Политический заговор MDP для Лабиринта
У меня есть лабиринт 5х-5, указанный следующим образом.
r = [1 0 1 1 1
1 1 1 0 1
0 1 0 0 1
1 1 1 0 1
1 0 1 0 1];
Где 1 - пути, а 0 - стены.
Предположим, у меня есть функция foo (policy_vector, r), которая отображает элементы вектора политики на элементы в r. Например, 1= ВВЕРХ, 2= Вправо, 3= Вниз, 4= Влево. MDP настроен так, что состояния стены никогда не реализуются, поэтому политика для этих государств игнорируется в сюжете.
policy_vector' = [3 2 2 2 3 2 2 1 2 3 1 1 1 2 3 2 1 4 2 3 1 1 1 2 2]
symbols' = [v > > > v > > ^ > v ^ ^ ^ > v > ^ < > v ^ ^ ^ > >]
Я пытаюсь показать свое политическое решение для Марковского процесса принятия решений в контексте решения лабиринта. Как бы я нарисовал что-то похожее на это? Matlab предпочтительнее, но Python в порядке.
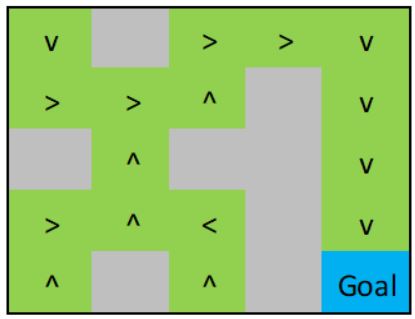
Даже если бы какое-то тело могло показать мне, как составить подобный сюжет, я смог бы понять это оттуда.

1 ответ
Решение
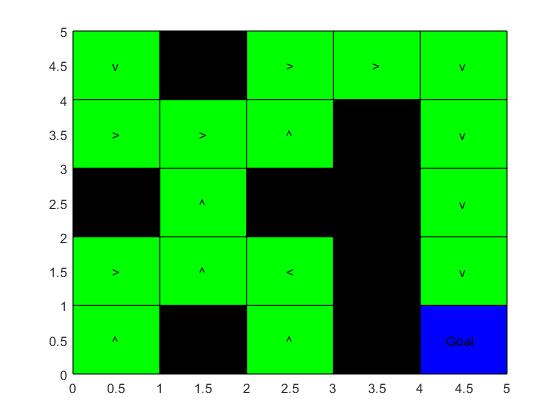
function[] = policy_plot(policy,r)
[row,col] = size(r);
symbols = {'^', '>', 'v', '<'};
policy_symbolic = get_policy_symbols(policy, symbols);
figure()
hold on
axis([0, row, 0, col])
grid on
cnt = 1;
fill([0,0,col,col],[row,0,0,row],'k')
for rr = row:-1:1
for cc = 1:col
if r(row+1 - rr,cc) ~= 0 && ~(row == row+1 - rr && col == cc)
fill([cc-1,cc-1,cc,cc],[rr,rr-1,rr-1,rr],'g')
text(cc - 0.55,rr - 0.5,policy_symbolic{cnt})
end
cnt = cnt + 1;
end
end
fill([cc-1,cc-1,cc,cc],[rr,rr-1,rr-1,rr],'b')
text(cc - 0.70,rr - 0.5,'Goal')
function [policy_symbolic] = get_policy_symbols(policy, symbols)
policy_symbolic = cell(size(policy));
for ii = 1:length(policy)
policy_symbolic{ii} = symbols{policy(ii)};
end