Массовая загрузка в B-Tree
https://en.wikipedia.org/wiki/B-tree
В настоящее время я знаю 2 способа построения B-Tree: массовая загрузка и вставка ключа после ключа.
В примере вики ключи отсортированы, что является предварительным условием для массовой загрузки.
В чем преимущество массовой загрузки, если ключи не отсортированы? следовательно, я должен сортировать их сам, по-прежнему приводя к O(nlogn), так же, как вставлять ключ после ключа в B-Tree.
Благодарю.
2 ответа
Рассмотрим следующие сценарии:
- Если данные уже отсортированы, вам не нужно сортировать данные самостоятельно. Это может привести к загрузке O(n) (я не эксперт по массовой загрузке).
- Если дерево очень большое и хранится на диске или на нескольких машинах, то местность памяти может сыграть свою роль. Массовая загрузка позволяет избежать "загрузки" частей дерева в память перед добавлением чего-либо.
Разница между обычным, скажем, красно-черным деревом и 4-деревом заключается в гистерезисе; B-дерево резервирует пространство для будущего использования. Только когда у узла слишком много ключей, он разделяется пополам. Неэффективность возникает, когда ключи подают по порядку; то есть наполовину заполненные узлы, которые никогда не становятся заполненными, потому что каждый всегда добавляет к одной стороне.
Это пример 3-дерева (используя определение Кнута), в которое я вставил числа от 1 до 8 в порядке возрастания. Большая часть дерева находится в нижней части заполняемости. Ожидаемое значение количества узлов для доступа к данным равно 2,5.
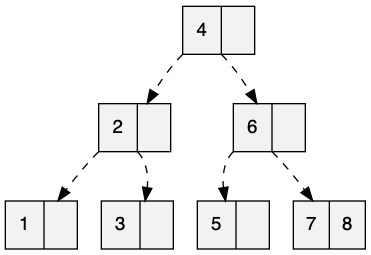
Массовая загрузка — это процесс, при котором мы игнорируем правила разбиения и упаковываем как можно плотнее, зная, что, возможно, у нас еще есть что -то еще . Это также помогает избежать ненужного копирования за счет, возможно, необходимости исправления дерева для восстановления инвариантов B-дерева справа. В этом я загрузил одни и те же данные.
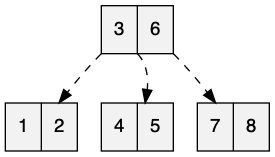
Хотя асимптотическое пространство и время выполнения одинаковы, вместо того, чтобы использовать чуть больше половины пространства, он использует почти все пространство. Таким образом, средняя стоимость поиска в этот момент меньше, ожидаемое значение 1,75. Это более полезно при загрузке большого объема данных, которые остаются относительно статичными.