтобы попробовать их легко, смотрите https://regex101.com/r/3UKKwV/1/ и https://regex101.com/r/Hgctkp/2/.