Насколько важен порядок столбцов в индексах?
Я слышал, что вы должны поместить столбцы, которые будут наиболее избирательными в начале объявления индекса. Пример:
CREATE NONCLUSTERED INDEX MyINDX on Table1
(
MostSelective,
SecondMost,
Least
)
Прежде всего, то, что я говорю, правильно? Если это так, могу ли я увидеть большие различия в производительности, изменив порядок столбцов в моем индексе, или это более полезная практика?
Причина, по которой я спрашиваю, заключается в том, что после помещения запроса через DTA рекомендуется создать индекс, в котором почти все столбцы совпадают с существующим индексом, но в другом порядке. Я думал просто добавить отсутствующие столбцы в существующий индекс и назвать его хорошим. Мысли?
5 ответов
Посмотрите на индекс как это:
Cols
1 2 3
-------------
| | 1 | |
| A |---| |
| | 2 | |
|---|---| |
| | | |
| | 1 | 9 |
| B | | |
| |---| |
| | 2 | |
| |---| |
| | 3 | |
|---|---| |
Посмотрите, как ограничивается первый, так как ваш первый столбец исключает больше результатов, чем первый второй столбец? Проще представить, как должен проходить индекс, столбец 1, затем столбец 2 и т. Д.... вы видите, что отсечение большинства результатов на первом этапе делает 2-й шаг намного быстрее.
В другом случае, если вы запросите в столбце 3, оптимизатор даже не будет использовать индекс, потому что он вообще не помогает сузить наборы результатов. В любое время, когда вы выполняете запрос, сужение количества результатов, которые необходимо обработать до следующего шага, означает повышение производительности.
Поскольку индекс также хранится таким образом, по индексу нет возврата назад, чтобы найти первый столбец, когда вы запрашиваете его.
Короче говоря: нет, это не для показа, есть реальные преимущества в производительности.
Порядок столбцов является критическим. Теперь, какой порядок правильный, зависит от того, как вы собираетесь запросить его. Индекс может использоваться для точного поиска или сканирования диапазона. Точный поиск - это когда значения для всех столбцов в индексе заданы, и запрос попадает точно в строку, в которой заинтересован. Для запросов порядок столбцов не имеет значения. Сканирование диапазона - это когда указаны только некоторые столбцы, и в этом случае порядок становится важным. SQL Server может использовать индекс для сканирования диапазона только в том случае, если указан крайний левый столбец, и только в том случае, если указан следующий крайний левый столбец и т. Д. Если у вас есть индекс на (A,B,C), его можно использовать для сканирования диапазона A=@a, за A=@a AND B=@b но не для B=@b, за C=@c ниB=@b AND C=@c, Дело A=@a AND C=@c смешанный, как в A=@a часть будет использовать индекс, но C=@c нет (запрос будет сканировать все значения B для A=@a, не будет "пропустить" C=@c). Другие системы баз данных имеют так называемый оператор "пропустить сканирование", который может использовать некоторые преимущества внутренних столбцов в индексе, когда внешние столбцы не указаны.
Обладая этими знаниями, вы можете снова посмотреть определения индекса. Индекс на (MostSelective, SecondMost, Least) будет эффективным только тогда, когда MostSelective столбец указан. Но, будучи наиболее избирательным, релевантность внутренних столбцов будет быстро ухудшаться. Очень часто вы обнаружите, что лучший индекс включен (MostSelective) include (SecondMost, Least) или на (MostSelective, SecondMost) include (Least), Поскольку внутренние столбцы менее релевантны, размещение столбцов с низкой избирательностью в таких правильных позициях в индексе делает их ничем иным, как шумом для поиска, поэтому имеет смысл убрать их с промежуточных страниц и оставить их только на листовых страницах, так как цели обеспечения совместимости запросов. Другими словами, переместите их в ВКЛЮЧИТЬ. Это становится более важным, так как размер Least столбец увеличивается. Идея состоит в том, что этот индекс может принести пользу только тем запросам, которые указывают MostSelective либо как точное значение, либо как диапазон, и этот столбец, являющийся наиболее селективным, уже в значительной степени ограничивает строки-кандидаты.
С другой стороны, индекс на (Least, SecondMost, MostSelective) Может показаться ошибкой, но на самом деле это довольно мощный показатель. Потому что это имеет Least столбец как его внешний запрос, он может использоваться для запросов, которые должны агрегировать результаты по столбцам с низкой избирательностью. Такие запросы распространены в хранилищах данных OLAP и аналитических данных, и именно здесь такие индексы имеют очень хороший пример. Такие индексы на самом деле создают отличные кластеризованные индексы именно потому, что они организуют физическое расположение на больших порциях связанных строк (то же самое Least значение, которое обычно указывает на какую-либо категорию или тип), и они облегчают анализ запросов.
Так что, к сожалению, "правильного" порядка нет. Вы не должны следовать каким-либо рецептам печенья, а вместо этого проанализировать шаблон запроса, который вы собираетесь использовать для этих таблиц, и решить, какой порядок столбцов индекса является правильным.
Как говорит Ремус, это зависит от вашей рабочей нагрузки.
Я хочу обратиться к вводящему в заблуждение аспекту принятого ответа все же.
Для запросов, которые выполняют поиск на равенство по всем столбцам в индексе, нет существенной разницы.
Ниже создаются две таблицы и заполняются их одинаковыми данными. Единственное отличие состоит в том, что один из них имеет ключи, упорядоченные от большинства к наименее избирательным, а другой - наоборот.
CREATE TABLE Table1(MostSelective char(800), SecondMost TINYINT, Least CHAR(1), Filler CHAR(4000) null);
CREATE TABLE Table2(MostSelective char(800), SecondMost TINYINT, Least CHAR(1), Filler CHAR(4000) null);
CREATE NONCLUSTERED INDEX MyINDX on Table1(MostSelective,SecondMost,Least);
CREATE NONCLUSTERED INDEX MyINDX2 on Table2(Least,SecondMost,MostSelective);
INSERT INTO Table1 (MostSelective, SecondMost, Least)
output inserted.* into Table2
SELECT TOP 26 REPLICATE(CHAR(number + 65),800), number/5, '~'
FROM master..spt_values
WHERE type = 'P' AND number >= 0
ORDER BY number;
Теперь делаем запрос к обеим таблицам...
SELECT *
FROM Table1
WHERE MostSelective = REPLICATE('P', 800)
AND SecondMost = 3
AND Least = '~';
SELECT *
FROM Table2
WHERE MostSelective = REPLICATE('P', 800)
AND SecondMost = 3
AND Least = '~';
... Они оба используют индексный штраф и оба имеют одинаковую стоимость.
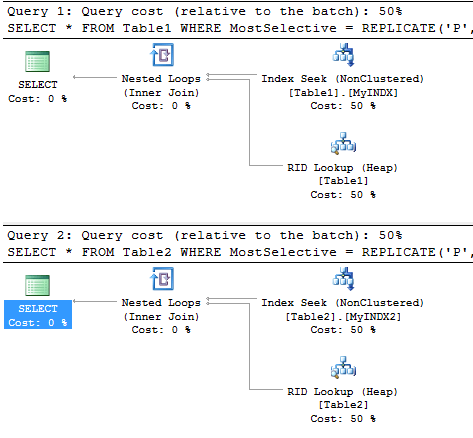
Искусство ASCII в принятом ответе на самом деле не то, как индексы структурированы. Страницы индекса для Таблицы 1 представлены ниже (щелкните изображение, чтобы открыть в полном размере).
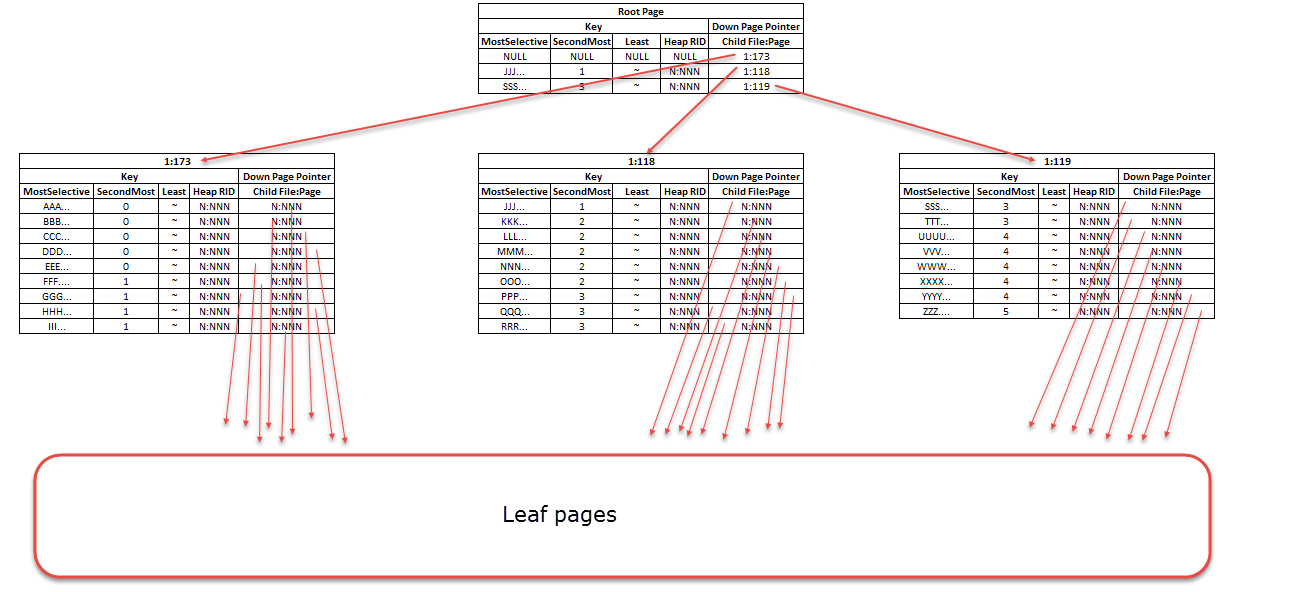
Страницы индекса содержат строки, содержащие весь ключ (в этом случае к идентификатору строки добавлен дополнительный столбец ключа, поскольку индекс не был объявлен как уникальный, но его можно не учитывать, дополнительную информацию об этом можно найти здесь).
Для вышеприведенного запроса SQL Server не заботится о селективности столбцов. Он выполняет бинарный поиск по корневой странице и обнаруживает, что ключ (PPP...,3,~ ) является >=(JJJ...,1,~ ) а также < (SSS...,3,~ ) так что следует прочитать страницу 1:118, Затем он выполняет двоичный поиск ключевых записей на этой странице и находит страницу листа, чтобы перейти вниз.
Изменение индекса в порядке селективности не влияет ни на ожидаемое количество сравнений ключей из бинарного поиска, ни на количество страниц, по которым нужно переходить, чтобы выполнить поиск по индексу. В лучшем случае это может незначительно ускорить само сравнение ключей.
Иногда, сначала упорядочивая наиболее селективный индекс, будет иметь смысл для других запросов в вашей рабочей нагрузке.
Например, если рабочая нагрузка содержит запросы обеих следующих форм.
SELECT * ... WHERE MostSelective = 'P'
SELECT * ...WHERE Least = '~'
Приведенные выше индексы не охватывают ни один из них. MostSelective достаточно избирателен, чтобы составить план с поиском и поиском, но запрос против Least нет.
Однако этот сценарий (поиск не охватывающего индекса по подмножеству ведущих столбцов (столбцов) составного индекса) является лишь одним из возможных классов запросов, которым может помочь индекс. Если вы никогда не осуществляете поиск по MostSelective сам по себе или сочетание MostSelective, SecondMost и всегда ищите по комбинации всех трех столбцов, тогда это теоретическое преимущество для вас бесполезно.
Наоборот запросы, такие как
SELECT MostSelective,
SecondMost,
Least
FROM Table2
WHERE Least = '~'
ORDER BY SecondMost,
MostSelective
Помогло бы наличие обратного порядка обычно прописанного - поскольку он покрывает запрос, может поддерживать поиск и возвращает строки в желаемом порядке загрузки.
Так что это часто повторяемый совет, но в большинстве случаев это эвристический анализ потенциальной выгоды для других запросов - и он не заменит фактического просмотра вашей рабочей нагрузки.
Вы должны поместить столбцы, которые будут наиболее избирательными в начале объявления индекса.
Правильный. Индексы могут быть составными - составленными из нескольких столбцов - и порядок важен из-за самого левого принципа. Причина в том, что база данных проверяет список слева направо и должна найти соответствующую ссылку на столбец, соответствующую определенному порядку. Например, наличие индекса для таблицы адресов со столбцами:
- Адрес
- город
- государственный
Любой запрос с использованием address столбец может использовать индекс, но если запрос имеет только city и / или state ссылки - индекс не может быть использован. Это связано с тем, что на самый левый столбец нет ссылок. Производительность запросов должна указывать, какой из них оптимален - отдельные индексы или несколько композитов с разными порядками. Хорошее чтение: переломный момент, Кимберли Трипп
Все ответы неверны.
Избирательность отдельных столбцов в составном индексе не имеет значения при выборе заказа.
Вот простой мыслительный процесс: по сути, индекс - это объединение задействованных столбцов.
Если дать такое обоснование, то единственное различие заключается в сравнении двух "строк", которые отличаются раньше и позже в строке. Это крошечная часть общей стоимости. Не существует "первого прохода / второго прохода", как указано в одном ответе.
Итак, какой порядок следует использовать?
- Начните с колонки, протестированной с
=в любом порядке. - Затем выберите один столбец диапазона.
Например, столбец с очень низкой селективностью должен стоять первым в этом:
WHERE deleted = 0 AND the_datetime > NOW() - INTERVAL 7 DAY
INDEX(deleted, the_datetime)
Обмен порядка в индексе приведет к его полному игнорированию deleted,
(Есть намного больше правил для заказа столбцов.)