Посмотреть оптимизацию в postgresql
Я должен объединить самое последнее "чтение" из каждой таблицы в одном представлении, чтобы оптимизировать доступ к базе данных, но я заметил, что выполнение множества отдельных запросов обходится намного дешевле, чем использование представления, поэтому мне интересно, если что-то не так на мой взгляд или это можно оптимизировать.
Вот несколько таблиц:
CREATE TABLE hives(
id character(20) NOT NULL,
master character(20) DEFAULT NULL::bpchar,
owner integer,
[...]
CONSTRAINT hives_pkey PRIMARY KEY (id),
CONSTRAINT hives_master_extk FOREIGN KEY (master)
REFERENCES hives (id) MATCH SIMPLE
ON UPDATE CASCADE ON DELETE SET NULL,
CONSTRAINT hives_owner_extk FOREIGN KEY (owner)
REFERENCES users (id) MATCH SIMPLE
ON UPDATE CASCADE ON DELETE CASCADE
)
CREATE TABLE dt_rain(
hive character(20) NOT NULL,
hiveconnection integer,
instant timestamp with time zone NOT NULL,
rain integer,
CONSTRAINT dt_rain_pkey PRIMARY KEY (hive, instant),
CONSTRAINT dt_rain_hive_connections_extk FOREIGN KEY (hiveconnection)
REFERENCES hives_connections (id) MATCH SIMPLE
ON UPDATE CASCADE ON DELETE SET NULL,
CONSTRAINT dt_rain_hive_extk FOREIGN KEY (hive)
REFERENCES hives (id) MATCH SIMPLE
ON UPDATE CASCADE ON DELETE CASCADE
)
CREATE TABLE dt_temperature
(
hive character(20) NOT NULL,
hiveconnection integer,
instant timestamp with time zone NOT NULL,
internal integer,
external integer,
CONSTRAINT dt_temperature_pkey PRIMARY KEY (hive, instant),
CONSTRAINT dt_temperature_hive_connections_extk FOREIGN KEY (hiveconnection)
REFERENCES hives_connections (id) MATCH SIMPLE
ON UPDATE CASCADE ON DELETE SET NULL,
CONSTRAINT dt_temperature_hive_extk FOREIGN KEY (hive)
REFERENCES hives (id) MATCH SIMPLE
ON UPDATE CASCADE ON DELETE CASCADE
)
Каждая таблица данных содержит историю всех чтений, они очень большие и имеют один и тот же формат: куст (ключ к таблице ульев), моментальныеданные.
Я заинтересован в получении только последнего значения, так что вот мнение:
CREATE OR REPLACE VIEW dt_last AS
SELECT id AS
hive,
b.instant AS inout_instant, "input", "output", timeout,
c.instant AS temperature_instant, "internal", "external",
d.instant AS weight_instant, weight,
e.instant AS rain_instant, rain,
f.instant AS voltage_instant, operational, panel, cell,
g.instant AS gps_instant, latitude, longitude, altitude
FROM hives
LEFT OUTER JOIN (
SELECT hive, instant, "input", "output", timeout FROM dt_inout_summary x
WHERE x.instant = (
SELECT MAX(x1.instant) FROM dt_inout_summary x1 WHERE x1.hive = x.hive
)
) b ON (id = b.hive)
LEFT OUTER JOIN (
SELECT hive, instant, "internal", "external" FROM dt_temperature x
WHERE x.instant = (
SELECT MAX(x1.instant) FROM dt_temperature x1 WHERE x1.hive = x.hive
)
) c ON (id = c.hive)
LEFT OUTER JOIN (
SELECT hive, instant, weight FROM dt_weight x
WHERE x.instant = (
SELECT MAX(x1.instant) FROM dt_weight x1 WHERE x1.hive = x.hive
)
) d ON (id = d.hive)
LEFT OUTER JOIN (
SELECT hive, instant, rain FROM dt_rain x
WHERE x.instant = (
SELECT MAX(x1.instant) FROM dt_inout_summary x1 WHERE x1.hive = x.hive
)
) e ON (id = e.hive)
LEFT OUTER JOIN (
SELECT hive, instant, operational, panel, cell FROM dt_voltage x
WHERE x.instant = (
SELECT MAX(x1.instant) FROM dt_inout_summary x1 WHERE x1.hive = x.hive
)
) f ON (id = f.hive)
LEFT OUTER JOIN (
SELECT hive, instant, latitude, longitude, altitude FROM dt_gps x
WHERE x.instant = (
SELECT MAX(x1.instant) FROM dt_gps x1 WHERE x1.hive = x.hive
)
) g ON (id = g.hive)
Выбор в этом представлении стоит около 1 секунды на запись, что намного дороже, чем выполнение SELECT * FROM WHERE hive='' ORDER BY instant DESC Limit 1; шесть раз за улей. Я озадачен
Вот графическое представление анализатора запросов с последующим выводом EXPLAIN ANALYZE
Merge Left Join (cost=127051.81..264142.76 rows=37741 width=153) (actual time=8862.466..8862.564 rows=13 loops=1)
Merge Cond: (hives.id = x_1.hive)
-> Nested Loop Left Join (cost=0.29..136523.11 rows=801 width=137) (actual time=4198.324..4198.395 rows=13 loops=1)
Join Filter: (hives.id = x_5.hive)
Rows Removed by Join Filter: 36
-> Nested Loop Left Join (cost=0.29..136505.79 rows=801 width=85) (actual time=4198.300..4198.363 rows=13 loops=1)
Join Filter: (hives.id = x_4.hive)
-> Nested Loop Left Join (cost=0.29..135968.88 rows=801 width=65) (actual time=4198.254..4198.315 rows=13 loops=1)
Join Filter: (hives.id = x_3.hive)
Rows Removed by Join Filter: 12
-> Nested Loop Left Join (cost=0.29..135407.01 rows=801 width=53) (actual time=4198.171..4198.227 rows=13 loops=1)
Join Filter: (hives.id = x.hive)
Rows Removed by Join Filter: 108
-> Nested Loop Left Join (cost=0.29..345.31 rows=17 width=33) (actual time=0.011..0.049 rows=13 loops=1)
-> Index Only Scan using hives_pkey on hives (cost=0.14..12.39 rows=17 width=21) (actual time=0.005..0.011 rows=13 loops=1)
Heap Fetches: 13
-> Index Scan using dt_weight_pkey on dt_weight x_2 (cost=0.15..19.57 rows=1 width=96) (actual time=0.002..0.002 rows=0 loops=13)
Index Cond: (hives.id = hive)
Filter: (instant = (SubPlan 6))
SubPlan 6
-> Result (cost=5.50..5.51 rows=1 width=0) (actual time=0.009..0.009 rows=1 loops=1)
InitPlan 5 (returns $5)
-> Limit (cost=0.15..5.50 rows=1 width=8) (actual time=0.007..0.007 rows=1 loops=1)
-> Index Only Scan Backward using dt_weight_pkey on dt_weight x1_2 (cost=0.15..16.21 rows=3 width=8) (actual time=0.003..0.003 rows=1 loops=1)
Index Cond: ((hive = x_2.hive) AND (instant IS NOT NULL))
Heap Fetches: 1
-> Materialize (cost=0.00..134859.45 rows=801 width=41) (actual time=198.865..322.935 rows=9 loops=13)
-> Seq Scan on dt_inout_summary x (cost=0.00..134855.44 rows=801 width=41) (actual time=2585.238..4198.146 rows=9 loops=1)
Filter: (instant = (SubPlan 2))
Rows Removed by Filter: 160099
SubPlan 2
-> Result (cost=0.81..0.82 rows=1 width=0) (actual time=0.026..0.026 rows=1 loops=160108)
InitPlan 1 (returns $1)
-> Limit (cost=0.42..0.81 rows=1 width=8) (actual time=0.025..0.025 rows=1 loops=160108)
-> Index Only Scan Backward using test on dt_inout_summary x1 (cost=0.42..6929.02 rows=17790 width=8) (actual time=0.025..0.025 rows=1 loops=160108)
Index Cond: ((hive = x.hive) AND (instant IS NOT NULL))
Heap Fetches: 160108
-> Materialize (cost=0.00..525.83 rows=3 width=96) (actual time=0.006..0.006 rows=1 loops=13)
-> Seq Scan on dt_rain x_3 (cost=0.00..525.82 rows=3 width=96) (actual time=0.076..0.076 rows=1 loops=1)
Filter: (instant = (SubPlan 8))
Rows Removed by Filter: 2
SubPlan 8
-> Result (cost=0.81..0.82 rows=1 width=0) (actual time=0.023..0.023 rows=1 loops=3)
InitPlan 7 (returns $7)
-> Limit (cost=0.42..0.81 rows=1 width=8) (actual time=0.023..0.023 rows=1 loops=3)
-> Index Only Scan Backward using test on dt_inout_summary x1_3 (cost=0.42..6929.02 rows=17790 width=8) (actual time=0.022..0.022 rows=1 loops=3)
Index Cond: ((hive = x_3.hive) AND (instant IS NOT NULL))
Heap Fetches: 3
-> Materialize (cost=0.00..500.88 rows=3 width=104) (actual time=0.004..0.004 rows=0 loops=13)
-> Seq Scan on dt_voltage x_4 (cost=0.00..500.86 rows=3 width=104) (actual time=0.045..0.045 rows=0 loops=1)
Filter: (instant = (SubPlan 10))
Rows Removed by Filter: 2
SubPlan 10
-> Result (cost=0.81..0.82 rows=1 width=0) (actual time=0.021..0.021 rows=1 loops=2)
InitPlan 9 (returns $9)
-> Limit (cost=0.42..0.81 rows=1 width=8) (actual time=0.020..0.020 rows=1 loops=2)
-> Index Only Scan Backward using test on dt_inout_summary x1_4 (cost=0.42..6929.02 rows=17790 width=8) (actual time=0.019..0.019 rows=1 loops=2)
Index Cond: ((hive = x_4.hive) AND (instant IS NOT NULL))
Heap Fetches: 2
-> Materialize (cost=0.00..5.30 rows=1 width=136) (actual time=0.001..0.002 rows=3 loops=13)
-> Seq Scan on dt_gps x_5 (cost=0.00..5.30 rows=1 width=136) (actual time=0.009..0.018 rows=3 loops=1)
Filter: (instant = (SubPlan 11))
Rows Removed by Filter: 3
SubPlan 11
-> Aggregate (cost=1.05..1.06 rows=1 width=8) (actual time=0.002..0.002 rows=1 loops=6)
-> Seq Scan on dt_gps x1_5 (cost=0.00..1.05 rows=1 width=8) (actual time=0.001..0.001 rows=3 loops=6)
Filter: (hive = x_5.hive)
Rows Removed by Filter: 3
-> Sort (cost=127051.53..127053.53 rows=801 width=37) (actual time=4664.139..4664.139 rows=9 loops=1)
Sort Key: x_1.hive
Sort Method: quicksort Memory: 25kB
-> Seq Scan on dt_temperature x_1 (cost=0.00..127012.90 rows=801 width=37) (actual time=2859.376..4664.118 rows=9 loops=1)
Filter: (instant = (SubPlan 4))
Rows Removed by Filter: 160098
SubPlan 4
-> Result (cost=0.76..0.77 rows=1 width=0) (actual time=0.029..0.029 rows=1 loops=160107)
InitPlan 3 (returns $3)
-> Limit (cost=0.42..0.76 rows=1 width=8) (actual time=0.028..0.028 rows=1 loops=160107)
-> Index Only Scan Backward using dt_temperature_pkey on dt_temperature x1_1 (cost=0.42..6834.25 rows=20013 width=8) (actual time=0.028..0.028 rows=1 loops=160107)
Index Cond: ((hive = x_1.hive) AND (instant IS NOT NULL))
Heap Fetches: 160107
Total runtime: 8862.684 ms
Есть ли способ каким-либо образом оптимизировать эту точку зрения?
=== РЕДАКТИРОВАТЬ в соответствии с предложением joop, в котором MAX заменено на NOT EXISTS и индексы (hive, Instant Desc)
CREATE OR REPLACE VIEW dt_last4 AS
SELECT hives.id AS hive,
b.instant AS inout_instant,
b.input,
b.output,
b.timeout,
c.instant AS temperature_instant,
c.internal,
c.external,
d.instant AS weight_instant,
d.weight,
e.instant AS rain_instant,
e.rain,
f.instant AS voltage_instant,
f.operational,
f.panel,
f.cell,
g.instant AS gps_instant,
g.latitude,
g.longitude,
g.altitude
FROM hives
LEFT JOIN dt_inout_summary b ON b.hive = hives.id AND NOT (EXISTS ( SELECT 1
FROM dt_inout_summary nx
WHERE nx.hive = b.hive AND nx.instant > b.instant))
LEFT JOIN dt_temperature c ON c.hive = hives.id AND NOT (EXISTS ( SELECT 1
FROM dt_temperature nx
WHERE nx.hive = c.hive AND nx.instant > c.instant))
LEFT JOIN dt_weight d ON d.hive = hives.id AND NOT (EXISTS ( SELECT 1
FROM dt_weight nx
WHERE nx.hive = d.hive AND nx.instant > d.instant))
LEFT JOIN dt_rain e ON e.hive = hives.id AND NOT (EXISTS ( SELECT 1
FROM dt_rain nx
WHERE nx.hive = e.hive AND nx.instant > e.instant))
LEFT JOIN dt_voltage f ON f.hive = hives.id AND NOT (EXISTS ( SELECT 1
FROM dt_voltage nx
WHERE nx.hive = f.hive AND nx.instant > f.instant))
LEFT JOIN dt_gps g ON g.hive = hives.id AND NOT (EXISTS ( SELECT 1
FROM dt_gps nx
WHERE nx.hive = g.hive AND nx.instant > g.instant));
ОБЪЯСНИТЬ АНАЛИЗ: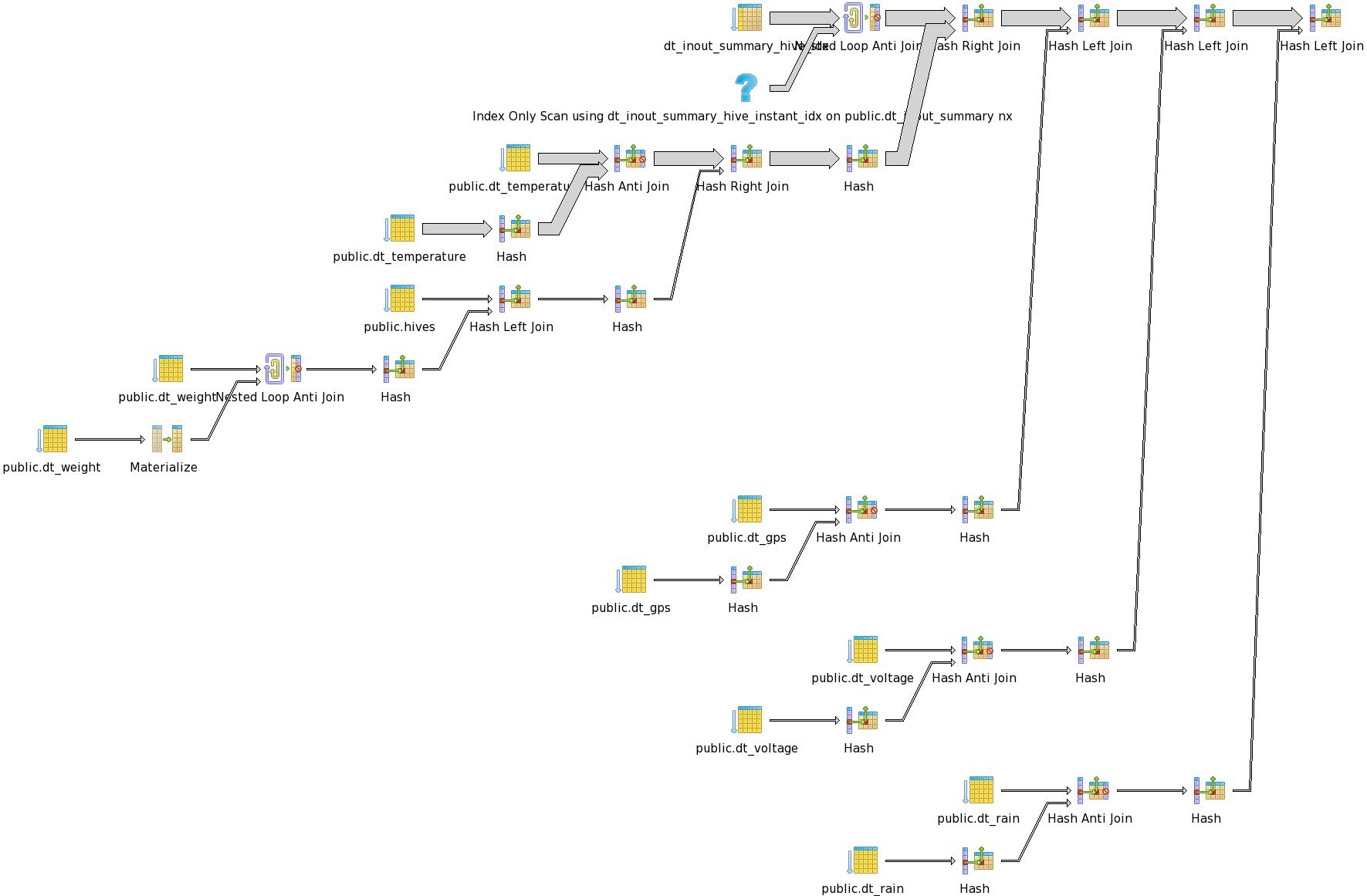
Hash Left Join (cost=18746.60..17942207.21 rows=670182787 width=153) (actual time=771.791..3488.536 rows=13 loops=1)
Hash Cond: (hives.id = e.hive)
-> Hash Left Join (cost=18744.45..14640569.26 rows=670182787 width=141) (actual time=771.776..3488.513 rows=13 loops=1)
Hash Cond: (hives.id = f.hive)
-> Hash Left Join (cost=18742.35..11733156.54 rows=670182787 width=121) (actual time=771.759..3488.486 rows=13 loops=1)
Hash Cond: (hives.id = g.hive)
-> Hash Right Join (cost=18740.04..7643068.10 rows=670182787 width=69) (actual time=771.730..3488.447 rows=13 loops=1)
Hash Cond: (b.hive = hives.id)
-> Nested Loop Anti Join (cost=0.84..81545.46 rows=106739 width=41) (actual time=585.381..3301.662 rows=9 loops=1)
-> Index Scan using dt_inout_summary_hive_idx on dt_inout_summary b (cost=0.42..11549.35 rows=160108 width=41) (actual time=0.012..33.690 rows=160108 loops=1)
-> Index Only Scan using dt_inout_summary_hive_instant_idx on dt_inout_summary nx (cost=0.42..119.09 rows=5930 width=29) (actual time=0.020..0.020 rows=1 loops=160108)
Index Cond: ((hive = b.hive) AND (instant > b.instant))
Heap Fetches: 160099
-> Hash (cost=16361.97..16361.97 rows=106738 width=49) (actual time=186.324..186.324 rows=13 loops=1)
Buckets: 2048 Batches: 16 Memory Usage: 1kB
-> Hash Right Join (cost=6197.92..16361.97 rows=106738 width=49) (actual time=109.280..186.247 rows=13 loops=1)
Hash Cond: (c.hive = hives.id)
-> Hash Anti Join (cost=6194.41..14890.81 rows=106738 width=37) (actual time=109.245..186.196 rows=9 loops=1)
Hash Cond: (c.hive = nx_1.hive)
Join Filter: (nx_1.instant > c.instant)
Rows Removed by Join Filter: 195309
-> Seq Scan on dt_temperature c (cost=0.00..3098.07 rows=160107 width=37) (actual time=0.004..18.177 rows=160107 loops=1)
-> Hash (cost=3098.07..3098.07 rows=160107 width=29) (actual time=48.792..48.792 rows=160107 loops=1)
Buckets: 2048 Batches: 32 (originally 16) Memory Usage: 4175kB
-> Seq Scan on dt_temperature nx_1 (cost=0.00..3098.07 rows=160107 width=29) (actual time=0.002..17.848 rows=160107 loops=1)
-> Hash (cost=3.30..3.30 rows=17 width=33) (actual time=0.029..0.029 rows=13 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Hash Left Join (cost=2.06..3.30 rows=17 width=33) (actual time=0.023..0.028 rows=13 loops=1)
Hash Cond: (hives.id = d.hive)
-> Seq Scan on hives (cost=0.00..1.17 rows=17 width=21) (actual time=0.004..0.006 rows=13 loops=1)
-> Hash (cost=2.04..2.04 rows=1 width=33) (actual time=0.013..0.013 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Nested Loop Anti Join (cost=0.00..2.04 rows=1 width=33) (actual time=0.012..0.012 rows=1 loops=1)
Join Filter: ((nx_2.instant > d.instant) AND (nx_2.hive = d.hive))
Rows Removed by Join Filter: 1
-> Seq Scan on dt_weight d (cost=0.00..1.01 rows=1 width=33) (actual time=0.004..0.004 rows=1 loops=1)
-> Materialize (cost=0.00..1.01 rows=1 width=29) (actual time=0.003..0.003 rows=1 loops=1)
-> Seq Scan on dt_weight nx_2 (cost=0.00..1.01 rows=1 width=29) (actual time=0.002..0.002 rows=1 loops=1)
-> Hash (cost=2.26..2.26 rows=4 width=136) (actual time=0.019..0.019 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Hash Anti Join (cost=1.14..2.26 rows=4 width=136) (actual time=0.015..0.018 rows=3 loops=1)
Hash Cond: (g.hive = nx_5.hive)
Join Filter: (nx_5.instant > g.instant)
Rows Removed by Join Filter: 9
-> Seq Scan on dt_gps g (cost=0.00..1.06 rows=6 width=136) (actual time=0.004..0.004 rows=6 loops=1)
-> Hash (cost=1.06..1.06 rows=6 width=92) (actual time=0.004..0.004 rows=6 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on dt_gps nx_5 (cost=0.00..1.06 rows=6 width=92) (actual time=0.001..0.002 rows=6 loops=1)
-> Hash (cost=2.08..2.08 rows=1 width=104) (actual time=0.014..0.014 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Hash Anti Join (cost=1.04..2.08 rows=1 width=104) (actual time=0.012..0.012 rows=1 loops=1)
Hash Cond: (f.hive = nx_4.hive)
Join Filter: (nx_4.instant > f.instant)
Rows Removed by Join Filter: 2
-> Seq Scan on dt_voltage f (cost=0.00..1.02 rows=2 width=104) (actual time=0.001..0.001 rows=2 loops=1)
-> Hash (cost=1.02..1.02 rows=2 width=92) (actual time=0.002..0.002 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on dt_voltage nx_4 (cost=0.00..1.02 rows=2 width=92) (actual time=0.001..0.001 rows=2 loops=1)
-> Hash (cost=2.13..2.13 rows=2 width=96) (actual time=0.011..0.011 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Hash Anti Join (cost=1.07..2.13 rows=2 width=96) (actual time=0.009..0.010 rows=2 loops=1)
Hash Cond: (e.hive = nx_3.hive)
Join Filter: (nx_3.instant > e.instant)
Rows Removed by Join Filter: 3
-> Seq Scan on dt_rain e (cost=0.00..1.03 rows=3 width=96) (actual time=0.001..0.002 rows=3 loops=1)
-> Hash (cost=1.03..1.03 rows=3 width=92) (actual time=0.002..0.002 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on dt_rain nx_3 (cost=0.00..1.03 rows=3 width=92) (actual time=0.001..0.001 rows=3 loops=1)
Total runtime: 3488.684 ms
Эта четвертая версия намного лучше. Там все еще остается несколько последовательных сканирований. Без них этот взгляд будет состоянием чистого искусства!
1 ответ
Это NOT EXISTS(...) конструкция, которая избегает max() агрегировать в подзапросе. Это выиграет от наличия составного индекса ON dt_inout_summary( hive, instant DESC)
...
FROM hives h
LEFT OUTER JOIN (
SELECT hive, instant, "input", "output", timeout FROM dt_inout_summary x
WHERE NOT EXISTS(
SELECT 1
FROM dt_inout_summary nx
WHERE nx.hive = x.hive
AND nx.instant > x.instant
)
) b ON (h.id = x.hive)
...
Кстати: вам не нужен подзапрос, просто простое соединение слева сделает то же самое:
...
FROM hives h
LEFT JOIN dt_inout_summary x ON x.hive = h.id
AND NOT EXISTS(
SELECT 1
FROM dt_inout_summary nx
WHERE nx.hive = x.hive
AND nx.instant > x.instant
)
...
, но тогда вам придется ссылаться на поля x.yyyyy в основном запросе (... x.hive, x.instant, x."input", x."output", x.timeout)
ОБНОВЛЕНИЕ: Для запроса требуется 13 (1+2*6) записей. Это может привести к отключению оптимизатора. Вы можете попробовать добавить
SET join_collapse_limit = 16;
прежде чем запросить. Другой способ - разделить подзапросы на CTE (CTE не разбиваются оптимизатором), но CTE может быть немного медленнее, чем соответствующие подзапросы:
CREATE OR REPLACE VIEW dt_last4cte AS
WITH cte_b AS (
SELECT *
FROM dt_inout_summary b WHERE NOT EXISTS ( SELECT 1
FROM dt_inout_summary nx
WHERE nx.hive = b.hive AND nx.instant > b.instant)
)
, cte_c AS (
SELECT *
FROM dt_temperature c WHERE NOT EXISTS ( SELECT 1
FROM dt_temperature nx
WHERE nx.hive = c.hive AND nx.instant > c.instant)
)
, cte_d AS (
SELECT *
FROM dt_weight d WHERE NOT EXISTS ( SELECT 1
FROM dt_weight nx WHERE nx.hive = d.hive AND nx.instant > d.instant)
)
, cte_e AS (
SELECT *
FROM dt_rain e WHERE NOT EXISTS ( SELECT 1
FROM dt_rain nx WHERE nx.hive = e.hive AND nx.instant > e.instant)
)
, cte_f AS (
SELECT *
FROM dt_voltage f WHERE NOT EXISTS ( SELECT 1
FROM dt_voltage nx WHERE nx.hive = f.hive AND nx.instant > f.instant)
)
, cte_g AS (
SELECT *
FROM dt_gps g WHERE NOT EXISTS ( SELECT 1
FROM dt_gps nx WHERE nx.hive = g.hive AND nx.instant > g.instant)
)
SELECT h0.id AS hive,
b.instant AS inout_instant,
b.input,
b.output,
b.timeout,
c.instant AS temperature_instant,
c.internal,
c.external,
d.instant AS weight_instant,
d.weight,
e.instant AS rain_instant,
e.rain,
f.instant AS voltage_instant,
f.operational,
f.panel,
f.cell,
g.instant AS gps_instant,
g.latitude,
g.longitude,
g.altitude
FROM hives h0
LEFT JOIN cte_b b ON b.hive = h0.id
LEFT JOIN cte_c c ON c.hive = h0.id
LEFT JOIN cte_d d ON d.hive = h0.id
LEFT JOIN cte_e e ON e.hive = h0.id
LEFT JOIN cte_f f ON f.hive = h0.id
LEFT JOIN cte_g g ON g.hive = h0.id
-- WHERE __aditional__conditions__
;
Если типичное использование представления добавляет дополнительные условия к итоговому итоговому запросу, оптимизатор может выбрать более избирательный план.