Какой правильный и хороший способ реализовать __hash__()?
Как правильно и правильно реализовать __hash__()?
Я говорю о функции, которая возвращает хеш-код, который затем используется для вставки объектов в хеш-таблицы, или словари.
Как __hash__() возвращает целое число и используется для "объединения" объектов в хеш-таблицы. Я предполагаю, что значения возвращаемого целого числа должны быть равномерно распределены для общих данных (чтобы минимизировать коллизии). Какая хорошая практика, чтобы получить такие ценности? Являются ли столкновения проблемой? В моем случае у меня есть небольшой класс, который действует как контейнерный класс, содержащий несколько целых, несколько чисел с плавающей запятой и строку.
8 ответов
Простой, правильный способ реализации __hash__() это использовать ключевой кортеж. Это будет не так быстро, как специализированный хеш, но если вам это нужно, вам, вероятно, следует реализовать тип в C.
Вот пример использования ключа для хэша и равенства:
class A:
def __key(self):
return (self.attr_a, self.attr_b, self.attr_c)
def __hash__(self):
return hash(self.__key())
def __eq__(self, other):
return isinstance(self, type(other)) and self.__key() == other.__key()
Также документация__hash__ имеет больше информации, которая может быть полезна в некоторых конкретных обстоятельствах.
Джон Милликин предложил решение, подобное этому:
class A(object):
def __init__(self, a, b, c):
self._a = a
self._b = b
self._c = c
def __eq__(self, othr):
return ((self._a, self._b, self._c) ==
(othr._a, othr._b, othr._c))
def __hash__(self):
return hash((self._a, self._b, self._c))
Проблема с этим решением состоит в том, что hash(A(a, b, c)) == hash((a, b, c)), Другими словами, хэш сталкивается с хэшем кортежа его ключевых членов. Может быть, это не имеет большого значения на практике?
Документация Python по__hash__ предлагает объединить хеши подкомпонентов, используя что-то вроде XOR, что дает нам это:
class B(object):
def __init__(self, a, b, c):
self._a = a
self._b = b
self._c = c
def __eq__(self, othr):
return (isinstance(othr, type(self))
and (self._a, self._b, self._c) ==
(othr._a, othr._b, othr._c))
def __hash__(self):
return (hash(self._a) ^ hash(self._b) ^ hash(self._c) ^
hash((self._a, self._b, self._c)))
Бонус: более надежный __eq__ брошен туда для хорошей меры.
Обновление: как указывает Blckknght, изменение порядка a, b и c может вызвать проблемы. Я добавил дополнительный ^ hash((self._a, self._b, self._c)) захватить порядок значений хэширования. Этот финал ^ hash(...) может быть удалено, если объединяемые значения не могут быть переставлены (например, если они имеют разные типы и, следовательно, значение _a никогда не будет назначен _b или же _c, так далее.).
Пол Ларсон из Microsoft Research изучил множество хеш-функций. Он мне это сказал
for c in some_string:
hash = 101 * hash + ord(c)
работал на удивление хорошо для широкого спектра струн. Я обнаружил, что подобные полиномиальные методы хорошо работают для вычисления хэша разнородных подполей.
Хороший способ реализовать хэш (а также список, словарь, кортеж) — сделать так, чтобы объект имел предсказуемый порядок элементов, сделав его итерируемым с помощью__iter__. Итак, чтобы изменить пример сверху:
class A(object):
def __init__(self, a, b, c):
self._a = a
self._b = b
self._c = c
def __iter__(self):
yield "a", self._a
yield "b", self._b
yield "c", self._c
def __hash__(self):
return hash(tuple(self))
def __eq__(self, other):
return (isinstance(other, type(self))
and tuple(self) == tuple(other))
(здесь
__eq__не требуется для хэша, но его легко реализовать).
Теперь добавьте несколько изменяемых элементов, чтобы увидеть, как это работает:
a = 2; b = 2.2; c = 'cat'
hash(A(a, b, c)) # -5279839567404192660
dict(A(a, b, c)) # {'a': 2, 'b': 2.2, 'c': 'cat'}
list(A(a, b, c)) # [('a', 2), ('b', 2.2), ('c', 'cat')]
tuple(A(a, b, c)) # (('a', 2), ('b', 2.2), ('c', 'cat'))
все разваливается, только если вы попытаетесь поместить нехешируемые элементы в объектную модель:
hash(A(a, b, [1])) # TypeError: unhashable type: 'list'
Очень хорошее объяснение того, когда и как реализовать __hash__функция есть на сайте программы:
Просто снимок экрана для обзора: (последнее посещение - 13 декабря 2019 г.)
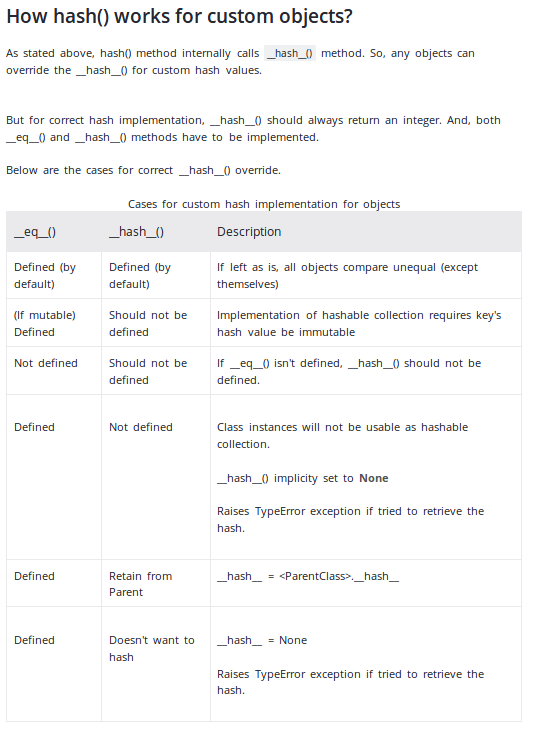
Что касается персональной реализации метода, вышеупомянутый сайт предоставляет пример, который соответствует ответу millerdev.
class Person:
def __init__(self, age, name):
self.age = age
self.name = name
def __eq__(self, other):
return self.age == other.age and self.name == other.name
def __hash__(self):
print('The hash is:')
return hash((self.age, self.name))
person = Person(23, 'Adam')
print(hash(person))
Я могу попытаться ответить на вторую часть вашего вопроса.
Коллизии, вероятно, будут вызваны не самим хеш-кодом, а отображением хеш-кода на индекс в коллекции. Так, например, ваша хеш-функция может возвращать случайные значения от 1 до 10000, но если ваша хеш-таблица содержит только 32 записи, вы получите коллизии при вставке.
Кроме того, я думаю, что коллизии будут разрешаться коллекцией внутри, и существует много способов разрешения коллизий. Простейшим (и худшим) является то, что с учетом записи, вставляемой по индексу i, добавляйте 1 к i, пока вы не найдете пустое место и не вставите туда. Поиск затем работает так же. Это приводит к неэффективным поискам для некоторых записей, поскольку у вас может быть запись, для поиска которой требуется пройти всю коллекцию!
Другие методы разрешения столкновений сокращают время поиска, перемещая записи в хэш-таблице, когда элемент вставляется для распределения объектов. Это увеличивает время вставки, но предполагает, что вы читаете больше, чем вставляете. Существуют также методы, которые пытаются разветвлять различные конфликтующие записи, чтобы записи кластеризовались в одном конкретном месте.
Кроме того, если вам нужно изменить размер коллекции, вам потребуется перефразировать все или использовать метод динамического хеширования.
Короче говоря, в зависимости от того, что вы используете для хеш-кода, вам может потребоваться реализовать собственный метод разрешения коллизий. Если вы не храните их в коллекции, вы, вероятно, можете воспользоваться хеш-функцией, которая просто генерирует хеш-коды в очень большом диапазоне. Если это так, вы можете убедиться, что ваш контейнер больше, чем он должен быть (чем больше, тем лучше), в зависимости от ваших проблем с памятью.
Вот несколько ссылок, если вы заинтересованы больше:
объединенное хеширование в Википедии
В Википедии также есть сводка различных методов разрешения столкновений:
Кроме того, " Организация и обработка файлов" Tharp охватывает множество методов разрешения коллизий. ИМО это отличный справочник по алгоритмам хеширования.
@dataclass(frozen=True)(Питон 3.7)
Эта замечательная новая функция, среди прочего, автоматически определяет__hash__и__eq__для вас, заставив его работать, как обычно, в dicts и set:
dataclass_cheat.py
from dataclasses import dataclass, FrozenInstanceError
@dataclass(frozen=True)
class MyClass1:
n: int
s: str
@dataclass(frozen=True)
class MyClass2:
n: int
my_class_1: MyClass1
d = {}
d[MyClass1(n=1, s='a')] = 1
d[MyClass1(n=2, s='a')] = 2
d[MyClass1(n=2, s='b')] = 3
d[MyClass2(n=1, my_class_1=MyClass1(n=1, s='a'))] = 4
d[MyClass2(n=2, my_class_1=MyClass1(n=1, s='a'))] = 5
d[MyClass2(n=2, my_class_1=MyClass1(n=2, s='a'))] = 6
assert d[MyClass1(n=1, s='a')] == 1
assert d[MyClass1(n=2, s='a')] == 2
assert d[MyClass1(n=2, s='b')] == 3
assert d[MyClass2(n=1, my_class_1=MyClass1(n=1, s='a'))] == 4
assert d[MyClass2(n=2, my_class_1=MyClass1(n=1, s='a'))] == 5
assert d[MyClass2(n=2, my_class_1=MyClass1(n=2, s='a'))] == 6
# Due to `frozen=True`
o = MyClass1(n=1, s='a')
try:
o.n = 2
except FrozenInstanceError as e:
pass
else:
raise 'error'
Как мы видим в этом примере, хеши вычисляются на основе содержимого объектов, а не просто на адресах экземпляров. Вот почему что-то вроде:
d = {}
d[MyClass1(n=1, s='a')] = 1
assert d[MyClass1(n=1, s='a')] == 1
работает, хотя второйMyClass1(n=1, s='a')это совершенно другой экземпляр от первого с другим адресом.
frozen=Trueявляется обязательным, в противном случае класс не может быть хеширован, в противном случае пользователи могут непреднамеренно сделать контейнеры несовместимыми, изменив объекты после того, как они будут использованы в качестве ключей. Дополнительная документация: https://docs.python.org/3/library/dataclasses.html .
Протестировано на Python 3.10.7, Ubuntu 22.10.
Зависит от размера возвращаемого хеш-значения. Это простая логика, что если вам нужно вернуть 32-битное целое число на основе хэша четырех 32-битных целых, вы получите коллизии.
Я бы предпочел битовые операции. Например, следующий псевдокод C:
int a;
int b;
int c;
int d;
int hash = (a & 0xF000F000) | (b & 0x0F000F00) | (c & 0x00F000F0 | (d & 0x000F000F);
Такая система может работать и для чисел с плавающей запятой, если вы просто примете их за битовые значения, вместо того, чтобы фактически представлять значения с плавающей запятой, может быть, лучше.
Что касается строк, у меня мало / нет идей.