Как найти конкретное поле формы в этом изображении
В Бразилии стандартная форма заполняется (вручную) для каждого новорожденного в больнице. Эта форма называется "DNV" (в переводе с португальского - "Born Alive Декларация"). Существует также форма под названием "DO" (после португальского "Декларация о смерти"). В моем штате больницы отправляют около миллиона таких форм в агентство, где я работаю, где мы вычисляем базу данных под названием "Статистика естественного движения населения". Я расследую, возможно ли автоматизировать работу. Поскольку коммерческие решения ICR стоят больших денег, никто из ответственных не верит, что это может быть сделано внутри, поэтому это проект на низовом уровне.
Верхняя часть формы выглядит так: 
Я заполучил руки в файлы PDF размером 100K, отправленные из нескольких больниц, и смог классифицировать их по одному из двух типов (DNV или DO), используя наивный алгоритм: сначала я определяю черный прямоугольник, который содержит тип документа (используя cv2.findContours и немного эвристики) и применить OCR (pytesseract.image_to_string). Я нашел 20 тыс. "Декларация о смерти" (DO) и 80 тыс. "Декларация о рождении живым".
Используя аналогичный алгоритм, я смог распознать число справа от черного прямоугольника и связать 55k изображений формы с соответствующей записью в базе данных, заполненной профессиональными машинистками на основе этих документов.
Теперь я хочу найти поле даты (красного цвета), чтобы попробовать немного машинного обучения для распознавания цифр - поле выделено ниже: 
Сначала я попробовал алгоритм "сопоставления с шаблоном", используя это как шаблон: 
Это работает хорошо, но только если шаблон и изображение формы имеют одинаковый масштаб и угол. cv2.matchTemplate Метод действительно чувствителен к масштабу. Я пробовал алгоритмы сопоставления функций с использованием SURF, но мне трудно заставить его работать (кажется, что это излишнее).
Так как черный прямоугольник легко найти слева, я думаю о некоторых вариантах, чтобы найти цифры:
нормализуя масштаб и угол на основе черного прямоугольника и пытаясь
cv2.matchTemplate,пытаясь найти контур, упростить его с помощью
cv2.approxPolyDPи угадать расположение цифр.
Мой вопрос: какой-нибудь совет о том, как атаковать проблему? Какой другой алгоритм я могу использовать, чтобы найти это поле формы, если входные данные не нормированы с точки зрения разрешения / угла?
[обновление #1]
Учитывая (x, y, w, h) как положение и размер черного прямоугольника слева, я могу сузить поиск с достаточной уверенностью. 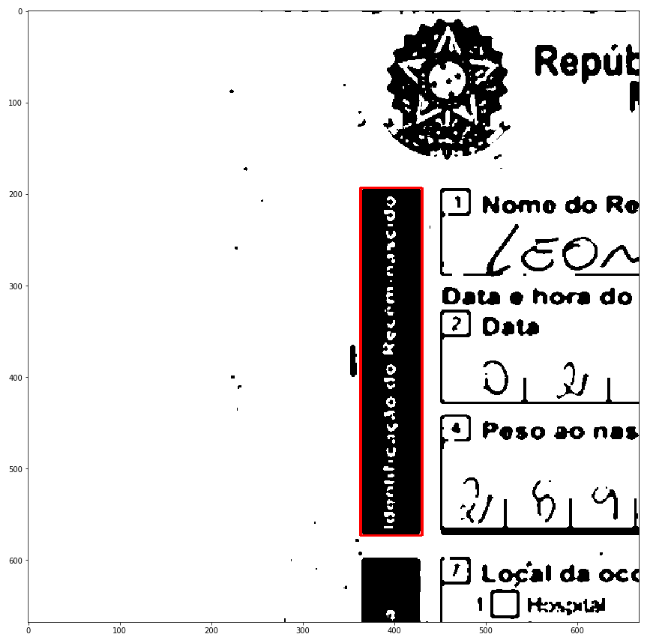
Используя случайные выборки, эта формула дает мне:
img.crop((x+w, y+h/3, x+h*3.05, y+2*h/3))
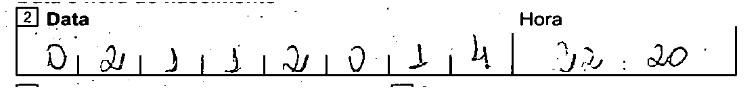
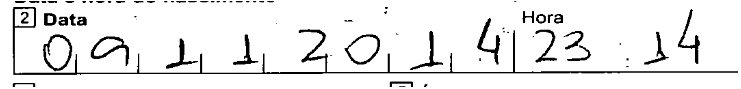
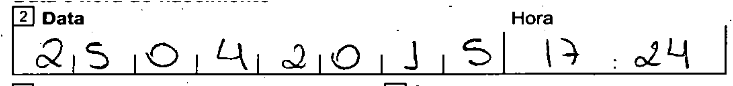
[обновление № 2]
Я только что узнал о erode а также dilateТеперь они мои новые лучшие друзья.
horizontal = edges.copy()
vertical = edges.copy()
kv = np.ones((25, 1), np.uint8)
kh = np.ones((1, 30), np.uint8)
horizontal = cv2.dilate(cv2.erode(horizontal, kh, iterations=2), kh, iterations=2)
vertical = cv2.dilate(cv2.erode(vertical, kv, iterations=2), kv, iterations=2)
grid = horizontal | vertical
plt.imshow(edges, 'gray')

plt.imshow(grid, 'gray')

Кстати, я понятия не имею о компьютерном зрении. Вернемся к Google...
1 ответ
Попробуйте найти поля углов, вычислить угол / масштаб и затем просто преобразовать изображение в нормализованное изображение.