Лучший алгоритм синтаксического анализа для передачи лексической структуры?
В рамках более крупного проекта я хочу реализовать машинный переводчик с языка A на язык B. Поскольку нет доступных инструментов, которые автоматически выполняют машинный перевод на этом наборе языков, а доступный корпус языка B довольно мал, я пытаюсь сделать следующее:
1. Получив предложение на языке A, используйте инструмент, чтобы получить его набор языковых тегов PoS (часть речи).
2. Инструмент, который я использую для пометки PoS (Freeling), не возвращает дерево разбора, поэтому я подумал о создании собственного дерева разбора из набора тегов.
3. После того, как дерево разбора завершено, обойдите его по уровням (начиная с корня) и измените порядок его элементов в соответствии с грамматическими правилами языка B.
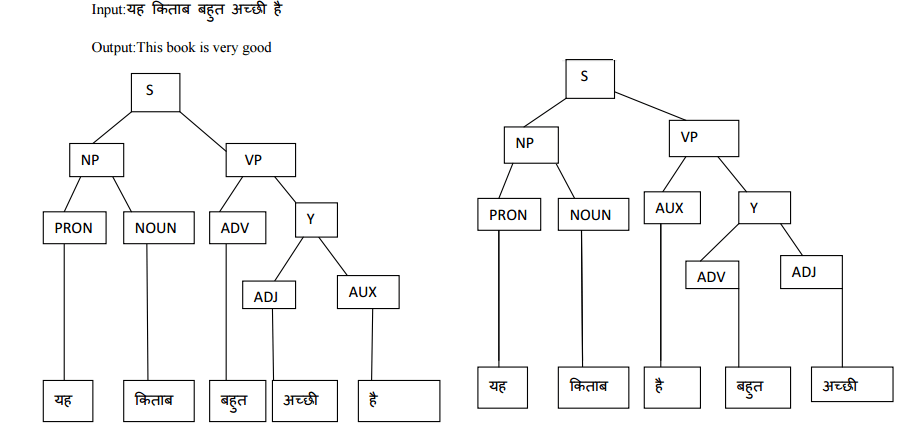
Проведя некоторое исследование, я узнал о парсинге Эрли (чья способность разбирать любой язык привлекла мое внимание, потому что грамматика на языке B со временем может измениться, поэтому я не могу гарантировать, что она всегда будет соответствовать какому-либо конкретному критерию). Тем не менее, учитывая, что моей конечной целью является перенос структуры, я не уверен, что использование восходящего анализатора и попытка изменить порядок элементов при их сопоставлении с правилами дадут мне лучшую производительность или если я на неправильном пути и мое решение совершенно неверно.
2 ответа
В зависимости от исходного языка, с которым вы имеете дело, FreeLing предоставляет дерево разбора (например, для испанского, английского, каталонского, португальского...)
Если синтаксический анализ на вашем языке не поддерживается FreeLing, вы можете добавить его, просто написав грамматику. FreeLing включает в себя синтаксический анализатор CKY, который будет применять вашу грамматику и давать вам дерево разбора.
Таким образом, вы могли бы выполнить шаг 2 "построение моего собственного дерева разбора из набора тегов".
Что касается перевода, я не уверен, что лучшая стратегия - это переупорядочение на лету. Вероятно, лучше иметь целое дерево и выполнять передачу в обратном направлении.
Если ваша цель - перевод на основе правил, вы можете взглянуть на платформу перевода с открытым исходным кодом https://www.apertium.org/
Если вы ищете "лучший" алгоритм для гадания дерева разбора, то вам стоит взглянуть на Parsey McParseface. Решение с открытым исходным кодом, недавно выпущенное Google. И то, и другое, пожалуй, самое современное, и имеет действительно хороший обзор литературы в README,
Проблема с использованием синтаксических анализаторов на основе правил или общих методов на основе лексики заключается в том, что точность, которую вы собираетесь увидеть, действительно довольно низкая. Как правило, попытка использовать неконтролируемую технику - это быстрый путь, который в большинстве случаев приведет к сбою вашего алгоритма даже с немного нерегулярной грамматикой. Особенно, если грамматика вашего целевого языка, вероятно, со временем изменится, возможно, она имеет некоторую двусмысленность, которую вы не сможете объяснить с помощью системы, основанной на правилах.
Что касается общего восходящего подхода для реструктуризации ваших деревьев разбора, трудно сказать, является ли это правильным решением или нет. Это, конечно, довольно типичный подход для построения деревьев разбора, но качество передачи сильно зависит от домена, в котором вы работаете, размера вашего набора данных и грамматической структуры обоих языков. В конце концов, одним из больших недостатков машинного обучения является то, что никто не может сказать вам, сработает ли новый подход или нет с какой-либо определенностью.
Вы должны сделать это, оценить производительность в соответствии с соответствующей метрикой, а затем внести изменения, чтобы увидеть, улучшаете ли вы свою производительность. К сожалению, если у вас очень маленький корпус, вы вряд ли получите какой-либо высококачественный перевод в автоматическом режиме, просто не достаточно сигнала, но если вы используете стенограммы ООН в качестве учебного набора, вы можете в наименее обосновать свой фундаментальный подход по сравнению с литературой.