Itextsharp не может извлекать содержимое PDF в формате Unicode в C#
Я пытаюсь получить содержимое PDF-файла, используя itextsharp как вы видете:
static void Main(string[] args)
{
StringBuilder text = new StringBuilder();
using (PdfReader reader = new PdfReader(@"D:\a.pdf"))
{
for (int i = 1; i <= reader.NumberOfPages; i++)
{
text.Append(PdfTextExtractor.GetTextFromPage(reader, i));
}
}
System.IO.File.WriteAllText(@"c:/a.txt",text.ToString());
Console.ReadLine();
}
Мой pdf контент написан на Persian и после запуска приведенного выше кода результат выглядит так:
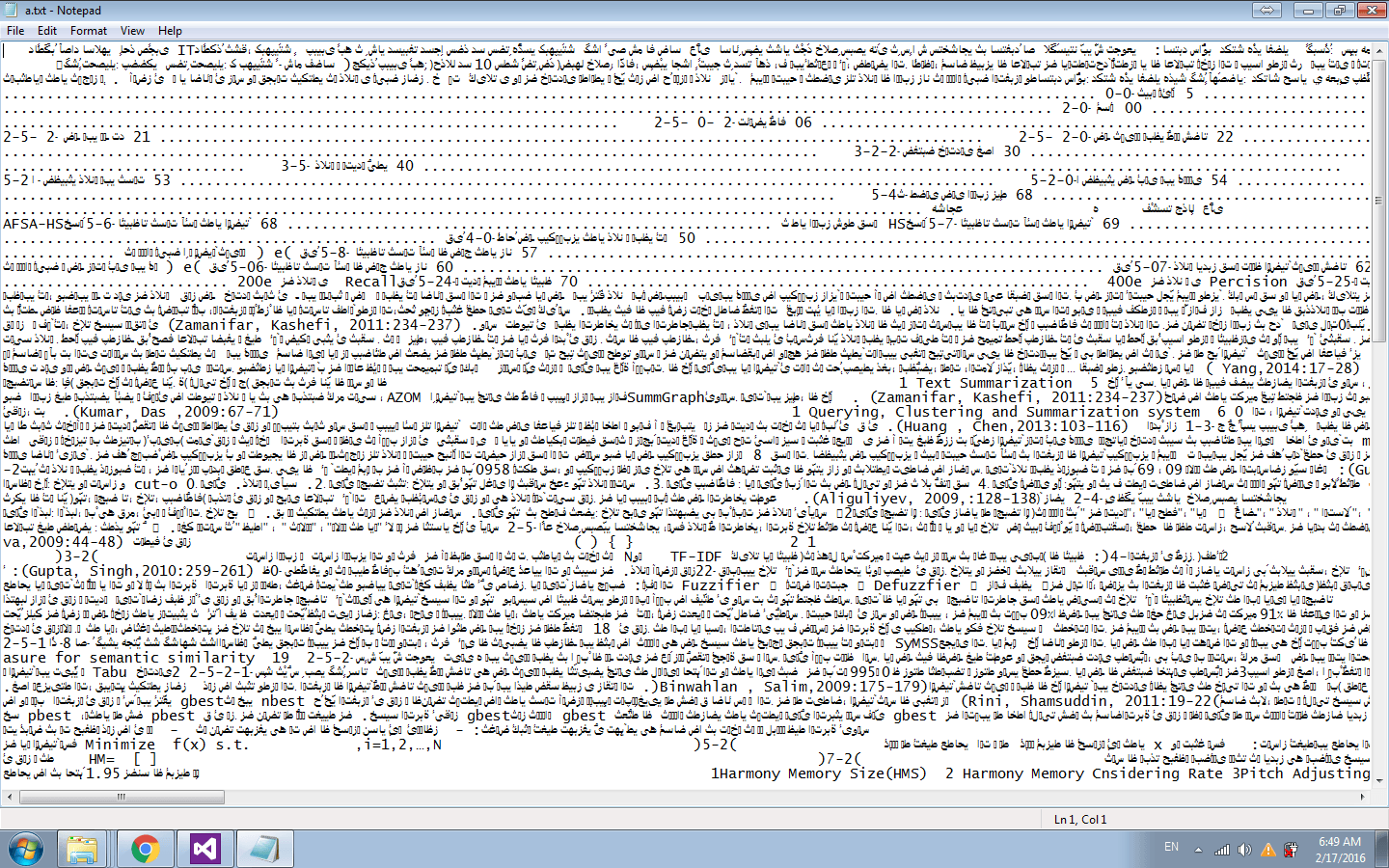
Но это не правильный результат. Должен ли я установить любую опцию в itextsharp
1 ответ
Трудно сказать без оригинального файла, но если у вас неправильно введены символы / слова, вы должны попытаться использовать LocationTextExtractionStrategy как это:
text.Append(PdfTextExtractor.GetTextFromPage(reader, i, new LocationTextExtractionStrategy());